 50.005 CSE
50.005 CSE
- UNIX Directories
- Directory Structure
- File Links
- Graph Directory Structure
- Summary
50.005 Computer System Engineering
Information Systems Technology and Design
Singapore University of Technology and Design
Natalie Agus (Summer 2025)
UNIX Directories
Detailed Learning Objectives
- Explain Directories and Namespace Organization
- Define what a directory is in the context of file systems, as well as its differences vs a regular file.
- Explain how directories help organize files and subdirectories within a structured namespace.
- Explain Directory Permissions and Operations
- Examine the significance of
x,r, andwpermissions in directories.- Identify the effects of directory permissions on file access and operations within the directory.
- Explain Directory Structures and Their Types
- Compare and contrast different directory structures such as single-level, two-level, tree-structured, acyclic graph, and general graph directories.
- Discuss the benefits and limitations of each directory structure type.
- Explain Directory and File Linking Concepts
- Differentiate between hard links and symbolic links.
- Discuss the use cases for each type of link and how they affect file management and system organization.
- Describe File Searching and Directory Traversal Process
- Explain the general process of searching for files within directories.
- Describe how directory traversal works (utilising directories and inode tables) and its importance in file system navigation.
- Explain Advanced Directory Concepts
- Justify each graph directory structures and the implications of cycles within directories.
- Explain how reference counting and garbage collection protocols are used in managing directory lifecycles.
These learning objectives aim to provide a comprehensive understanding of how directories function as essential components of file systems, facilitating the organization, access, and management of files.
Directories are the file system cataloguing structure that contains metadata (references) to organize files in a structured name space (path). In computing, a namespace is a set of symbols that are used to organize objects of various kinds, so that these objects may be referred to by name.
In UNIX-based system, a directory is implemented as a file of a special type; a special file whose content is a named collection of other file(s) plus its corresponding inode id. It is no different than a regular file, but its contents are controlled by the OS. The content of a directory consists of list of names assigned to inodes that can be interpreted by the OS.
You can think of a directory as some kind of dictionary; a symbol table that translates file names or as lists of association structures, each of which contains one filename and one inode number.
- They form lists of names assigned to inodes.
- Remember, inodes have numbers associated for each file but not filenames. File names to inode mapping is done by the directory.
- Each of the entries in the directory contains a mapping between filename and its associated inode number, plus just enough other information to translate from a filename to an inode to get to the actual content.
Most of the metadata about the file is stored within the inode associated with the file, not the directory entry.
Directory x Permission
Unlike regular files, the x bit on a directory permission is very different compared to regular files. It is often referred to as the search bit and it stands for permission to enter the directory (e.g: via cd) and to actually access any of its files.
Execute or x is needed on a directory to access the inode information of the files within. Users need this to search a directory to read the inodes of the files within. For this reason the execute permission on a directory is often called search permission instead.
If we know the inode of the file beforehand within a directory which we don’t have the x permission, can we still acess it? Well, from this little experiment, it doesn’t seem so because find still returns the path of the target file having that inode and cat still needs the path of that file to be resolved:
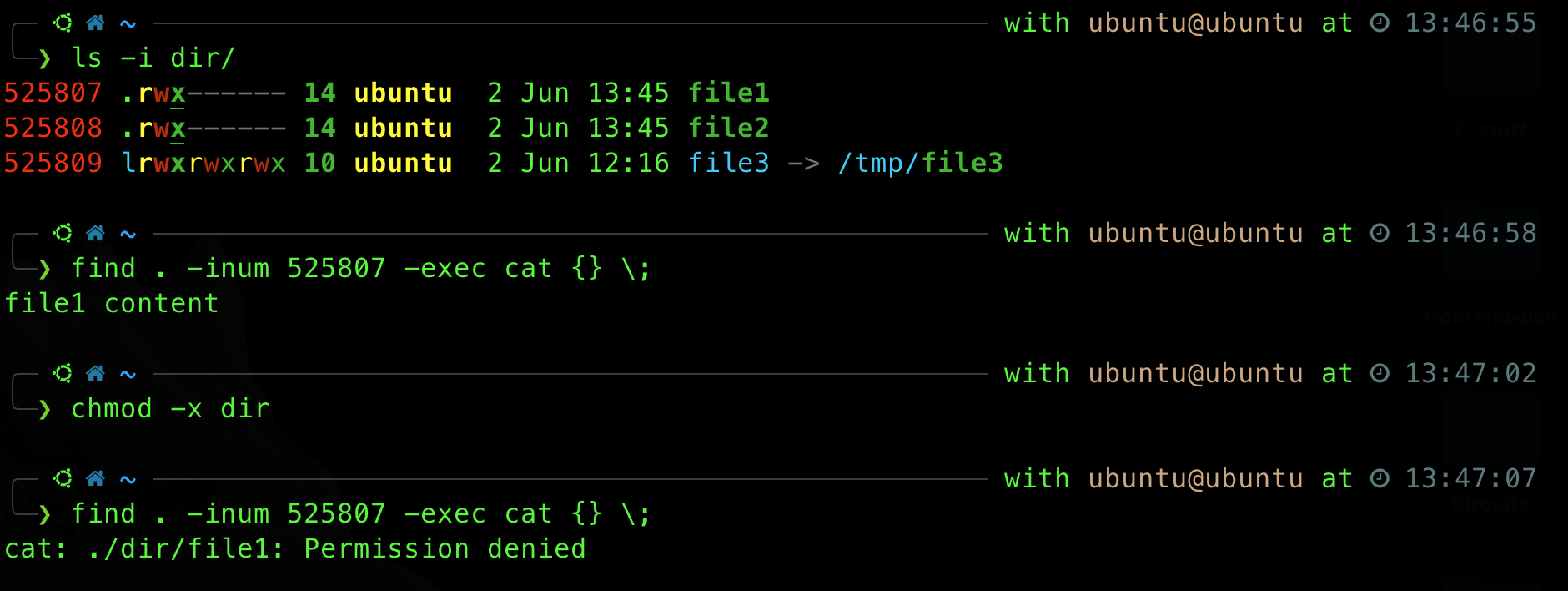
If you know a way to open a file directly given the inode number in Linux, let us know!
