 50.005 CSE
50.005 CSE
- Threads
- Multithreading Benefits
- Multithreading vs Multiprocessing
- Thread Examples: Java and C pthread
- Types of Threads
- Thread Mapping
- Intel Hyper-Threading
- Multicore Programming
- Amdahl’s Law
- Summary
- Appendix
50.005 Computer System Engineering
Information Systems Technology and Design
Singapore University of Technology and Design
Natalie Agus (Summer 2025)
Threads
Detailed Learning Objectives
- Discuss the Basics of Threads
- Define a thread as a segment of a process, and recognize that every process has at least one thread.
- Identify the components of a thread: thread ID, program counter, register set, and stack.
- Justify how threads within the same process share the same address space and resources like code, data sections, and system resources.
- Explain how threads can execute the same or different parts of the process code concurrently.
- Explain Multithreading Benefits
- Explore how multithreading can improve the responsiveness of applications by allowing continued operation even if part of the application is blocked.
- Discuss the efficiency of resource sharing among threads compared to processes, highlighting the reduced overhead in creating and switching contexts between threads.
- Explain the Differences between Multithreading vs. Multiprocessing
- Compare the concurrency and protection aspects of processes versus threads.
- Analyze the communication, parallel execution, and synchronization differences between using multiple processes and multiple threads.
- Distinguish Different Types of Threads and Their Management
- Differentiate between user-level threads and kernel-level threads.
- Examine how each type of thread is scheduled, the level of overhead involved, and the implications for parallel execution on multicore systems.
- Justify thread mapping models like many-to-one, one-to-one, and many-to-many, and discuss their advantages and disadvantages.
- Experiment with Practical Implementation of Threads
- Implement threads in Java using Runnable interfaces and by extending the Thread class.
- Use the
pthreadlibrary in C to create, manage, and synchronize threads.- Evaluate Performance in Multithreaded Applications
- Compute amount of speedup possible in multicore programming using Amdahl’s Law
- Compute the fraction of the application that can be parallelized and the diminishing returns of adding more processing cores.
These objectives are structured to provide a comprehensive overview of multithreading, highlighting its advantages, challenges, and practical applications in programming.
Threads are defined as a segment of a process. A process has at least one thread.
A process can have multiple threads, and we can define thread as a basic unit of CPU utilization; it comprises of:
- A thread ID,
- A program counter,
- A register set, and
- A stack.
A thread can execute any part of the process code, including parts currently being executed by another thread.
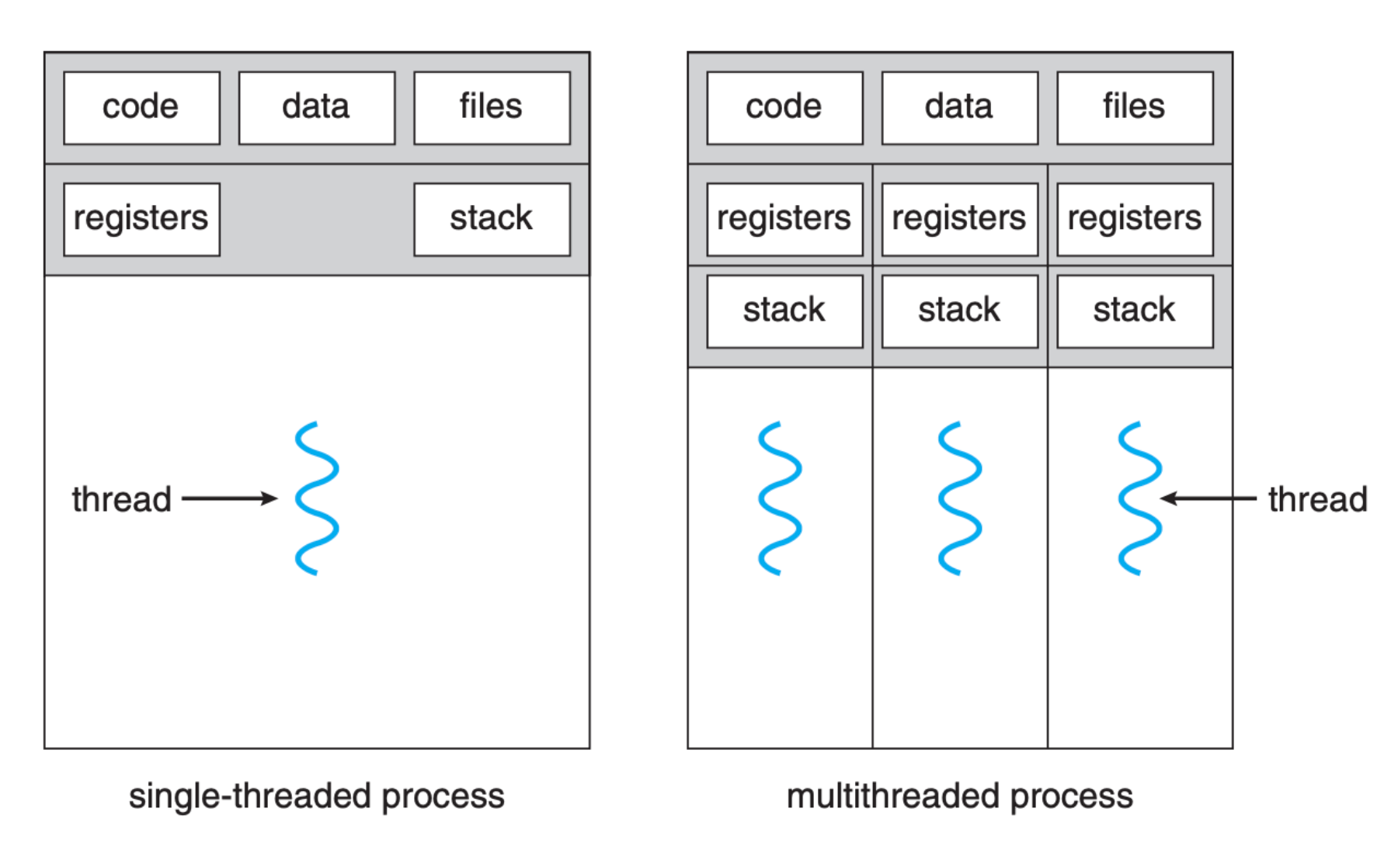
The figure below (taken from SGG book) shows the illustration of a single-threaded and multi threaded processes. As shown, it shares with other threads belonging to the same process its code section, data section, and other operating-system resources, such as open files and signals. Multiple threads in the same process operates in the same address space.
