 50.002 CS
50.002 CS
- Overview
- An Example of a Basic Programmable Control System
- The Von Neumann Model
- The Beta Instruction Set Architecture
- High Level language, Assembly Language, and Machine Language
- Preview: The \(\beta\) CPU
- Summary
- Appendix
50.002 Computation Structures
Information Systems Technology and Design
Singapore University of Technology and Design
Designing an Instruction Set Architecture
You can find the lecture video here. You can also click on each header to bring you to the section of the video covering the subtopic.
Detailed Learning Objectives
- Define a Basic Programmable Machine
- Discuss the requirements for a machine to be programmable, including expandable memory, a rich repertoire of operations, and the ability to execute newly generated programs.
- Explain Datapath
- Identify components of a datapath, which consist of combinational devices, registers, and buses, and their role in processing inputs to produce outputs within a machine.
- Identify the Role of Control Signals in Machine Operations
- Explain how control signals influence the behavior of circuits in a programmable machine, allowing for varied operations across different time steps.
- Examine the Functionality of Control FSM Units
- Analyze how different Control FSM (Finite State Machine) units can alter a machine’s operations, making it programmable through variable control signal sequences without the need to modify the hardware.
- Discuss the Constraints of Simple Programmable Machines
- Evaluate the limitations of basic programmable machines in terms of storage capacity, operation diversity, and self-programming capabilities.
- Describe the Von Neumann Architecture
- Explain the general structure and components of the Von Neumann architecture, including the CPU, memory unit, and input/output mechanisms, and how they integrate via data/address buses.
- Formulate common CPU’s Components and Functions
- Explain the internal structure of a CPU, including its data path, control unit, ALU, and internal storage, and how these components interact to execute instructions.
- Examine the Memory Unit’s Role and Functions
- Explain the functionality of memory units in storing data and instructions, how data is organized and accessed, and the concept of byte-addressable memory.
- Recognize Instruction Set Architectures
- Justify the importance of an ISA in defining the operations a CPU can perform, and how it facilitates the programming of a computer to perform a wide range of tasks.
- Translate Between High-Level Languages and Machine Language
- Explain the process of translating high-level programming languages into assembly and then into machine language, emphasizing the role of compilers and interpreters.
These objectives guide students through understanding the foundational concepts of programmable machines, their architectural designs, and the transformation of high-level programming constructs into executable machine code.
Overview
To create a programmable control system suitable for general purposes (like the Universal Turing Machine), we need to define a set of instructions for that system, such that it is able to support a rich repertoire of operations.
We can create a machine that is simply programmable, but it also has to support the following features for it to resemble the Universal Turing Machine:
- An expandable memory unit (to represent that infinite tape)
- A rich repertoire of operations
- Ability to generate a new program and then execute it
We will begin by understanding what does it mean to simply create a (basic) programmable machine, and how the current general-purpose computer model is both programmable and possess these three features.
An Example of a Basic Programmable Control System
Suppose we have a simple sequential logic circuit called Machine \(M\) as shown below. It receives one \(N\) bit input, and produces two output: \(N\) bit output1 and 1 bit output2. Formally, we call this “circuit” a datapath.
Datapath
A datapath is a collection of hardware elements needed to manipulate, store, and transfer data between different parts of the system. The datapath works in conjunction with a control unit, which orchestrates the operations of the datapath based on the instructions being executed.

Drawing Convention
Note that since the machine receives \(N\) bit inputs, it means that there are \(N\) units of each 2-to-1 multiplexers in parallel, as shown:
The registers (DFFs) also are actually
N1-bit registers:In diagrams they are only drawn once, but you can differentiate between a single wire (that carries 1-bit of information) with a bunch of wires that carry \(>1\) bits of information by the forward slash
/symbol.


In this example, Machine \(M\) also has four control signals, symbolised as \(\text{A}_{\text{SEL}}\), \(\text{B}_{\text{SEL}}\), \(\text{A}_{\text{LE}}\), and \(\text{B}_{\text{LE}}\). These four control signals are dictated by a control FSM unit shown below, meaning that these four signals will vary accordingly at each time step, hence changing the behaviour of the circuit above when we need it:

R1 and R2 units are not a regular dff. They accept an additional control signal, denoted as LE. These control signals \(\text{A}_{\text{LE}}\), \(\text{B}_{\text{LE}}\) fed to R1 and R2 unit works as follows:
- If \(\text{A}_{\text{LE}}\) is
1, then the current input to R1 will be reflected as R1’s output in the next clock cycle. It’s like “enabling” the R1, allowing it to “remember” new value. - If \(\text{A}_{\text{LE}}\) is
0, then R1 will continue to produce it’s old value as an output, whatever last value it was remembered when \(\text{A}_{\text{LE}}\) was1some time in the past. When \(\text{A}_{\text{LE}}\) is0, new values at the input node of R1 will be ignored.