This is different from r permission on directories: which is simply to view the directory’s contents (e.g: via ls) and w permission which allows you to modify its content (add or remove files within it). Here’s what ls output will look like on a directory without x permission. As you can observe, you can still obtain the file names and that’s about it, no additional access to the files containing the usual metadata (date created, size, inode, etc).
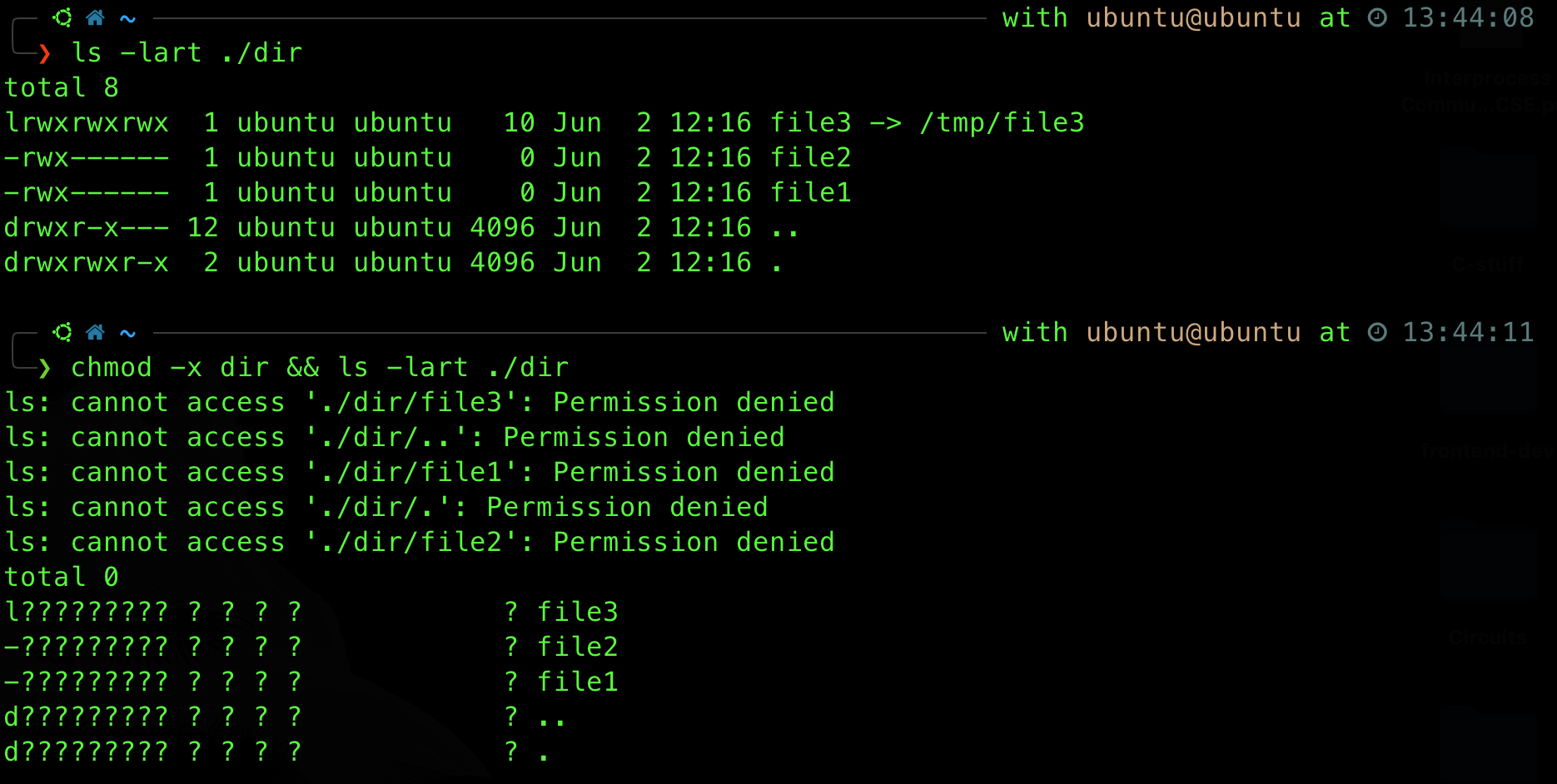
Searching for a File
Since a directory is also a file, it also has its own inode numbers, and its contents are other filenames and their inode numbers. One of the most famous directory is the inode 2 which is / (root) directory.
Fun fact: The inode with number 1 is typically reserved for a special purpose and is used by the filesystem for its internal purposes. In many Unix-like systems, inode 1 is used for the “bad blocks inode.” This inode is used to keep track of bad blocks on the disk - blocks that have been determined to be unreliable for data storage. The filesystem can maintain a list of these blocks in this inode so that they are not used in the future, helping to prevent data loss or corruption.
The file system driver (part of Kernel) must use the directory when looking for a particular filename and then convert the filename to the correct corresponding inode number. It will start from the root node and recursively search for the file name.
Directory Structure
A directory can also contain the name of other directories. We know this as a subdirectory.
Typically, both the directory structure and the files themselves reside on disk (and cached in memory). The figure below taken from the SGG book shows a common file system organization:
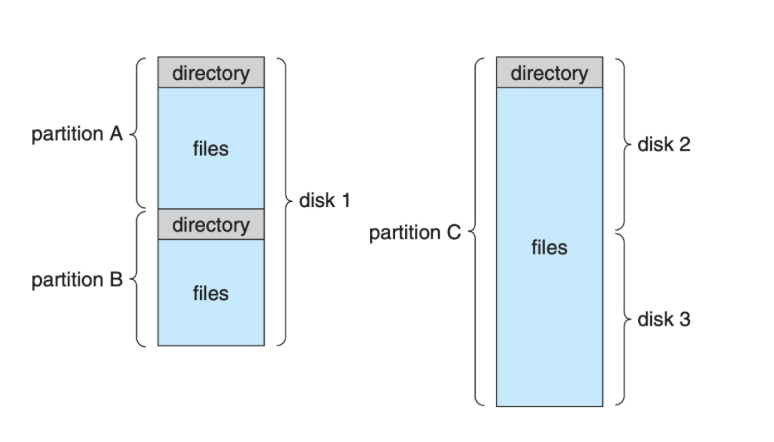
Each volume/partition that contains a file system must also contain information about the files in the system. This information is kept as entries in the device directory (a.k.a volume table of contents). The device directory (more commonly known simply as the directory) records some important information such as name, location, size, and type for all files in that volume.