Multithreading Benefits

Responsiveness
Threads make the program seem more responsive. Multithreading an interactive application may allow a program to continue running even if part of it is blocked or is performing a lengthy operation, thereby increasing responsiveness to the user.
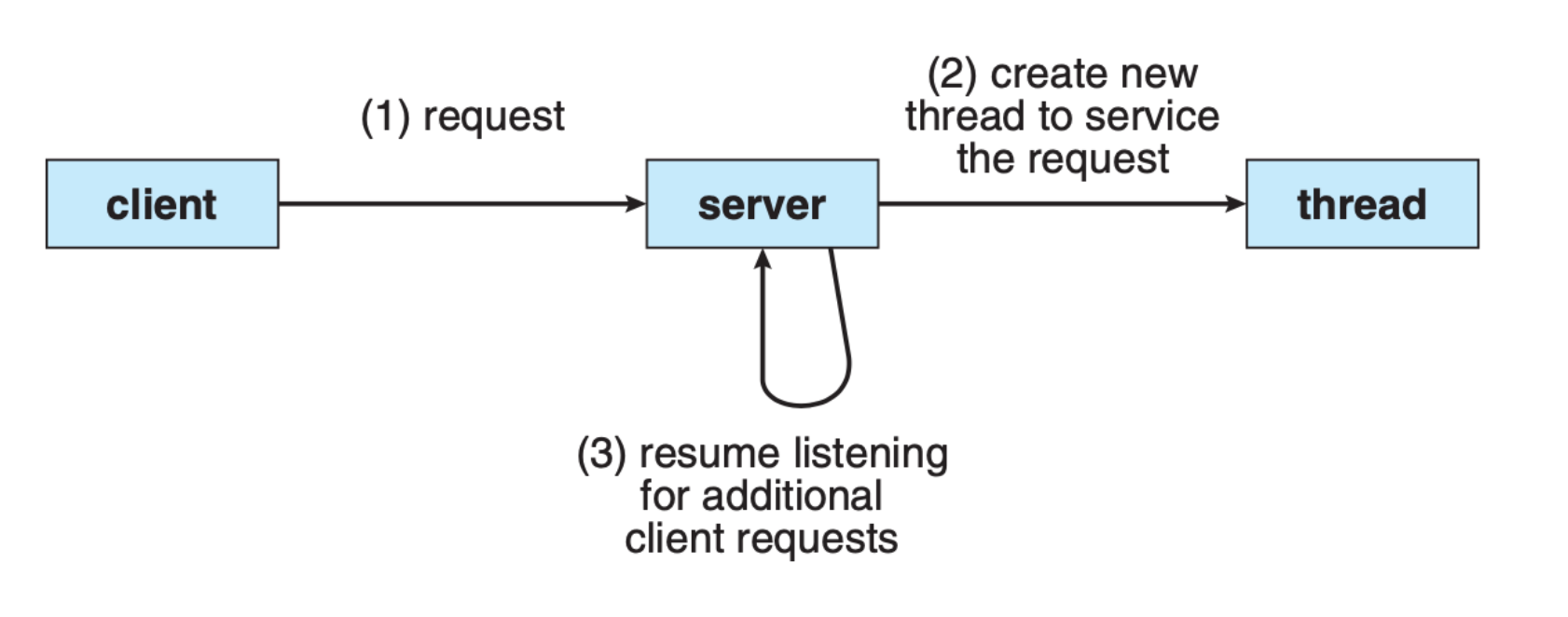
For example, a multithreaded server architecture below (taken from SGG book) allows the server to remain responsive in accepting new clients while servicing existing clients’ requests:
Multithreading us to reap the benefits of true parallel programming in multiprocessor architecture, where threads may be running in parallel on different processing cores.
Easy Resource Sharing and Communication
Easier means for resource sharing and communication (since code, data, and files are shared among threads of the same process and they have the same address space), as compared to creating multiple processes. On the other hand, multiple processes can only share resources through techniques such as shared memory and message passing.
Threads are Lighter
Creating new threads requires cheaper resources than creating new processes. Performing thread context switch is also a cheaper process.
- Allocating memory and resources for process creation is costly.
- Because threads share the resources of the process to which they belong, it is more economical to create and context-switch threads.
Remember, context switch is pure overhead.
Multithreading vs Multiprocessing
Protection and Concurrency
Processes have both concurrency and protection. One process is isolated from the other, hence providing fault isolation.
Threads only have concurrency but not protection since code, data, and files are shared between threads of the same process. There’s no fault isolation.
Communication
IPC is expensive, requires system calls and context switch between processes has high overhead.
Thread communication has low overhead since they share the same address space. Context switching (basically thread switching) between threads is much cheaper.
Parallel Execution
Parallel process execution is always available on multicore system.
However, parallel thread execution is not always available. It depends on the types of threads.
Synchronisation
We can rely on OS services (system calls) to synchronise execution between processes, i.e: using semaphores
However, careful programming is required (burden on the developer) to synchronise between threads.
Overhead cost
Processes are entirely managed by Kernel Scheduler:
- To switch between process executions, full (costly) context switch is required + system call
- The context of a process is large, including flushing the cache, managing the MMU since each process lives in different virtual space
Threads are managed by Thread Scheduler (user space, depending on the language):
- To switch between thread executions, lighter context switch is sufficient
- The context of a thread is lighter, since threads live in the same virtual space. Contents that need to be switched involve mainly only registers and stack.
- May or may not need to perform system call to access Thread API, depending on the types of thread
Thread Examples: Java and C pthread
Java Thread
Java threads are managed by the JVM. You can create Java threads in two ways.
Runnable Interface
The first way is by implementing a runnable interface and call it using a thread.
Step 1: Implement a runnable interface and its run() function:
public class MyRunnable implements Runnable {
public void run(){
System.out.println("MyRunnable running");
}
}
Step 2: Create a new Thread instance and pass the runnable onto its constructor. Call the start() function to begin the execution of the thread:
Runnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();
Thread subclass
The second way is to create a subclass of Thread and override the method run(). For example,
public class CustomThread extends Thread {
public void run(){
System.out.println("CustomThread running");
}
}
Then, create and start CustomThread instance to start the thread:
CustomThread ct = new CustomThread();
ct.start();
C Thread
We can also equivalently create threads in C using the pthread library. The code below shows how we can create threads in C:
- Create a function with void* return type (generic return type)
- Use
pthread_createto create a thread that executes this function - Use
pthread_jointo wait for a thread to finish
Program: pthread creation

We can pass arguments to a thread, wait for its completion and get its return value.