The detailed anatomy of R1 and R2 units are similar to this section in your next lecture. The WERF signal in your Beta CPU is analogous to these register’s LE signals.
Other notable components of \(M\):
- A decrement unit symbolised as
-1 - Computation of
z = (input == 0) ? 1 : 0 - A multiplier unit symbolised as
*
Control FSM A
Control FSM
We can control the processing of inputs at each time-step (clock cycle) with a (plugged in) Control FSM unit.
If we can load another Control FSM unit that also produces these four signals but in different sequences, then we allow machine \(M\) to be programmable. The complete circuit after plugging in a Control FSM unit is as shown:

For example, let’s say we have Control FSM unit type \(A\) that has the following functional specifications (its starting state is \(S_0\)):
\[\begin{matrix} S_i & S_{i+1} & A_{SEL} & A_{LE} & B_{SEL} & B_{LE}\\ \hline S_0 & S_1 & 1 & 1 & 0 & 1\\ S_1 & S_2 & 0 & 1 & 1 & 1\\ S_2 & S_3 & 0 & 1 & 0 & 0\\ S_3 & S_3 & 0 & 0 & 0 & 0\\ \hline \end{matrix}\]This specification allows Machine \(M\) to be able to compute \(\text{Input}\times(\text{Input}-1)\) at the \(4^{th}\) clock cycle, counted from the moment stable input is fed; assuming this is the first cycle t=0. The output (true answer) will be ready at the output1 port at t=3 later after feeding in the input to the machine.
Think!
Take some time to analyse the datapath by running it with some small input value, e.g: Let \(N=6\) and Input = \(5\) =
000101(in 6 bits). So for example, at \(t=0\) we know that Input \(=5\) and \(S_{t=0} = S_0\).Ask yourself:
- What is the value of “Output 1” and \(S_{t=1}\) at \(t=1\)?
- Has “Output 1” contained the answer at \(t=1\)?
- What about at \(t=2\)?
- Confirm at which timestep \(t\) will we have the correct value of \(\text{Input}\times(\text{Input}-1) = 5\times 4 =20\) =
010100at “Output 1” port?
Another Control FSM B
Now let’s say we have another control FSM unit \(B\) that has the following functional specifications with starting state \(S_0\) (Note: “\(--\)” means “does not matter”):
\[\begin{matrix} Z & S_i & S_{i+1} & A_{SEL} & A_{LE} & B_{SEL} & B_{LE}\\ \hline -- & S_0 & S_1 & 1 & 1 & 0 & 1\\ 0 & S_1 & S_1 & 0 & 1 & 1 & 1\\ 1 & S_1 & S_2 & 0 & 1 & 1 & 1\\ -- & S_2 & S_2 & 0 & 0 & 0 & 0\\ \hline \end{matrix}\]Programmability
These control FSMs carries different specifications that allow Machine \(M\) to be able to compute \(\text{Input}\) factorial and produce it at the “Output 1” port on after certain time steps. Similarly, take some time to analyse the datapath by running it with some small input value, e.g: Let \(N=2\) and Input \(=3\) = 11 (in 2 bits), and find out how long it takes to produce the correct output: \(3! = 3\times 2 =6\).
The programmability feature of machine \(M\) allows us to reuse datapaths to solve new problems. However machine \(M\) cannot be called a general purpose computer because:
- It has very limited storage: it can only read input of \(N\) bits, whatever that is being fed in.
- It has a tiny repertoire of operations: \(\text{Input}\) factorial and \(\text{Input}\times(\text{Input}-1)\).
- It is unable to generate a new program and execute it. We need to replace the entire Control FSM unit for it to be able to be “reprogrammed”. In other words, theres no basic instruction set that can be used as building blocks to create a more complex programs to control it.
Now it is clear that what we need to do to create a general-purpose computer is to:
- Design a general purpose data path, which can be used to efficiently solve most problems, and
- Design a proper instruction set to allow for easier ways to control it.
The Von Neumann Model
Many architecture approaches to a general-purpose computing device have been explored (see others here), but the Von Neumann Model is one where most modern and practical computers are based on.

The generic anatomy of a Von Neumann architecture is shown above. The four main components of the model are:
- Central Processing Unit (CPU): the “brain” of the computing device, made up of several registers as internal storage, as well as combinational logic units for performing a specified set of operations on their contents.
- Memory Unit: external storage of data and programs that can be loaded onto the CPU and executed
- Input/Output: Devices for communicating with the outside world.
- Data/Address Bus that connects all components of the machine together.
The Basic Anatomy of a Central Processing Unit
The CPU is a part of the computer that executes instructions. A series of these executable instructions is called a computer program.
Before building a CPU, one usually design a figurative blueprint for how the CPU operates and how all the internal systems interact with each other. This blueprint is called the Instruction Set Architecture. There many different types of ISAs a CPU can be built on. Some of the common ISA families are x86 (found in desktops and laptops) and ARM (found in embedded and mobile devices).