Purpose
The purpose of having a directory structure is to improve user experience.
- Efficiency: locating a file or group of files quickly
- File naming in a user-friendly manner
- Users can pick the same name for their (different) files without conflicts
- Same name for files of different types (different extensions)
- Same file can have different names (multiple logical purposes; reference of same file/folder from different points in the name space)
- Organization – logical grouping of files by various properties for ease of usage:
- Group files with the same user, project, purpose, type, etc.
Think about it as IKEA having a directory (named spaces, e.g: living room, kitchen things, and named items) to improve user experience: you know where to find the things that you wanted to browser or buy and you can remember the items by name more easily than remembering its serial number.
Folder
Note that notion of a directory is very similar to the definition of a folder.
However folder is a GUI concept, associated with the common folder icons to represent collection of files. If you are referring to a container of documents, then the term folder makes more sense, related to the GUI. The term directory refers more broadly to the way a structured list of document is stored in the computer system.
Directory Traversal
File manager and GUI shell like Finder for macOS and File Explorer for Windows traverse the directories (depending on our clicks, which is the same as typing cd
In fact, they are all simply opening directories and rendering its entries. Our files are not stored in the GUI (if that makes sense). The GUI is just a logical representation of the contents of our secondary storage. These programs render different icons for different filenames (inclusive of its extension), and subdirectories of the current working directory, so that the content of the directories are more user friendly.
Our disk does not actually have places called Desktop or Downloads. These are just logical representation of where our files are stored. The directory maps the file names (the way we are addressing our files) to its corresponding inode, and then from there (inode table), the system finally finds the physical address where the file is actually stored in the secondary storage.
Without the file system and the directory, the bytes that reside in our secondary storage are just a huge chunk of bytes with no discernible boundary separating the content of each file to another.
Directory operations
All of the following file operations involves modifying and/or accessing the directory:
- Create a file or folder (subdirectory) n Delete a file or folder
- List a directory
- Rename a file
- Search for a file
- Traverse the file system with
cdor via the GUI shell
Single-level Directory
A single-level directory is best illustrated as follows:
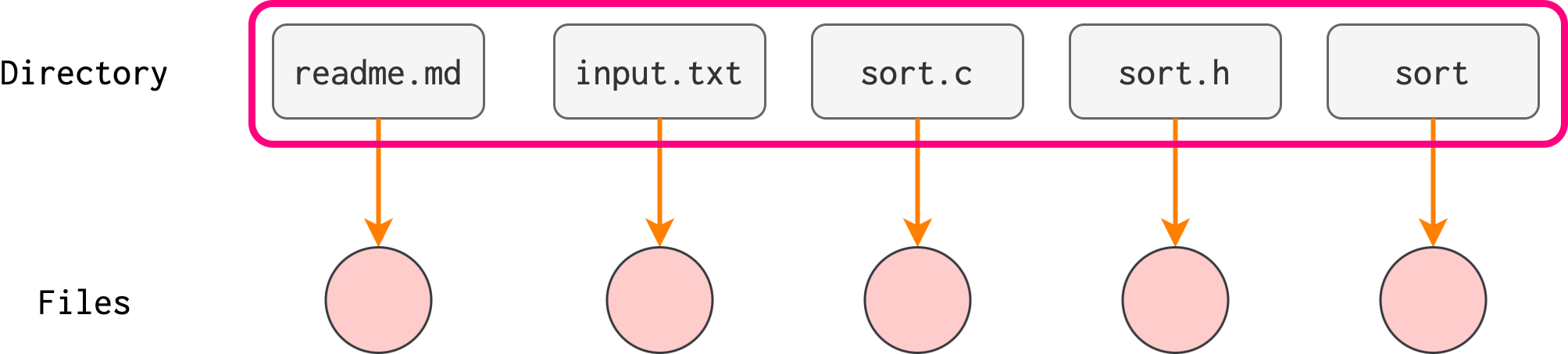
In the above example, there exist a directory with five entries in it (inside the rectangular border), each pointing to a separate file (the circles).
- This means that all files are contained in the same directory, which is easy to support and understand.
- The square nodes are the file names (inside the directory), and the circle nodes are files.
This is the simplest method to manage all of our files in the system is by having just one giant list of all the files on the disk. The entire system will contain only one directory which is supposed to mention all the files present in the file system. The directory contains one entry per each file present on the file system.
However, since all files are in the same directory (same name space), when the number of files increases or when the system has more than one user, they must have unique names. This makes the system hardly usable.
Note that the file names (readme.md, ls, myprog.c, etc) that we see here illustrates how a directory entry points to an inode (not drawn) which finally leads us to the file itself.
If we were to use a single-level directory in our system and the GUI file-manager shell, we will see simply all directory entries (or as we will normally say, ‘all filenames’) in our entire mounted secondary storage.