Threads from the same process share heap and data. A global variable like shared_integer in the example below is visible to both main thread and created thread.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
int shared_integer; // instantiate integer in fixed memory
void *customThreadFunc(void *vargp)
{
sleep(1);
char argument = *(char *)vargp;
printf("Printing helloWorld from spawned thread with argument: %c\n", argument);
shared_integer++;
char answer = 'a'; // in stack
char *answer_heap = malloc(sizeof(char)); // in heap
*answer_heap = 'a';
pthread_exit((void *)answer_heap);
// pthread_exit((void *) &answer); // will result in segfault
}
int main()
{
shared_integer = 10;
pthread_t thread_id;
char input_argument = 'b'; // to pass to thread
char *result; // to hold return value
// pthread_create(pthread_t* thread_id, NULLABLE thread attributes, void* function_for_thread, NULLABLE void* argument)
pthread_create(&thread_id, NULL, customThreadFunc, &input_argument);
sleep(1);
printf("shared_integer: %d\n", shared_integer); // potential race condition
// pthread_join(pthread_t thread_id, void return_value);
// Second argument of type void : pass the address of "result", which is a pointer to the supposed return value of the thread
// blocking
pthread_join(thread_id, (void * )&result);
printf("After thread join...\n");
printf("shared_integer: %d\n", shared_integer);
printf("result: %c\n", *result);
exit(0);
}
Return value
In the example above, we created answer_heap using malloc, therefore this answer resides in the heap (shared with all threads in the entire process, persists for as long as the process is not terminated).
However, if we return a pointer to variable that’s initialized in the thread’s stack, then you will end up with a segfault error.
Types of Threads
We can create two types of threads, kernel level threads and user level threads.
User level threads
User level threads (sometimes known as green threads) are threads that are:
- Scheduled by a runtime library or virtual environment instead of by the Kernel.
- They are managed in user space instead of kernel space, enabling them to work in OS that do not have native thread support.
- This is what programmers typically use. (e.g when we create Thread in C or Java above).
Kernel level threads
Background
The kernel is the core part of the operating system. It manages system resources, hardware, and provides essential services such as process management, memory management, and I/O operations. The kernel itself does not have a context because it is not an executable entity; rather, it is a collection of code and data structures that manage the system.
A kernel thread is an individual execution unit within the kernel. It is schedulable and can perform tasks on behalf of the kernel, such as handling system calls, managing hardware interrupts, and executing kernel-level functions. Kernel threads do have contexts because they need to maintain their own execution states.
To augment the need for running background operations, the kernel spawns threads, similar to regular processes in that they are represented by a task_struct and assigned a PID. Unlike user processes, they do not have any address space mapped, and run exclusively in kernel mode, which makes them non-interactive.
Kernel level threads (sometimes known as OS-level threads) are threads that are:
- Scheduled by the Kernel, having its own stack and register values, but share data with other Kernel threads.
- Can be viewed as lightweight processes, which perform a certain task asynchronously.
- A kernel-level thread need not be associated with a process; a kernel can create them whenever it needs to perform a particular task.
- Kernel threads cannot execute in user mode.
- Processes that create kernel-level threads use it to implement background tasks in the kernel.
- E.g: handling asynchronous events or waiting for an event to occur.
All modern operating systems support kernel level threads, allowing the kernel to perform multiple simultaneous tasks and/or to service multiple kernel system calls simultaneously.
Most programming languages will provide an interface to create kernel-level threads, and the API for kernel-level threads are system-dependent. The C-API for creating kernel threads in Linux:
#include <kthread.h>
kthread_create(int (*function)(void *data), void *data, const char name[], ...)
All kernel threads are descendants of kthreadd (pid 2), which is spawned by the kernel (pid 0) during boot. The kthreadd is a perpetually running thread that looks into a list called kthread_create_list for data on new kthreads to be created.
You can view it via ps -ef command, they are shown within square brackets []:
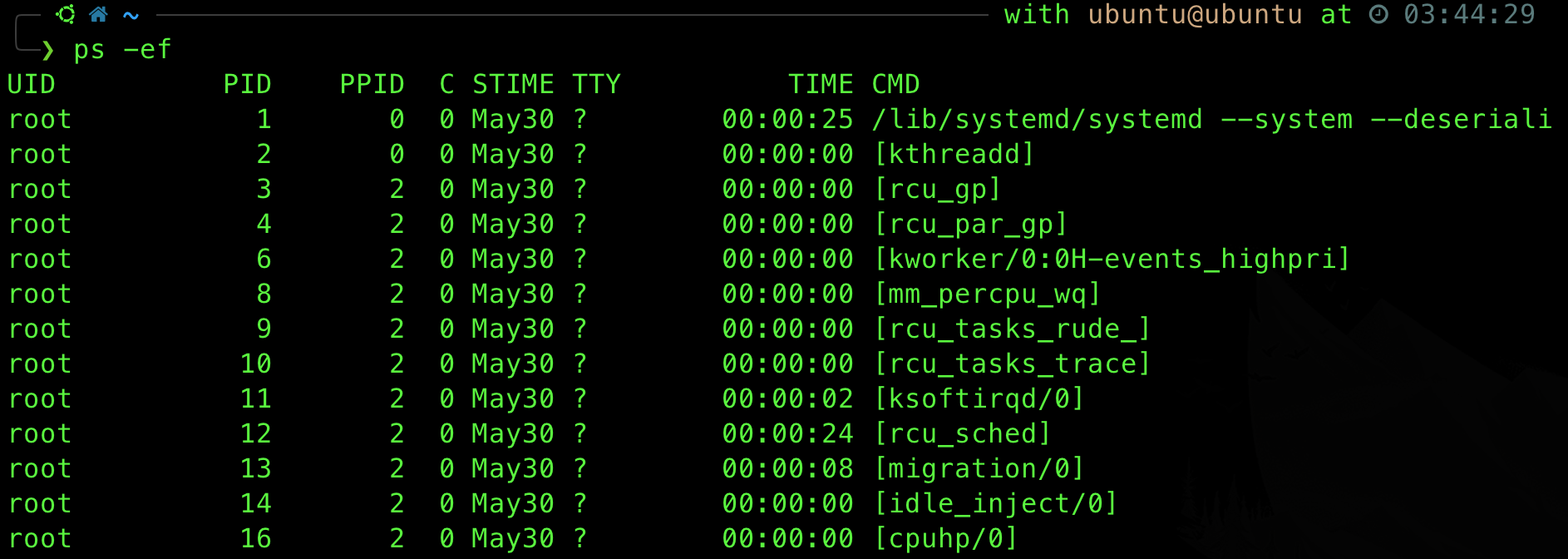
They each have a specific task, for instance [migration/0] handles distributes processes across cores, [cpuhp/0] supports physically adding and removing CPUs from the system, etc. You should ask AI if you’re interested to read some info about other kernel threads and what they might do, but it is not part of the syllabus. The are alot of kernel threads that are not well documented, just like your 1D assignments, so take it with a grain of salt.