A basic anatomy of the CPU is shown below, consisted of four major components: the Data Path, Internal Storage called REGFILE, consisted of many Registers (e.g: D Flip-Flops), the Arithmetic Logic Unit (ALU), and a Control Unit (FSM).

The CPU is essentially the “brain” of the computing device. It is be able to:
- Load a series of instructions (from the Memory Unit),
- Produce the corresponding control signals, hence effectively “executing” that loaded instruction using the combinational logic unit (the ALU).
- And store them in its (limited capacity) internal storage (registers).
- It is also capable of directing the computed output back to the Memory Unit for longer storage.
CPU Datapath
The Datapath is an overarching infrastructure to control what input goes to each component, and where the output of each component in the CPU goes to.
CPU CU
The Control Unit is made of a program counter (PC) and a control unit (CU). The job of a PC is to read an instruction (at a time) from the Memory Unit, so that the CPU can execute it. The CU gives us the control signals based on that current instruction read. These signals control the datapath and enable us to route data to the appropriate components stated in the instruction.
CPU ALU
The Arithmetic Logic Unit performs the “work” – computing basic functions such as addition, comparison, boolean, shifting, and multiplication.
A simple analogy of a CPU
A great explanation quoted from this source: “You may imagine a CPU as a train car.”
“The engine is what moves the train, but the conductor is pulling the levers behind the scenes and controlling the different aspects of the engine.
A CPU is the same way. The datapath is like the engine and as the name suggests, is the path where the data flows as it is processed. The datapath receives the inputs, processes them, and sends them out to the right place when they are done.
The control unit tells the datapath how to operate like the conductor of the train. Depending on the instruction, the datapath will route signals to different components, turn on and off different parts of the datapath, and monitor the state of the CPU.”
The Memory Unit
The CPU is able to read and write bits of data to and from a memory unit connected to it – an expandable storage device (we know it as RAM in practice). As the name suggests, this device does NOT execute or compute anything, it simply retains (store) information.
The “data” that is stored in this expandable resource pool is not just simply data, i.e: images, videos, documents, addresses etc, and also instructions that make up a program. This is where your instruction resides when it is about to be executed by the CPU. To the eyes of the Memory Unit, they’re all just data.
The bigger the size of your memory unit, the more data you can store within it. We usually know this as RAM commercially, and we will have them in the size of 8GB, 16GB, or 32GB in modern computers (at least in 2022 when this document was written).
Memory Addressing Convention
Since the memory unit can store a huge amount of data (in Gigabytes), the CPU must be able to read just a particular \(N\) bits of relevant data from the memory unit. It is able to do this by giving an address as an input to the memory unit. The memory unit receives this address and output the data stored at the given address.
To write onto or read from the memory unit, the CPU must provide two inputs to the Memory Unit:
- Address: the address where this \(N\) bits of data should be stored or loaded from
- Content: the data itself.
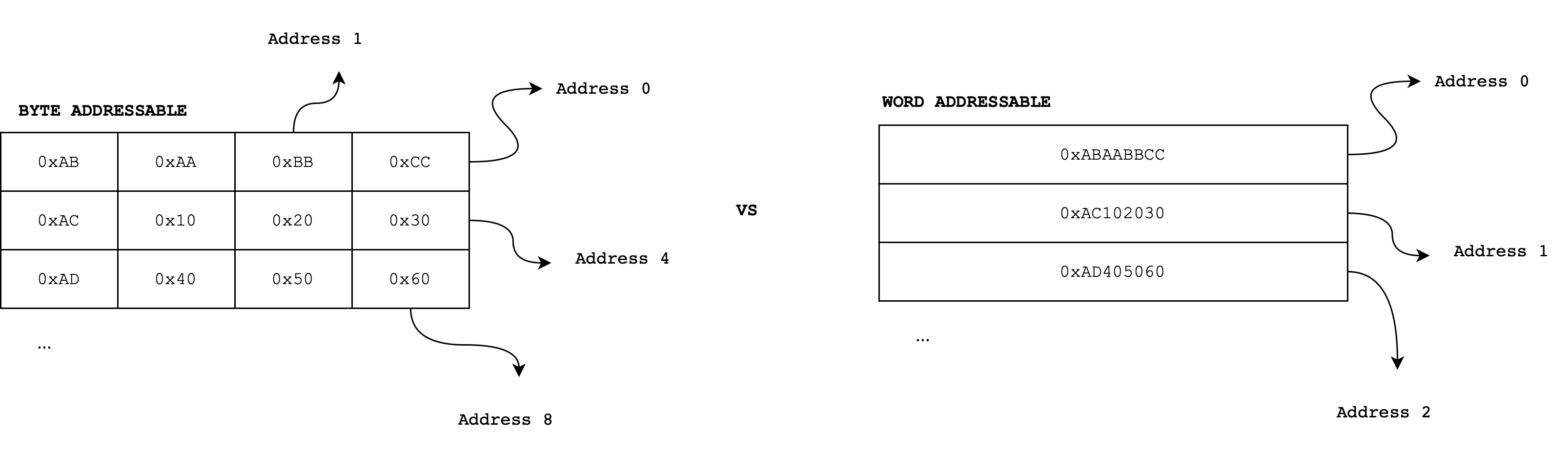
The memory device generally receives three kinds of input, 1-bit WE signal (write enable), address, and data input (bit size varies, depending on how much data can the memory holds). The figure below illustrate a byte addressable memory unit where \(N\) is 8 bits.