Two-level Directory
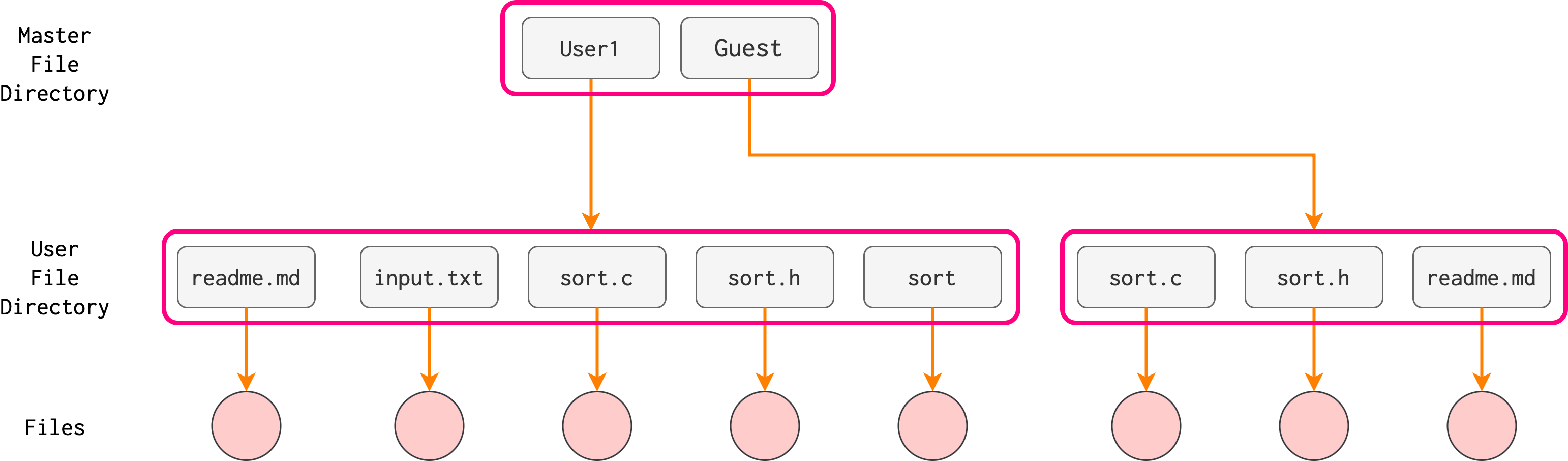
A two-level directory allows for a separate directory for each user. Notions of subdirectory and paths become clearer, e.g: /User1/readme.md, or /Guest/readme.md
Each user can have a separate name space, but still limited in logical grouping. To delete a file, the operating system confines its search to the local user file directory thus, it cannot accidentally delete another user’s file that has the same name.
Tree-Structured Directory
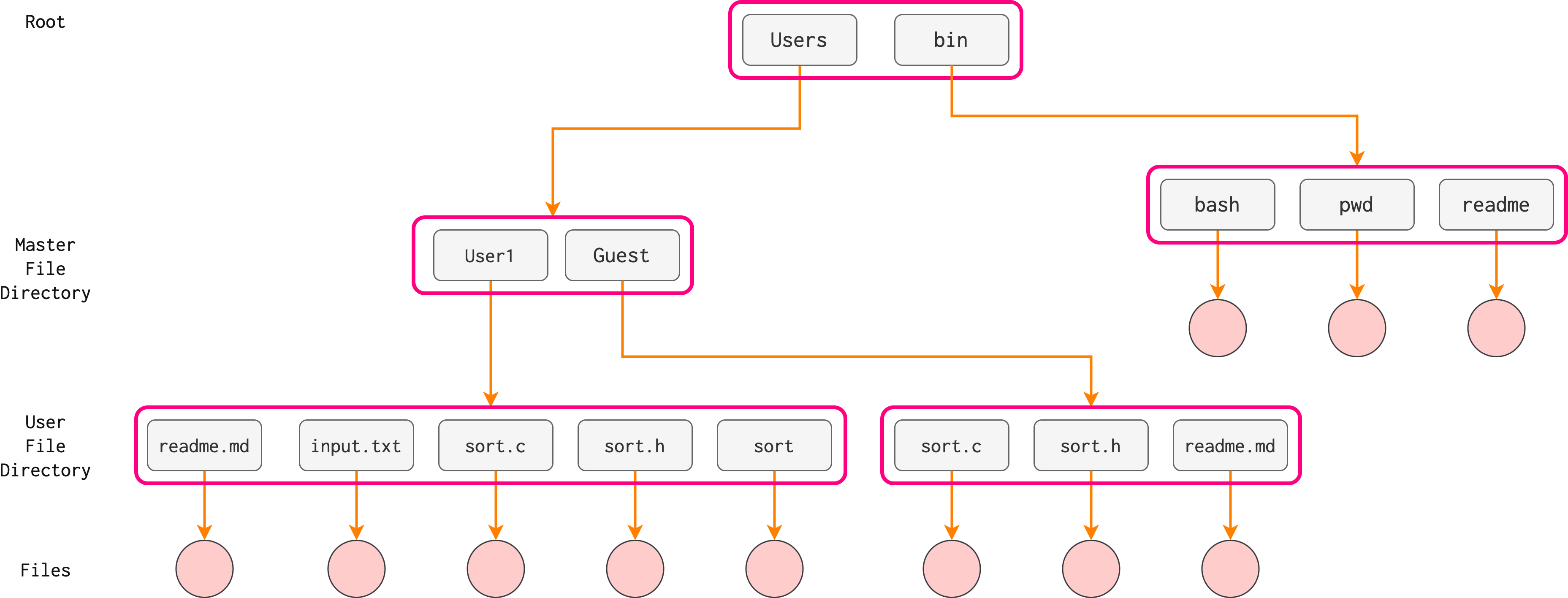
In a tree structure directory, there’s only one path to reach each file, as shown above. This is not the same as a Graph-structured Directory.
Multiple levels of hierarchy like this allow more elaborate organization of files, however:
- Full paths can become really long
- Notions of current working directory can shorten the path, e.g you can
cdto a particular location and use files from your current directory without giving the full path.
Each process has its own current working directory, typically from the process who created it.
In this kind of structure, path names can be of two types: absolute and relative.
- An absolute path name begins at the root and follows a path down to the specified file, giving the directory names on the path.
- A relative path name defines a path from the current working directory.
File Links
We can have different names for the same file by adding more than one entries pointing to the same inode in the directory. These directory entries are formally called links.
Recap about Inode
In UNIX-like file systems:
- An inode is a data structure containing attributes about all files in the system.
- These are the references to the actual file content: anonymous chunks of data, each given an inode number.
- A file in its entirety is not an inode, a file has an associated inode with it. Inode contains only the file attributes (metadata).
It is pretty difficult for users to find their files based on inode numbers. Therefore, we have directories which allows us to traverse the file system using named paths.
Recap about Directories
A directory is:
- A special file whose content is some kind of mapping of names to files (more specifically inodes).
- A directory can have another directory as its entry (so we can search for files via recursion).