Use case
System Monitoring
Many device drivers utilize the services of kernel threads to implement assistant or helper tasks. Suppose you would like the Kernel to asynchronously invoke a user mode program to send you an email alert whenever it senses that the health of certain key kernel data structures is deteriorating. For instance, free space in network receive buffers has dipped below a certain healthy threshold, risking losing incoming packets.
This need warrants a creation of Kernel Thread because:
- It’s a background task because it has to wait for asynchronous events (depending on the network buffer state).
- It needs access to kernel data structures because the actual detection of events is done by other parts of the kernel.
- It has to invoke a user mode helper program (time consuming, requires resources to complete).
This Kernel thread will sleep until it gets woken up by parts of the Kernel responsible for monitoring the network receive buffers. When awake, it invokes a user mode helper program and passes appropriate identity codes in its environment.
Paged Memory Management
This task involves managing the system’s memory by swapping pages of memory in and out of disk storage (swap space) to ensure efficient use of the available physical memory. This is essential for systems that support virtual memory, where the total memory required by all running processes might exceed the physical memory available.
Why a Kernel Thread is Needed for Page Swapping
Background Task: Page Swapping
- Description: When physical memory is full, the operating system needs to free up space by swapping out less frequently used pages to disk (swap space) and swapping in needed pages from the disk to physical memory. This process needs to be handled efficiently and transparently to maintain system performance and stability.
Role of Kernel Threads in Page Swapping
-
Continuous Monitoring: Kernel threads continuously monitor the memory usage of the system. They check if the system is running low on physical memory and decide when to initiate page swapping.
-
Asynchronous Operation: Swapping pages can be a time-consuming I/O operation. Kernel threads perform these operations asynchronously, allowing the system to continue running other tasks without blocking. This is crucial for maintaining system responsiveness.
-
Prioritization and Scheduling: Kernel threads allow the kernel to prioritize and schedule the page swapping operations based on system policies. They can ensure that critical pages are swapped in quickly, and less critical pages are swapped out as needed.
-
Efficiency and Performance: Kernel threads can optimize the performance of the paging system by handling multiple page swap operations concurrently. This parallelism can significantly reduce the time required to manage memory.
Practical Example: Page Swapping in Action
-
Memory Pressure Detection: A kernel thread continuously monitors the system’s memory usage. When it detects that free physical memory falls below a certain threshold, it triggers the page swapping process.
-
Page Selection: The kernel thread selects the pages to be swapped out based on a page replacement algorithm (e.g., Least Recently Used - LRU). It determines which pages are the best candidates for swapping out to disk.
-
Swapping Out: The kernel thread initiates the I/O operations required to write the selected pages to the swap space on disk. This operation is performed asynchronously to avoid blocking the system’s execution.
-
Swapping In: When a process needs a page that is not in physical memory, a page fault occurs. The kernel thread is responsible for handling the page fault by reading the required page from the swap space back into physical memory.
-
Context Management: The kernel thread ensures that the contexts of the affected processes are updated correctly, so when a swapped-out page is brought back into memory, the process can continue execution seamlessly.
Why Kernel Threads, Not Just Kernel Code
-
Concurrency: Kernel threads allow the paging operations to be performed concurrently with other kernel and user-space operations. This concurrency is vital for maintaining overall system performance.
-
Non-Blocking Operations: By using kernel threads, the system can perform potentially long I/O operations without blocking the execution of other critical tasks, thus ensuring smooth system performance.
-
Independent Execution: Kernel threads can execute independently of user-space processes, enabling the kernel to manage system resources effectively even when no user-space process explicitly triggers a system call related to memory management.
Kernel threads are essential for performing background tasks like page swapping in a virtual memory system. They enable the kernel to manage memory efficiently, handle asynchronous I/O operations, and ensure the system remains responsive and stable. This background task demonstrates why kernel threads are necessary for tasks that the kernel must manage independently of direct user-space process interactions.
Kernel vs User Level Threads
| Kernel Level Threads | User Level Threads |
|---|---|
| Known to OS Kernel | Not known to OS Kernel |
| Runs in Kernel mode. All code and data structures for the Thread API exist in Kernel space. | Runs entirely in User mode. All code and data structures for the Thread API exist in user space. |
| If a user thread is mapped to a kernel thread (1 to 1 mapping), then invoking some functions in the API like create or join results in trap (system call) to the Kernel Mode (requires a change of mode) | Invoking a function in the API results in local function call in user space. |
| Scheduled directly by Kernel scheduler | Managed and scheduled entirely by the run time system (user level library). |
| Scheduler maintains one thread control block per thread in the system in a system wide thread table. Scheduler also manages one process control block per process in the system in a system wide process table. From the OS’s point of view, these are what is scheduled to run on a CPU. Kernel must manage the scheduling of both threads and processes. |
The thread scheduler is running in user mode. It exists in the thread library (e.g: phtread of Java thread) linked with the process. |
| Multiple Kernel threads can run on different processors. | Multiple user threads on the same user process may not be run on multiple cores (since the Kernel isn’t aware of their presence). It depends on the mapping model (see next section). |
| Take up Kernel data structure, specific to the operating system. | Take up thread data structure (depends on the library). More generic and can run on any system, even on OS that doesn’t support multithreading |
| Requires more resources to allocate / deallocate. | Cheaper to allocate / deallocate. |
| Significant overhead and increase in kernel complexity. | Simple management, creating, switching and synchronizing threads done in user-space without kernel intervention. |
| Switching threads is as expensive as making a system call. | Fast and efficient, switching threads not much more expensive than a function call |
| Since kernel has full knowledge of all kernel threads, the scheduler may be more efficient. Example: • Give more CPU time for processes with larger number of threads • Schedule threads that are currently holding a lock. |
Since OS is not aware of user-level threads, Kernel may forcibly make poor decisions. Example: • Scheduling a process with idle threads • Blocking a process due to a blocking thread even though the process has other threads that can run • Giving a process as a whole one time slice irrespective of whether the process has 1 or 1000 threads • Unschedule a process with a thread holding a lock |
Thread Mapping
Since there are two types of threads: kernel and user thread, there should exist some kind of mapping between the two. The mapping of user threads to kernel threads is done using virtual processors1. We can think of kernel level threads as virtual processors and user level threads as simply threads.