We will learn more about detailed anatomy of the memory unit later on, but for now we can think of it as a device that can store a huge amount of data, separated into addressable segments that can hold \(N\) bit of data each The value of \(N\) is typically 8 bits (1 byte) unless otherwise stated. The figure below shows two separate cases of the same memory content, when \(N=8\) (byte addressable) and when \(N=32\) (word addressable).
Memory unit (RAM) is a storage “facility”
Think of a memory unit as similar to a storage facility that has a large amount of storage units. Each unit has the same volume, and it can store a bunch of objects in it. People usually can rent these units to place their belongings.
If we rent such unit, we are typically given an address – some kind of index to identify the unit that is ours. The \(N\)-bit data is the “object” that we put in a storage unit (addressable segment), and the memory address is the identifier of the storage unit location where the data is held.
Capacity
Think!
What is the maximum amount of bits that a memory unit can store with \(32\) address bits?
In the figure above, each row contains \(4\times8\) bits in total \(=32\) bits. We call a block of 32 bits as a word because we will be learning about 32-bit CPU architecture. Since the memory unit is commonly byte addressable, a 32-bit word has four addresses. By convention, we select the smallest of the four addresses to be the overall address of the word.
- The first word (in the first row), has address
0x0000. - The subsequent word in the second row has address
0x0004, and so on. - Each subsequent word has their addresses increased by 4.
The size of a WORD actually may depend on the ISA. The computer model that we learn for this course is a 32-bit architecture, therefore we define 1 WORD to be 32 bits.
Programmability of a Von Neumann Machine
We can clearly see how electronic devices that are designed based on this model is programmable (i.e: a close physical manifestation of a Universal Turing Machine).
The Memory Unit represents the “tape” of the Universal Turing Machine, while the CPU is the “arrow” that performs the logic computation and perform read/write to the memory. Both “input” and “program” (instructions) can be stored in the memory unit. We can never have an infinitely huge RAM, but we can get really large RAM, that’s close enough.
The CPU is a complex sequential logic circuit: a datapath whose job is to fetch and execute instructions loaded from the memory, one instruction at a time per clock cycle.
The Control Unit provides different control signals depending on the current instruction read. This allows us to reuse the same data paths for computing a set of different functions – or in other words: provide programmability. Programmable data paths give some algorithmic flexibility, achievable by just changing the control structure.
What are these “instructions”?
How do we design an instruction set that makes for a general purpose programmable device? Designing an instruction set is a mix of engineering and art: we need to design an instruction set that is compact, uniform, versatile, fast, and so on. The solution is simple: trial by simulation (try and error!) is our best technique for making choices.
In this course, we will learn the \(\beta\) instruction set – an instruction set architecture (ISA).
ISA
An ISA is a CPU blueprint that defines an abstract model of a general-purpose computer. It specifies many crucial information that describes how a CPU should work, such as what instructions the CPU can process, how it interacts with the memory unit, the basic CPU components, instruction formats, and many more.
Its implementation: the \(\beta\) CPU, is a 32-bit Von Neumann-based toy CPU created by MIT as a teaching tool to introduce students to programmable datapaths and instruction sets, among all others. We can write any algorithm using a mixture of \(\beta\) instructions. The CPU can emulate any machine behaviour that we want by executing it. This architecture is very similar to other RISC-based architectures that’s gaining popularity as of 2024, so don’t worry: you’re not learning obsolete things.
Modern ISAs (e.g: ARM, x86) and its corresponding CPU architecture is certainly much more complex than the \(\beta\), however the \(\beta\) is more than sufficient for us to understand and appreciate the basic concepts of programmable datapath and instruction sets. Some notable ISA in the past are 6502, AVR, and 32-bit x86.
The Beta Instruction Set Architecture
Recall that in order for a machine to be programmable (used for general purpose), we need to design a set of well-defined operations (supported functions that can be computed), that the machine should support. These operations can be used to form a larger – more complex program that if executed, allows the machine to emulate the behavior of another program.
Beside defining the machine’s operation types, the ISA should also define the supported data types, the registers (How many internal registers are there? How to address them? etc), and various other fundamental features such as addressing mode, input and output, and many more.