- We can have different names for the same file; in this case, they have no difference (in content) at all, like a person with different nicknames.
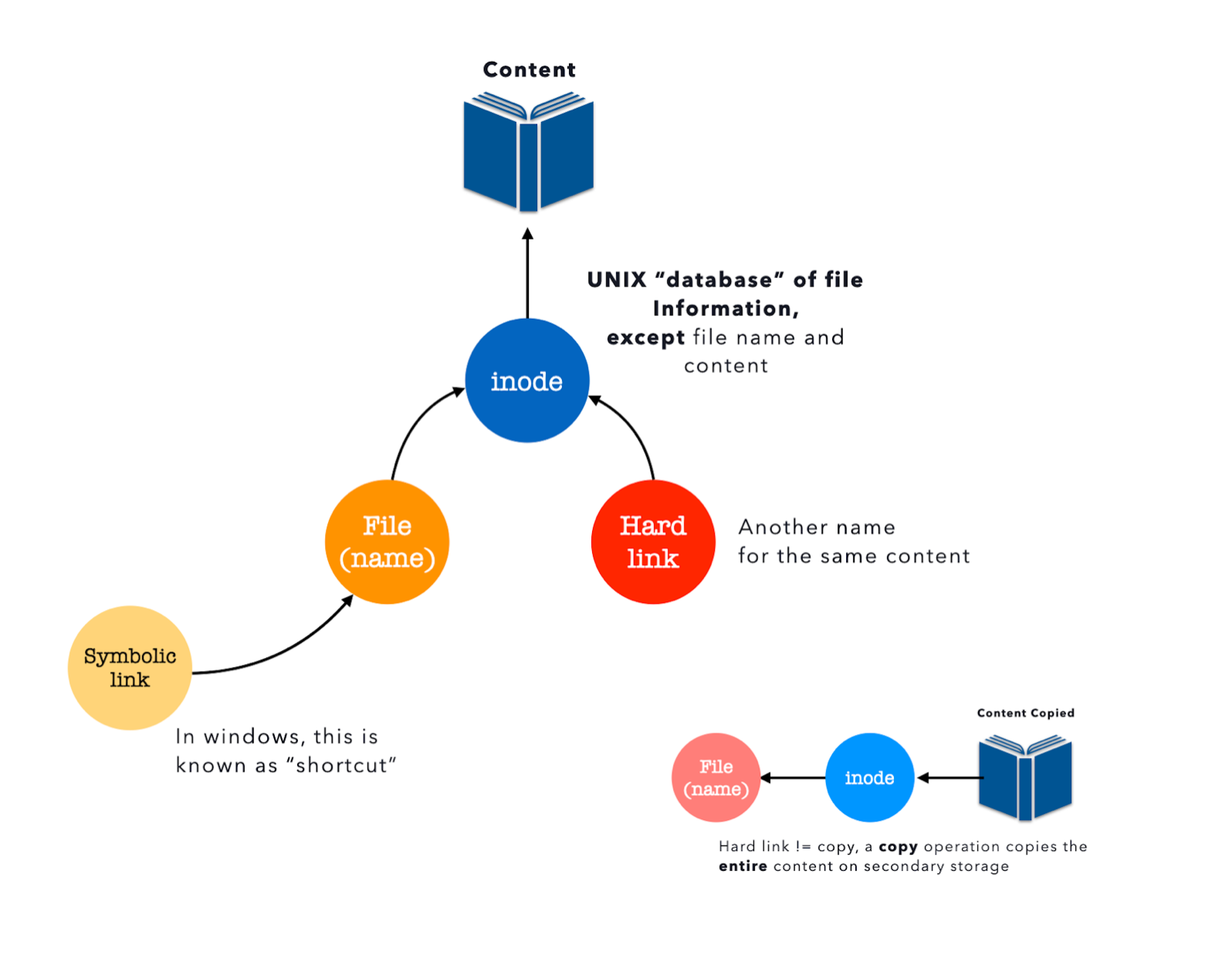
These “extra names” mapped to the same inode entry are called hard links.
Hard Links
A hard link is a feature in many file systems that allows multiple filenames to refer to the same physical location on disk. In other words, a hard link is essentially another name for an existing file.
Let’s begin with an example. A file containing helloworld characters is created, with inode 54346159. We name it input. At this point, a directory entry named input pointing to this file containing helloworld is created within the directory named Links. We call this entry the original filename.

All files in a directory-based file system must have at least one hard link (mapping) giving what we call the original name for each file.
Reference Count
Each hard link increases the reference count to the inode table entry it is pointing to by 1. Notice how after hard_link is created then the reference to inode 54346159 is 2 in the screenshot above.
Subdirectories
In some operating systems, such as Linux, when you create new subdirectories, you’re creating a new entry to the existing directory.

The reference count for subdir is 2 by default, shown in the screenshot above. UNIX-like file system will create two entries in every directory:
.pointing to the directory itself (thus increasing the reference count of itself by 1 – resulting in 2 that we see in the screenshot above)..pointing to its parent (thus increasing the reference count of its parent:Links)
Note that the above are special links, created by the OS for easy of traversal. For the sake of simplicity in this course, we ignore the presence of . and ...
This provided an easy way to traverse the filesystem, both for applications and for the OS itself.
Hard Links to Link Directories
In UNIX-like systems, you cannot create more hard links to link directories, only files. This is to prevent cycles using hard links. By effectively prohibiting multiple references to directories, UNIX-like OS like Linux maintains an acyclic-graph structure (more about this structure later). However this is not always true for all OS.

Note that .. and . can be regarded as special hard links, so although they technically points to directories (itself and the parent) we don’t treat it the same as other regular user-created hard links. Again, for the same of simplicity in this course we ignore the presence of these special links. All sections below assume that . and .. are not implemented.
Path Names
Links have path names, e.g: /Users/natalie_agus/Desktop/Links/input_hardlink.

Symbolic Links
A symbolic link is simply a file whose content is a text string (i.e: reference to another file or directory) that is automatically interpreted and followed by the operating system as a path to another file or directory.
Symbolic links are also known as “shortcuts” or “soft links”.