There are three types of mapping.
Many to One
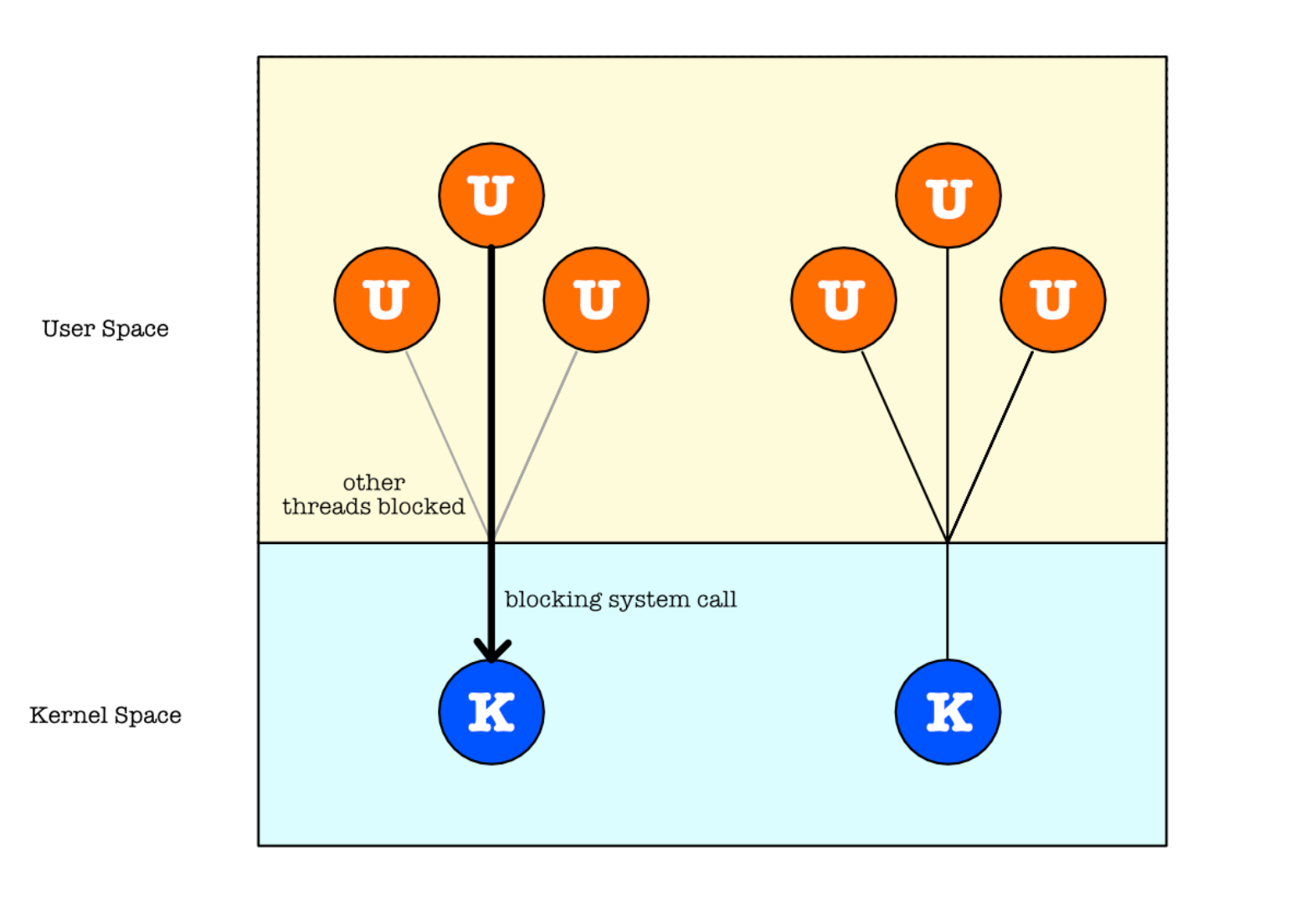
Maps many user-level threads to one kernel thread.
Advantage:
- Thread management is done by the thread library in user space, so it is more efficient as opposed to kernel thread management.
- Developers may create as many threads as they want
- Entire thread context-switching is maintained by the user-level thread library entirely
Disadvantage:
- The entire process will block if a thread makes a blocking system call since kernel isn’t aware of the presence of these user threads
- Since only one thread can access the kernel at a time, multiple threads attached to the same kernel thread are unable to run in parallel on multicore systems
One to One
Maps each user thread to a kernel thread. You can simply think of this as process threads to be managed entirely by the Kernel.
Advantage:
- Provides more concurrency than the many-to-one model by allowing another thread to run when a thread makes a blocking system call.
- Allows multiple threads to run in parallel on multiprocessors.
Disadvantage:
- Creating a user thread requires creating the corresponding kernel thread (a lot of overhead, system call must be made)
- Limited amount of threads can be created to not burden the system
- May have to involve the kernel when there is a context switch between the threads (overhead)
The modern Linux implementation of pthreads uses a 1:1 mapping between pthread threads and kernel threads, so you will always get a kernel-level thread with pthread_create().