\(\beta\) ISA Format
Each instruction that the \(\beta\) supports is written in a specific encoding. There are in total of 32 distinct operations/instructions that the \(\beta\) should be able to execute, each having its own operation encoding (OPCODE).
Read the manual!
The complete documentation on each instruction in detail can be found here.
All instructions have the same characteristics:
- Each instruction is encoded into 32-bits of information.
- Only one instruction is executed in each clock cycle. Each instruction is considered atomic and is presumed to complete before the next instruction is executed.
\(\beta\) Machine Model
The \(\beta\) is a general-purpose 32-bit architecture. All registers are 32 bits wide. There are 33 registers in total (in the entire CPU):
- The PC register: contains the address of the CURRENT instruction that is executed by the CPU.
- When loaded with an address, it can point to any location in the byte-addressable memory.
- The memory unit returns the instruction (32-bit data) stored at this address for the CPU to decode and execute.
- The REGFILE registers (internal storage in CPU): contains 32 registers in total (and each register is 32 bits wide), addressable with 5 bits to identify
R0toR31respectively.- All registers except
R31can be read or written with new values. - For
R31: when read, it is always 0; when written, the new value is discarded.
- All registers except
In register transfer language, the content of register with address A is often denoted as : Reg[A]. The symbol Rx refers to the address of a particular register x in the REGFILE. The symbol Reg[Rx] refers to the content of that register.
Its machine model is summarised in the figure below:

The Memory Unit (main memory) can also be referenced through LOAD and STORE instructions that perform no other computation. The target memory address should be stored in a register in the REGFILE.
\(\beta\) Instruction Encoding
There are only two types of instruction encoding: Without Literal (Type 1) and With Literal (Type 2). All integer manipulation is between registers, with up to two source operands (one may be a sign-extended 16-bit literal), and one destination register.
- Instructions without literals (Type 1) include arithmetic and logical operations between two registers whose result is placed in a third register.
- Instructions with literals (Type 2) include all other operations and instruction literals is represented in two’s complement.
The figure below shows the two types of \(\beta\) instruction encoding:

The 32-bit instruction I is segmented to various sections.
OPCODE
The OPCODE = I[31:26] is 6 bits long. The OPCODE signifies different types of operation. They are summarised in the table below:

Rc, Ra, Rb (Type 1)
For Type 1 instruction (without literal), we have these three segments: Rc = I[25:21], Ra = I[20:16], and Rb = I[15:11], each 5 bits in length, to signify the target address of the registers in the REGFILE. The last 11 bits are unused.
Rcis the destination register to write output to.Ra, andRbcontain the source data
Rc, Ra, c (Type 2)
For Type 2 instruction (with literal), we have these three segments: Rc = I[25:21], Ra = I[20:16], and c = I[15:0].
Rcis the destination register to write output to.Racontains the source data.cis a 16-bit signed constant or literal.
The reason for this Type 2 instruction is that some operations require a constant instead. For example, we want to add the content of register Ra with a constant c \(= 4\), the equivalent Python code of:
x = x + 4
The instruction above can be implemented using Beta Type 2 instruction, where we can encode the number 4: c=0000 0000 0000 0100 as the last 16 bits of the instruction.
Example: Constant Addition
Suppose we have following 32-bit instruction: \(I=\)110000 00011 00001 1111111111111101 and we want to know what it does.
By referring to the \(\beta\) documentation, and we can find that first 6 bits corresponds to the OPCODE: ADDC (Type 2). We have to segment the instructions: Rc = I[25:21] = 3, Ra = I[20:16] = 1, and c = -3.
ADDC does the following:
- To add the content of Register
R1withc = -3 - And store it in Register
R3 - Increase the content of PC by 4
- In register transfer language:
PC\(\leftarrow\)PC+4Reg[Rc]\(\leftarrow\)Reg[Ra]+SEXT[c]
Since c is 16 bits, it has to be sign-extended (SEXT) to be 32 bits before added with the content of Ra. Reg refers to the REGFILE and Reg[Rx] means the content of register addressed as Rx in the REGFILE. We end up with c=0xFFFFFFFD.
Hence the instruction above is equivalent to the python code:
x = x - 3
Example: Memory STORE
Now suppose we have the following 32-bit instruction: \(I=\)011001 01001 00011 0000000000001000 By referring to the \(\beta\) documentation, and we can find that first 6 bits corresponds to the OPCODE: ST (Type 2).
Now we have to segment the instructions: Rc = I[25:21] = 9, Ra = I[20:16] = 3, and c = 8.
ST does the following:
- To store the content of
Rcto the memory unit - In address: content of
Ra+c - In register transfer language:
PC\(\leftarrow\)PC+4EA\(\leftarrow\)Reg[Ra]+SEXT[c]Mem[EA]\(\leftarrow\)Reg[Rc]
The instruction above means: to store the content of register R9 into the memory address (EA): content of register R3 + 8
EA means effective address. Mem[EA] refers to the content of the Memory Unit at address EA. Again c is sign extended to form 32 bits: 0x00000008.