Symbolic Links to Link Directories
You can link directories with symbolic links, but not with hard links.
Unlike hard links, a symbolic link is NOT just a directory entry. It is a file. Of course as a consequence, this (symbolic link) file has a name and this name is a directory entry somewhere. As shown in the screenshot above, it has its own inode number: 54354162, indicating it is a new file.
File Permission
The file permission value of a symlink differs between operating systems. For instance, chmod command in Linux states that:
chmodnever changes the permissions of symbolic links; thechmodsystem call cannot change their permissions. This is not a problem since the permissions of symbolic links are never used. However, for each symbolic link listed on the command line,chmodchanges the permissions of the pointed-to file. In contrast,chmodignores symbolic links encountered during recursive directory traversals.
However on macOS, chmod does things differently. See the example below:
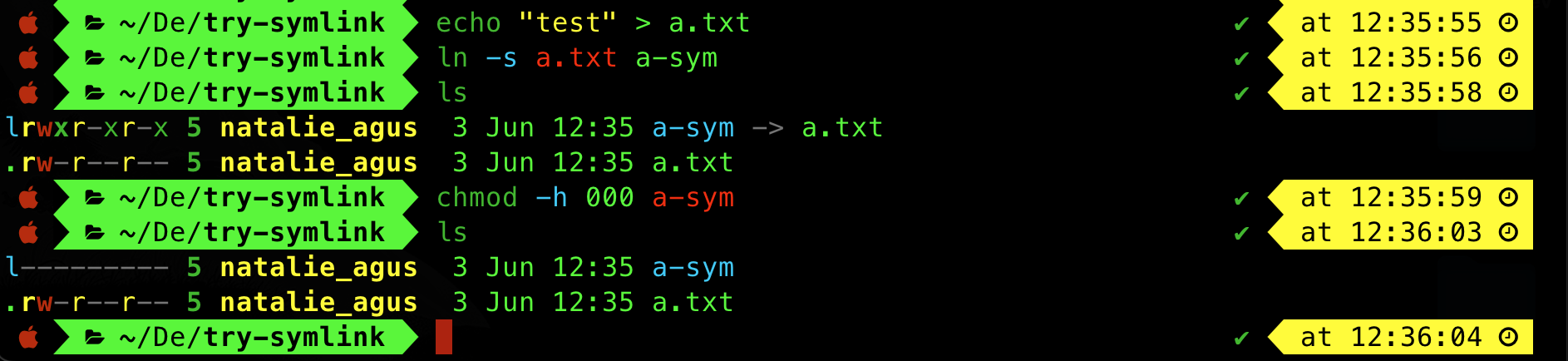
If the file is a symbolic link, chmod with a -h option changes the mode of the link itself rather than the file that the link points to. However most utilities like echo and cat follows the symlink and ignored the permission. ls however is affected. If a symlink is set to have 000 permission, ls will not print out where it’s pointing to.
On the contrary, here’s what happens on Ubuntu:
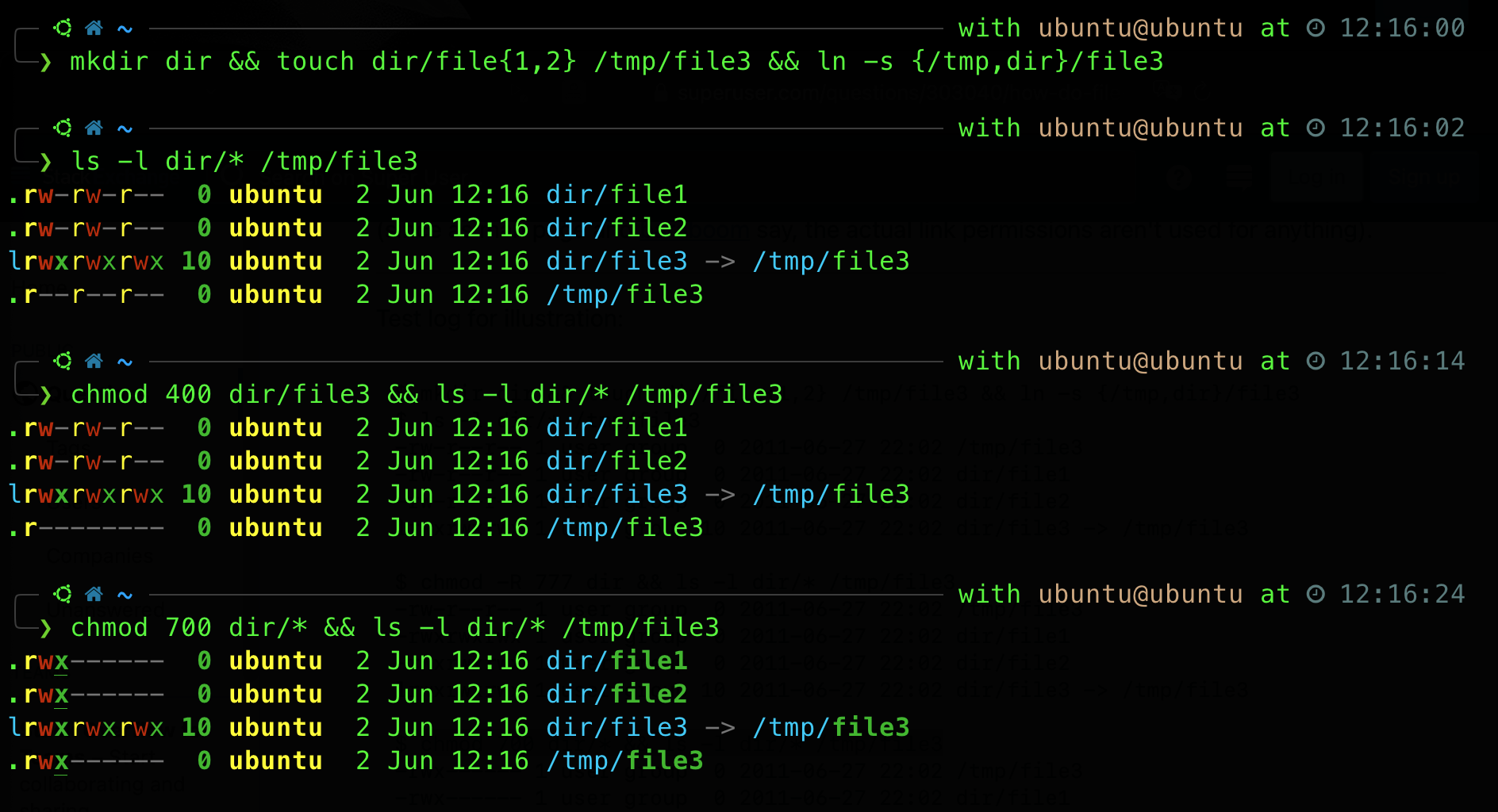
Note that these are just for illustration purposes only, there’s no need to memorise.