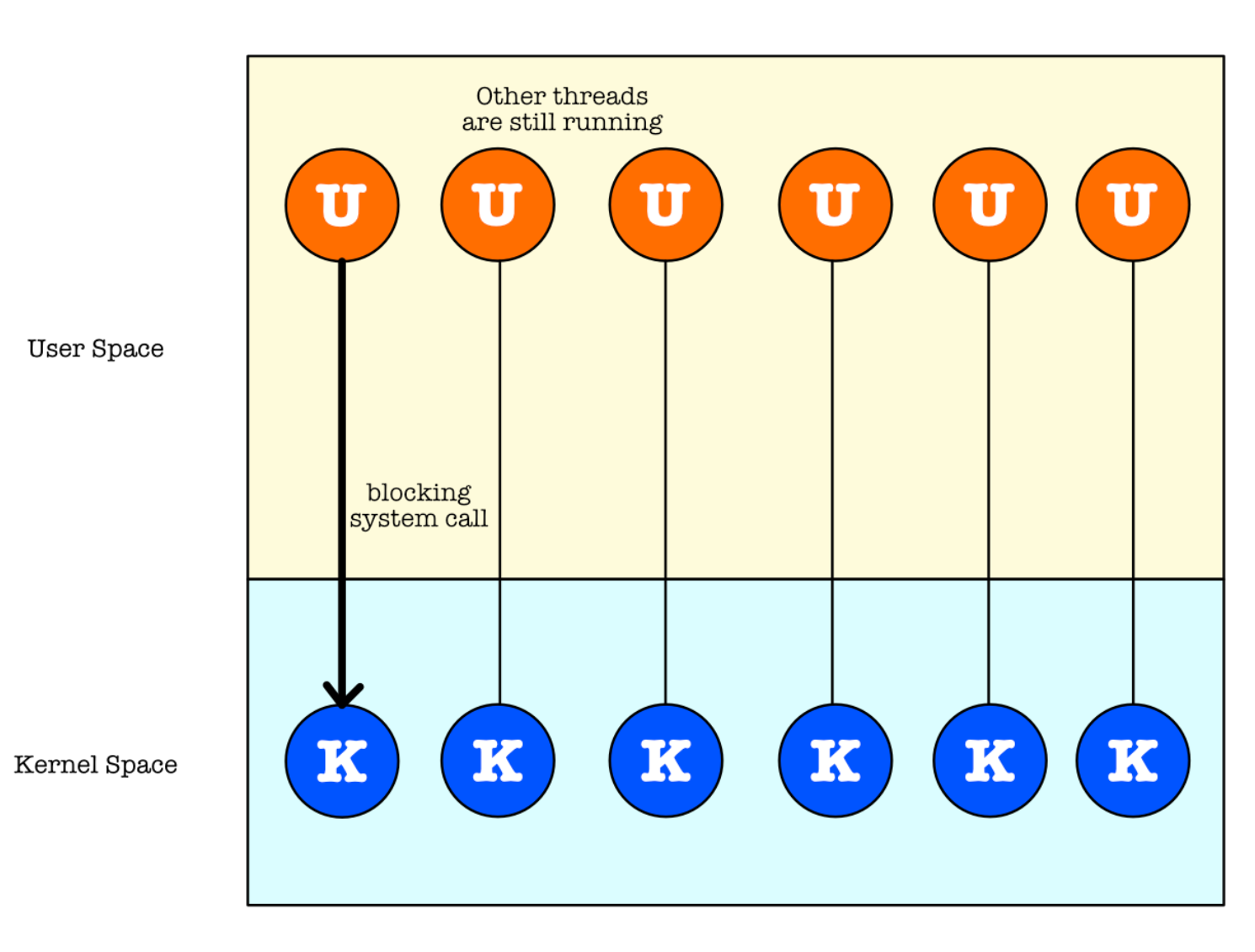
Many to Many
Multiplexes many user-level threads to a smaller or equal number of kernel threads.
This is the best of both worlds:
- Developers can create as many user threads as necessary,
- The corresponding kernel threads can run in parallel on a multiprocessor.
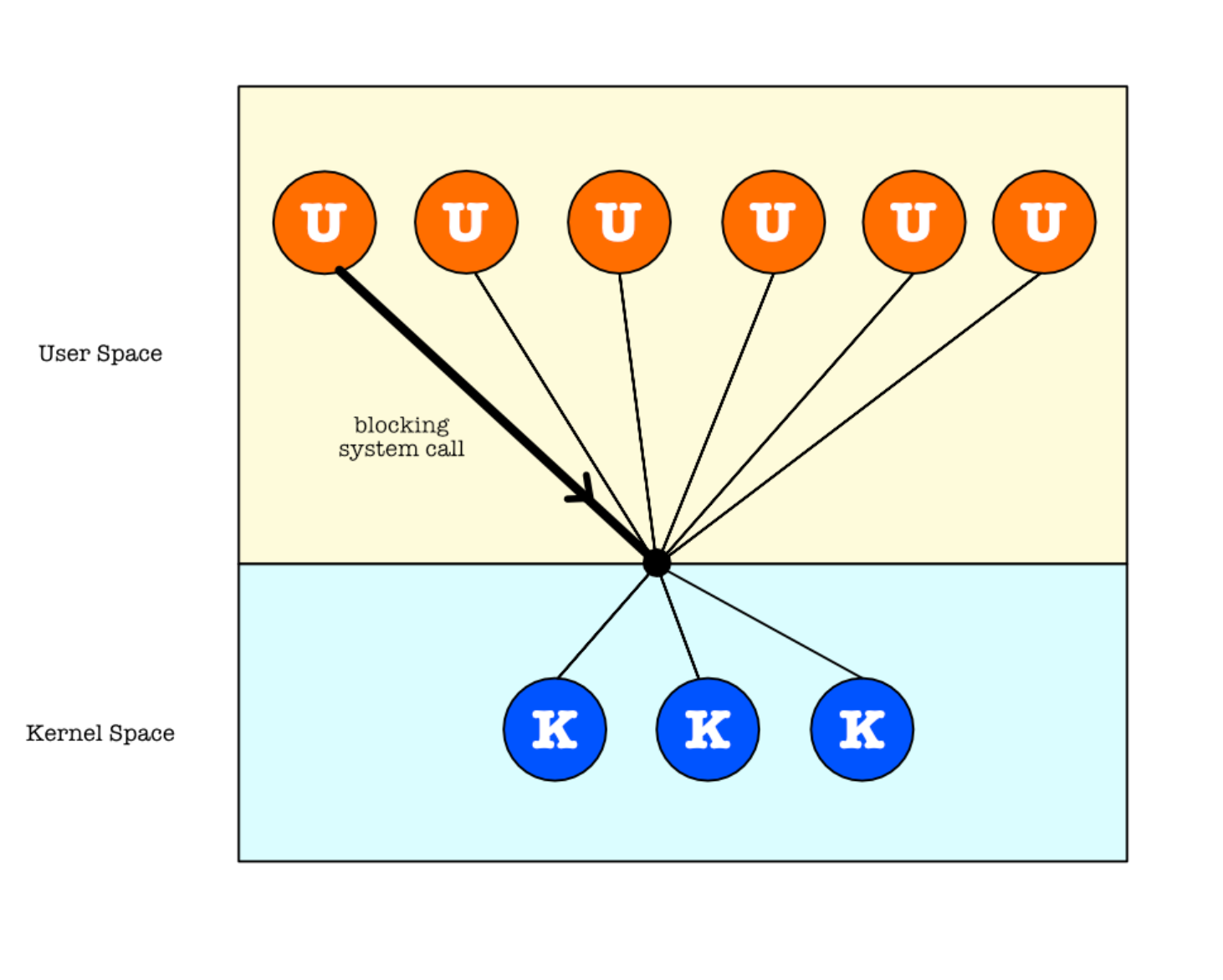
A variation of many-to-many mapping, the two-level model: both multiplexing user threads and allowing some user threads to be mapped to just one kernel thread.