Hence the instruction above is almost equivalent to the python code:
x = 20 # an int, which value 20 is stored at register R9 for example
arrayList = [32, 11, 19] # an array, which address is stored at register R3
# each element in arrayList is an integer, which takes up 32 bits.
# hence, the first element of arrayList has an address of Reg[R3]
# the second element of arrayList has an address of Reg[R3] + 4
# the third element of arrayList has an address of Reg[R3] + 8
arrayList[2] = x # store 20 as the third element of arrayList
It is imperative that you read the beta documentation up until page 12, to understand all 32 basic instructions of the \(\beta\) machine individually before proceeding to the next chapter. In the next few weeks, we will take this knowledge to the next level as you learn how to hand assemble C-language into this low-level machine language.
High Level language, Assembly Language, and Machine Language
We usually write programs using higher level language such as Python, Rust, Ruby, C/C++, Java, Javascript, C# and so on. However, our machines do not understand these languages directly. The human-friendly, intuitive high-level programming syntaxes are ultimately just a bunch of ones and zeros stored inside the machine.
Our high level languages, are first translated into assembly language, before further converted into machine language in its binary form.
For example, we can write the following in C:
int x = 3;
x = x + 10;
The compiler (GCC, for example) compiles the code above and translate it into the appropriate assembly language. Suppose we are running it on a \(\beta\) machine and that the compiler supports it, the code above will be translated into \(\beta\) assembly as an intermediate step:
LDR(x, R0)
ADDC(R0, 10, R0)
ST(R0, x) | Note this is a "macro" for ST(R0, x, R31). You'll learn "macro" in later parts.
x : LONG(3)
Finally, it will be converted into \(\beta\) machine language, 32-bit for each line of assembly code. We may know this as an “ executable”, that is a piece of information that is directly “understandable” by the machine without the help of an intemediary translator anymore like a compiler/interpreter, or an assembler:
011111 00000 11111 0000 0000 0000 0010
110000 00000 00000 0000 0000 0000 1010
011001 00000 11111 0000 0000 0000 0000
0000 0000 0000 0000 0000 0000 0000 0011
The sample applies for when you write your program in Python. First, you must install Python interpreter for your machine: be it x86-64 or arm64 versions. This interpreter will translate the high-level Python language into an appropriate machine language that can be run on your computer hardware.
Abstraction
The programmers who wrote
GCCor Python interpreter must be aware of the ISA which these compiler/interpreter is intended to run on, but we as a high-level programmer doesn’t need to care too much about the ISA. That’s the beauty of abstraction.In the past, we don’t have too many of these advanced compilers and interpreters (translators to our high-level programming language). We’d have to write in assembly language too. For instance, MIT programmers wrote thousands of lines of esoteric assembly code for the Apollo Guidance Computer (AGC) to run in 1960, which took America to the moon. Please give this article a quick read, it really is eye opening.
The difference between each type of languages is obvious.
- Firstly, it is nearly impossible to directly code in binary format, and much more convenient to code using the higher language.
- Secondly, converting from high level language to assembly language is a little bit more complex (and not unique, meaning that there are many ways to translate the high level language to the assembly language that still results in the same output) than to convert from assembly to the machine language.
Don’t worry yet as of now. What we need to know (and get familiar with) is simply how to do this task: given a 32-bit machine language, write the corresponding assembly instruction and explain how it works (and vice versa).*
Preview: The \(\beta\) CPU
The \(\beta\) CPU falls under the family of RISC (reduced instruction set computing) processor. This type of computer processor possesses a small but highly optimised set of instructions, and are currently used for smartphones and tablet computers, among other devices.
The full anatomy of the (general-purpose) \(\beta\) datapath is shown in the Figure below. Remember that this is an implementation of the \(\beta\) instruction set architecture (i.e: its abstraction). This circuitry is therefore able to execute any \(\beta\) instruction as intended within a clock cycle.
The details of the \(\beta\) datapath will be explained in the next chapter, so that you have a complete understanding on how the datapath allows the working of each of the 32 instruction sets.