Link Properties
Broken Symlink
If you delete the reference hard link (file name) where the symbolic link is pointing to, the symbolic link will be broken.
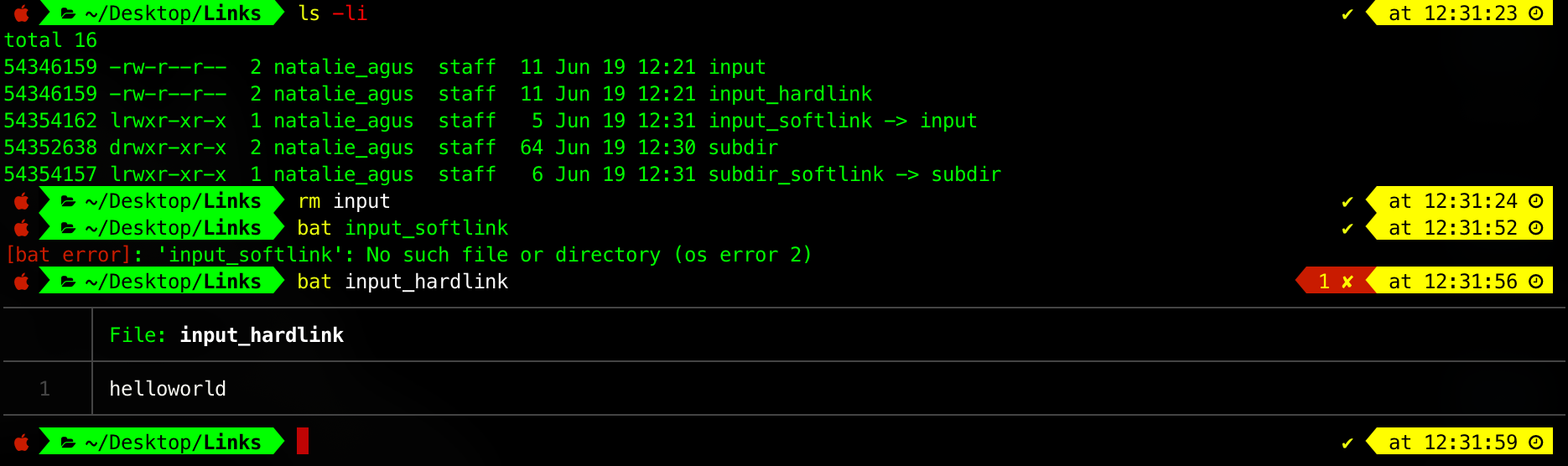
If we recreate input (file with the same name), then input_softlink will work again.

Therefore from this we can know that input_softlink is a FILE with id 54354162, which content is path to input, e.g: ~/Desktop/Links/input. It is automatically interpreted by the OS such that when you open input_softlink it will resolve ~/Desktop/Links/input and open the referred file.
Reference Count
In the example above, although input was the original filename, since there’s one more hardlink (input_hardlink) pointing to the same inode 54346159, then this file containing helloworld is not yet deleted. We can still access the file via this other hard link pointing to the same file.
Likewise, if you delete all hard links to the file, its entry in the inode table will be removed (file completely deleted, space is freed).
Why do we need links?
Hard links use case
Imagine having photos in your system, thousands of them. You want to categorize them for easier access (create different albums):
- You can categorize them as: photos of red things, photos of blue things, photos of green things.
- You can also categorize them as: photos of vehicles, photos of trees, photos of flowers
Suppose you want to categorize them both ways. What you can do: Method 1: You could create a copy of the photos and categorize it multiple times in the way you want it.
- This means you have two copies of the same file taking up two times the space.
- It is not ideal to do this, especially with large amounts of data.
Method 2: Create hard links.
- A hard link takes up almost no space at all.
- You could, therefore, store the same photo in various different categories (i.e. by color, by type, etc).
Symbolic links use case
A symbolic link is much like a desktop shortcut within Windows. The symbolic link merely points to the location of a file. We have all been using it.
Links Summary
The figure below summarizes the concept of links:
Graph Directory Structure
Acyclic Graph Directory
In acyclic graph directories, we can have the same file, but with multiple names (through symbolic/hard links).
In the graphical representation of a directory, we draw edges to represent any links, be it symbolic or hard link. This diagram is just an example. Don’t try to make much sense about the file names, they’re just arbitrary examples.