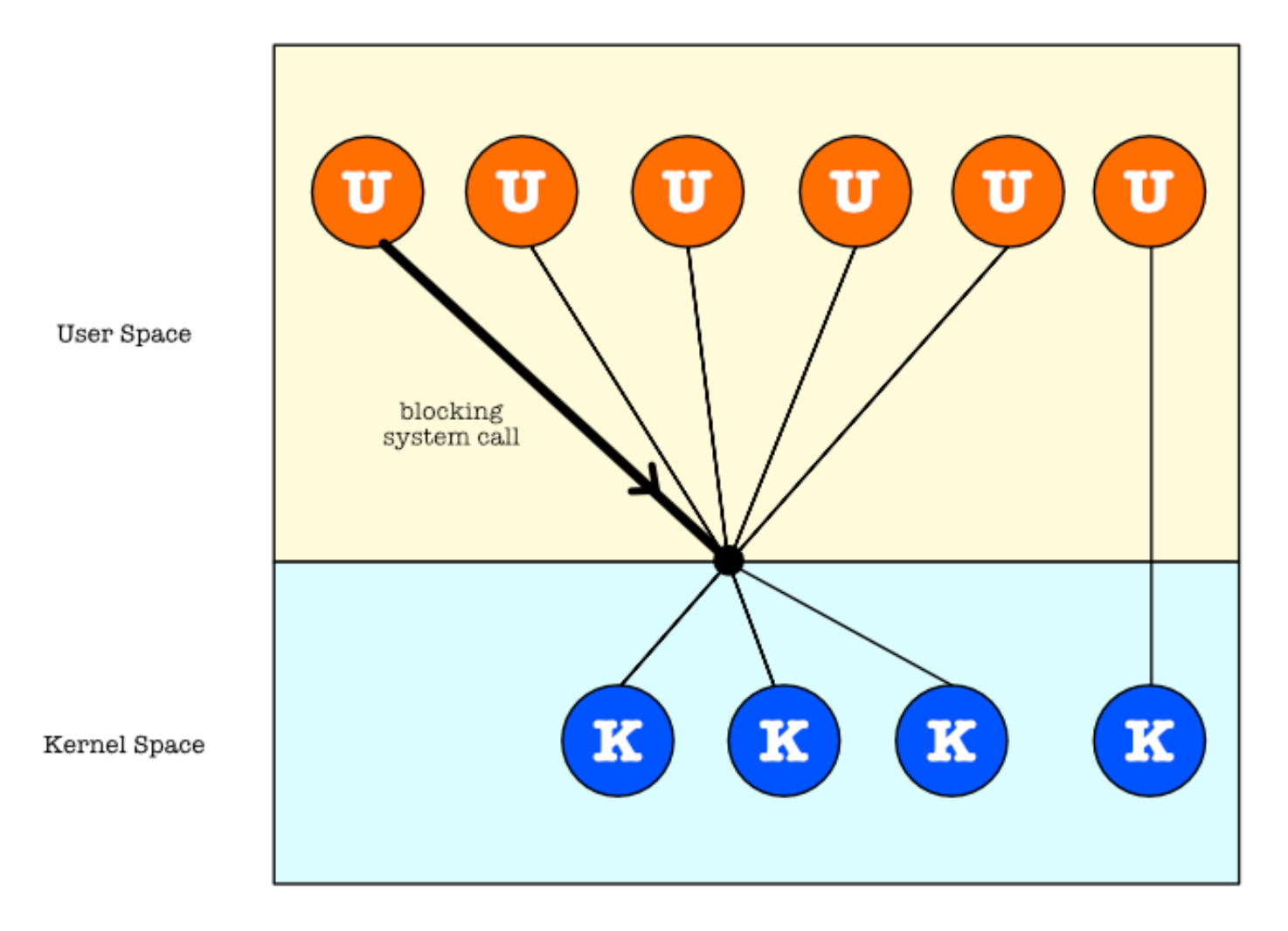
In some systems, especially in many-to-many or two-level models, there is some way for the user threading library to communicate (coordinate) with kernel threads via scheduler activation, i.e: a mechanism whereby kernel can allocate more threads to the process on demand.
Intel Hyper-Threading
Hyper-threading was Intel’s first effort (proprietary method) to bring parallel computation to end user’s PCs by fooling the kernel to think that there exist more than 1 processors in a single processor system:
- A single CPU with hyper-threading appears as two or more logical CPUs (with all its resources and registers) for the operating system kernel
- This is a process where a CPU splits each of its physical cores into virtual cores, which are known as threads.
- Hence the kernel assumes two CPUs for each single CPU core, and therefore increasing the efficiency of one physical core.
- It lets a single CPU to fetch and execute instructions from two memory locations simultaneously
This is possible if a big chunk of CPU time is wasted as it waits for data from cache or RAM.
Multicore Programming

On a system with multiple cores and supported kernel mapping, concurrency means that the threads can run in parallel, because the system can assign a separate thread to each core.