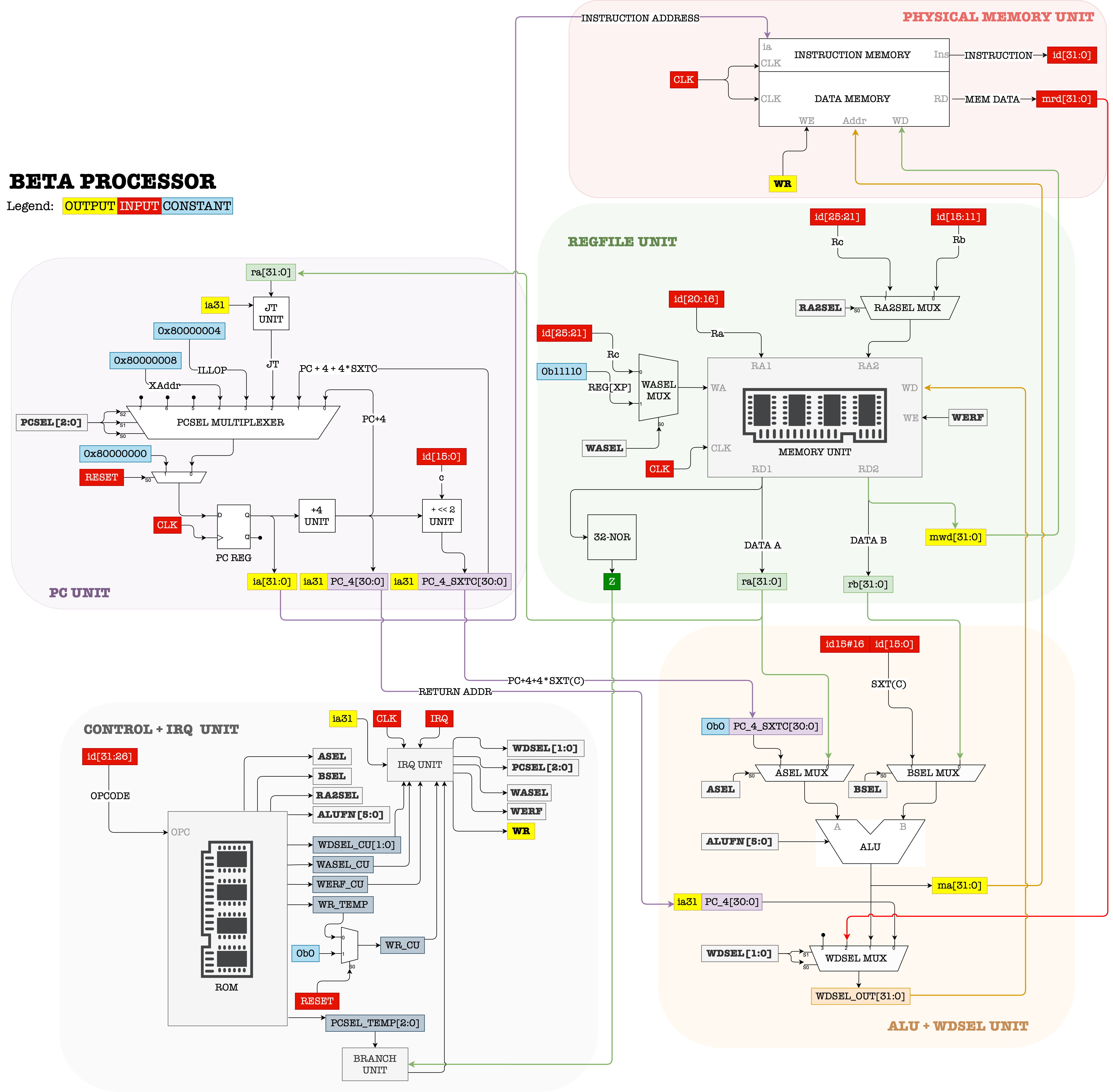
As of right now, we just need to understand the big idea of the \(\beta\) ISA , and how the \(\beta\) CPU realises it (give it a physical form and implementation):
- The PC (program counter) is a part of the CPU that in theory, fetch one instruction (set to be 32-bit in length) from the Memory Unit per clock cycle.
- The
OPCODEpart of the instruction is processed by the Control Logic unit, and appropriate control signals are produced. - The combination of these control signals reprogram the datapath so that we can reuse it to execute different types of instruction.
- The other parts of the instruction:
Rb,Ra,Rcorc, tells us which registers in the REGFILE to use for this instruction. - Step 1-4 are repeated for each clock cycle, and each instruction is atomic.
The \(\beta\) CPU hardware is therefore designed so that it can implement the \(\beta\) ISA, and therefore we can give an actual physical form (of a machine) that is programmable and able to execute each defined \(\beta\) instruction correctly as intended.
Summary
You may want to watch the post lecture videos here:
In the beginning of this chapter we were given the programmable Machine \(M\), that is capable of computing the simple factorial function. We then proceeded by arguing that Machine \(M\) is not enough to be used for a general purpose machine, that is to be used as an implementation of a Universal Turing Machine.
Programmability in computing hinges on the design of an instruction set architecture (ISA), which acts as a critical interface between hardware and software. A well-designed ISA ensures flexibility, enabling the hardware to efficiently execute diverse programs while providing developers with a clear and manageable set of operations for programming.