A possible parallel execution sequence on a multicore system is as shown (Ti stands for Thread i, 4 threads in total in this example):
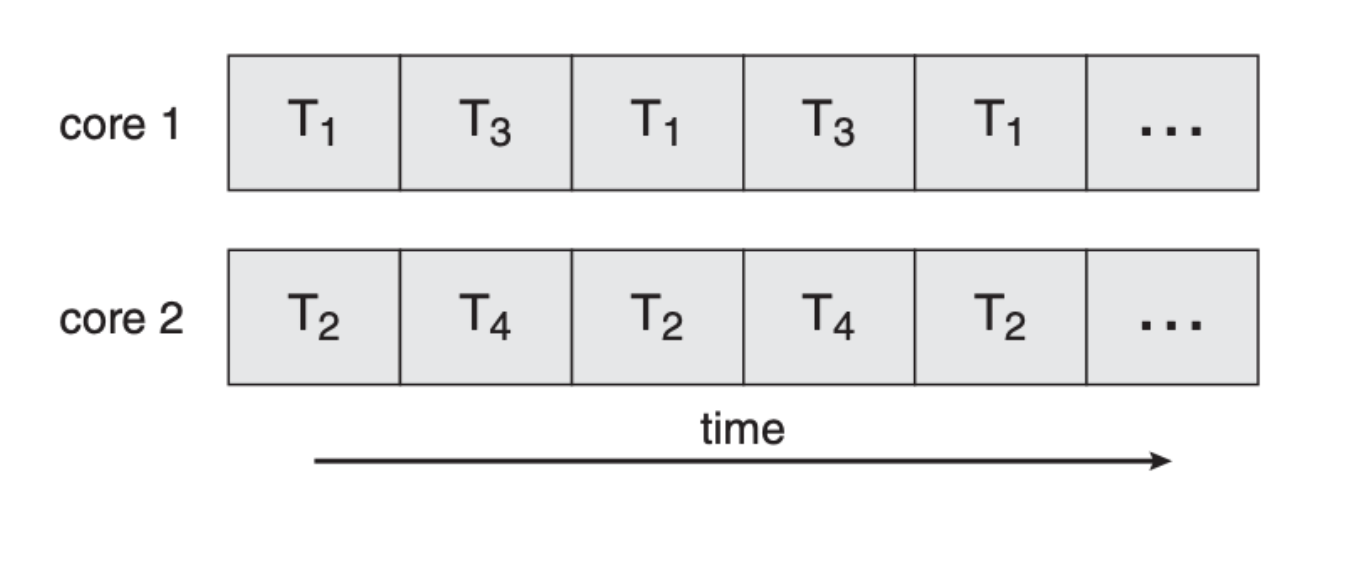
This is faster from concurrent execution with a single core as shown:

There are two types of parallelism that we can achieve via multicore programming: data parallelism and task parallelism.
Data parallelism focuses on distributing subsets of the same data across multiple computing cores and performing the same operation on each core.
Task parallelism involves distributing not data but tasks (threads) across multiple computing cores.
- Each thread is performing a unique operation.
- Different threads may be operating on the same data, or they may be operating on different data.
Amdahl’s Law
Not all programs can be 100% parallelised. Some programs required a portion of its instructions to be serialised. We need to identify potential performance gains from adding additional computing cores to an application that has both serial (nonparallel) and parallel components.
Given that $\alpha$ is the fraction of the program that must be executed serially, the maximum speedup that we can gain when running this program with $N$ CPU cores (processors) is:
\[\frac{1}{\alpha + \frac{1-\alpha}{N}}\]Ask yourself
What is the maximum speedup we can gain when $\alpha=30$% and $N$ is $\infty$?
Summary
This chapter covers the essentials of threads in operating systems, explaining that threads are lighter, more efficient segments of processes designed to execute tasks. It differentiates between user-level and kernel-level threads, discusses their advantages, and outlines their management. The text also explores the benefits of multithreading, such as increased responsiveness and efficient resource sharing, alongside practical implementation in Java and C.
Key learning points include:
- Basics of Threads: Defines threads as segments of a process that include a unique thread ID, program counter, register set, and stack.
- Multithreading Benefits: Highlights improvements in responsiveness and resource sharing, contrasting with the heavier resource demands of multiprocessing.
- Types of Threads: Differentiates between user-level and kernel-level threads, discussing their scheduling and use cases.
- Thread Safety and Synchronization: Addresses the necessity for mechanisms like mutexes and semaphores to prevent race conditions.
- Performance Considerations: Applies concepts like Amdahl’s Law to evaluate the benefits of parallel execution on multicore systems.
Appendix
Daemon Processes
A daemon is a background process that performs a specific function or system task. It is created in user mode.
In keeping with the UNIX and Linux philosophy of modularity, daemons are programs rather than parts of the kernel. Many daemons start at boot time and continue to run as long as the system is up. Other daemons are started when needed and run only as long as they are useful.
The daemon process is designed to run in the background, typically managing some kind of ongoing service. A daemon process might listen for an incoming request for access to a service. For example, the httpd daemon listens for requests to view web pages. Or a daemon might be intended to initiate activities itself over time. For example, the crond daemon is designed to launch cron[^9] jobs at preset times.
When we refer to a daemon process, we are referring to a process with these characteristics:
- Generally persistent (though it may spawn temporary helper processes like xinetd does)
- No controlling terminal (and the controlling
ttyprocess group (tpgid) is shown as -1 inps) - Parent process is generally init (process 1)
- Generally has its own process group
idand sessionid(daemon group)
More on Linux Startup Process
The Linux startup process very much depends on the hardware architecture, but it can be simplified into the following steps:
- Firstly, the BIOS performs setup tasks that are specific to the hardware of the system. This is to prepare the hardware for the bootup process. After setup is done successfully, the bios loads the boot code (bootloader) from the boot device (the disk)
- The bootloader will load the default option of the operating system. If there’s more than 1 OS, then the user is presented with an option of selecting an OS to run.
- After an OS is selected, the bootloader loads the kernel into memory, and the CPU starts execution in kernel mode.
- The kernel will setup system functions that are crucial for hardware and memory paging, perform the majority of system setups pertaining to interrupts, memory management, device, and driver initialization.
- It then start up a bunch of daemon processes:
- The
idleprocess and theinitprocess for example, that runs in user space
- The
- The
initeither consists of scripts that can be executed by the shell (sysv, bsd, runit) or configuration files that are executed by the binary components (systemd, upstart).- The
initprocess bascally invokes a specific set of services (daemons). - These provide various background system services and structures and form the user environment.
- The
- Desktop environment is eventually launched
Desktop environment
The desktop environment begins with a daemon, called the display manager that starts a GUI environment which consists of:
- Graphical server that provides basic rendering and manages input from user
- Login manager that provides the ability to enter credentials and select a session (basically our login page).
After the user has entered the correct credentials, the session manager starts a session.
A session is a set of programs such as UI elements (panels, desktops, applets, etc.) which together can form a complete desktop environment.
ee9]: cron is a Linux utility which schedules a command or script on your server to run automatically at a specified time and date. A cron job is the scheduled task itself.