To create a general-purpose computer, we need to:
- Design a general-purpose data path (architecture) that can process a wide variety of instructions and handle diverse computational tasks efficiently. This includes defining components like the arithmetic logic unit (ALU), registers, memory hierarchy, and buses.
- Design an appropriate instruction set architecture (ISA) to serve as the interface between software and hardware. The ISA should provide a versatile and efficient set of instructions to control the data path and perform computations effectively. A well-designed ISA enables programmability and optimizes performance, power consumption, and hardware simplicity.
The \(\beta\) ISA and its implementation, the \(\beta\) CPU fulfils both requirement. If used to execute proper instruction, it should be able to emulate what Machine \(M\) is able to do.
Here are the key points from this notes:
- General-purpose Programmability: The Beta ISA (designed as a RISC-like architecture) serves as a blueprint that defines a set of operations enabling the Beta machine to execute or simulate a wide variety of programs, embodying the core principle of programmability in modern computing.
- Instruction Characteristics: Each instruction in the Beta ISA is encoded into 32-bits and executed atomically: one instruction per clock cycle, which emphasizes efficiency and simplicity in processing.
- Register and Memory Model: The architecture includes 33 registers (32 regs in regfile and the PC reg), each 32 bits wide, and a memory unit that interacts through specific instructions like load and store. This model underpins the handling of data and instructions in a systematic and accessible manner.
- Instruction Encoding: Two main types of encoding are detailed—Type 1 (without literals) for direct register operations, and Type 2 (with literals) for operations involving constants. This distinction helps in optimizing the instruction set for various computational needs.
- Practical Application: Finally, we stress the importance of understanding the Beta documentation thoroughly to effectively utilize these concepts in designing and implementing low-level machine language programs.
Appendix
Memory Unit Convention
Below are the list of conventions that explain why we illustrate the memory unit as above.
- We illustrate the memory unit to have four segments per row. This is only for illustration purposes, so that we can read them on paper more easily. In practice, it doesn’t matter how you physically arrange the segments.
- Each segment can contain exactly 8 bits of data (1 byte) – this is done by convention.
- Each segment of 8 bits (1 byte) is addressable. Therefore we say that by convention, data in the memory unit is byte addressable. You can have memory units that are word addressable as well. The same logic applies.
- In each row (series of 4 segments), lower addresses are written on the right, and higher addresses on the left (hence address 0 is given for the most upper right segment and so on).
- Each row contains \(4\times8\) bits in total \(=32\) bits.
- A memory unit typically receives \(N\) bits of data input. Similarly, it typically outputs \(N\) bits of data at a time, where \(N=32\) or \(N=64\). In this course, we will learn a 32-bit toy architecture (called the \(\beta\)) and therefore we will always \(N=32\). Therefore we will illustrate the memory unit to always have four 8-bit segments per row in this course – because it receives input or produce output in chunks of 32-bit data at time. Modern computers in the 21st century typically adopt the \(64\) bit architecture (so we have 64-bit words for these architecture) .
- The number of bits that can be received in ADDR input port is either fixed (also 32 bits for this course) or depends on how many bits are needed to address all the segments in the memory unit. For example, if we have a memory unit of size \(128\) KiB = \(128 \times 1024 = 131072\) bytes, we need at least \(\log_2(131072) = 17\) address bits. It is alright to receive more address bits.
Programming Factorial for the \(\beta\) CPU
So how do we write the code to do factorial in a way that \(\beta\) CPU can execute?
Suppose we have the simple factorial program written in \(C\).
Unlike in Python, in C we cannot write standalone instructions without declaring a function. We will learn function linkage procedure in Week 9. For now to simplify, assume that instructions below are part of some pre-defined function in some .c script.
int n = 9; // or 10, or 11, any constant
int ans;
int r1 = 1;
int r2 = n;
while (r2 != 0){
r1 = r1 * r2;
r2 = r2 - 1;
}
ans = r1;
This can be (hand) assembled into \(\beta\) assembly language:
.include beta.uasm
ADDC(R31, 1, R1) | R1 = 1
LD(n, R2) | R2 = n
loop:
BEQ(R2, done, R31) | while (R2 != 0)
MUL(R1, R2, R1) | R1 = R1 * R2
SUBC(R2, 1, R2) | R2 = R2 -1
BEQ(R31, loop, R31) | Always branches!
done:
ST(R1, ans, R31) | ans = R1
HALT()
n: LONG(9)
ans: LONG(0)
Of course then the final step is to convert this into machine language and load it to the Memory Unit, and allow the PC of the \(\beta\) machine to execute the first line of instruction (ADDC) .
To see how the code works in person, download bsim.jar from here, paste the assembly code above and run it.

When the machine halts, we should have the answered stored somewhere in the memory unit, thus effectively enabling \(\beta\) machine to emulate the ability of Machine \(M\) without changing its datapath. We will learn more about how to hand assemble and manually execute the code soon. Right now, this is here to give you a preview of what is to come in the next few weeks.