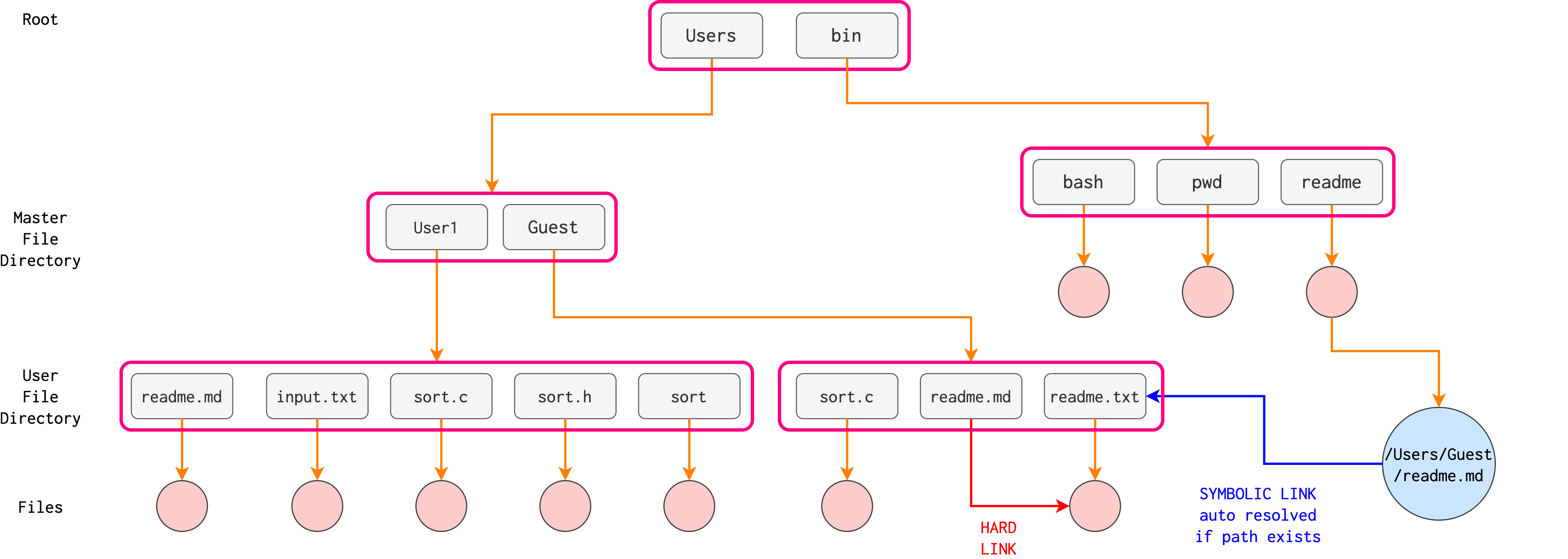
Note that Acyclic Graph Directory structure is not the same Tree Directory Structure. In Tree directory structure, we can’t have more than 1 path to reach the same file entry denoted in pink circles.
From the example above, notice that /Users/Guest/readme.md is a hard link to /Users/Guest/readme.txt and /bin/readme is a symbolic link to the same file pointed by /Users/Guest/readme.txt.
- If we do
rm /Users/Guest/readme.mdANDrm /Users/Guest/readme.txt, the underlying file is removed. The inode for this file is removed, and we can say that our file is erased. The symbolic link becomes a dangling pointer, references to a non-existent file. - If we do
rm /bin/readme, the underlying file is not removed, because there’s still another hard-link reference to the file. - The inode table entry (for the file) is completely removed only when its reference count is zero.
An inode entry cannot be deleted as long as the reference count to it is more than 0, meaning that there’s 1 or more directory entry that points to the inode entry.
General Graph Directory
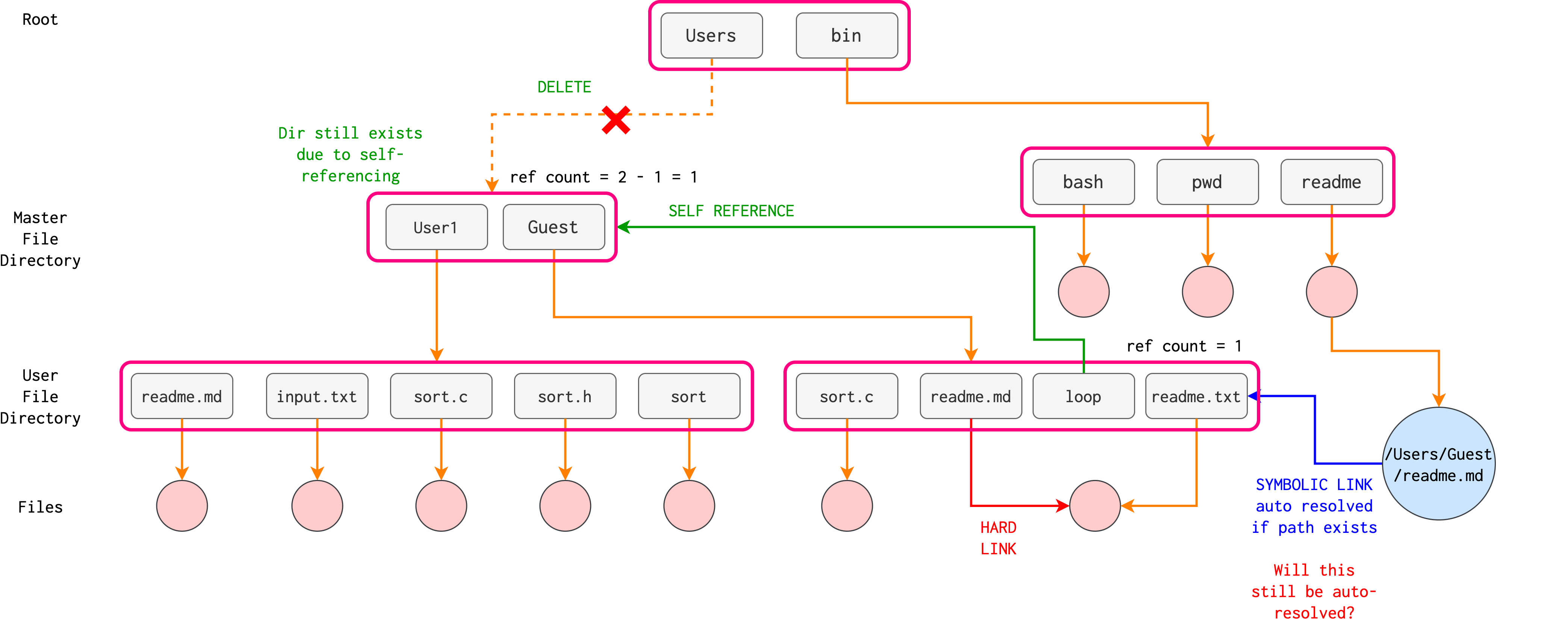
The primary advantage of an acyclic graph is the relative simplicity of the algorithms to traverse the graph and to determine when there are no more references to a file. We want to avoid traversing shared sections of an acyclic graph twice, mainly for performance reasons. The figure below illustrates a general graph directory, where loops (self referencing) are allowed for usage convenience.
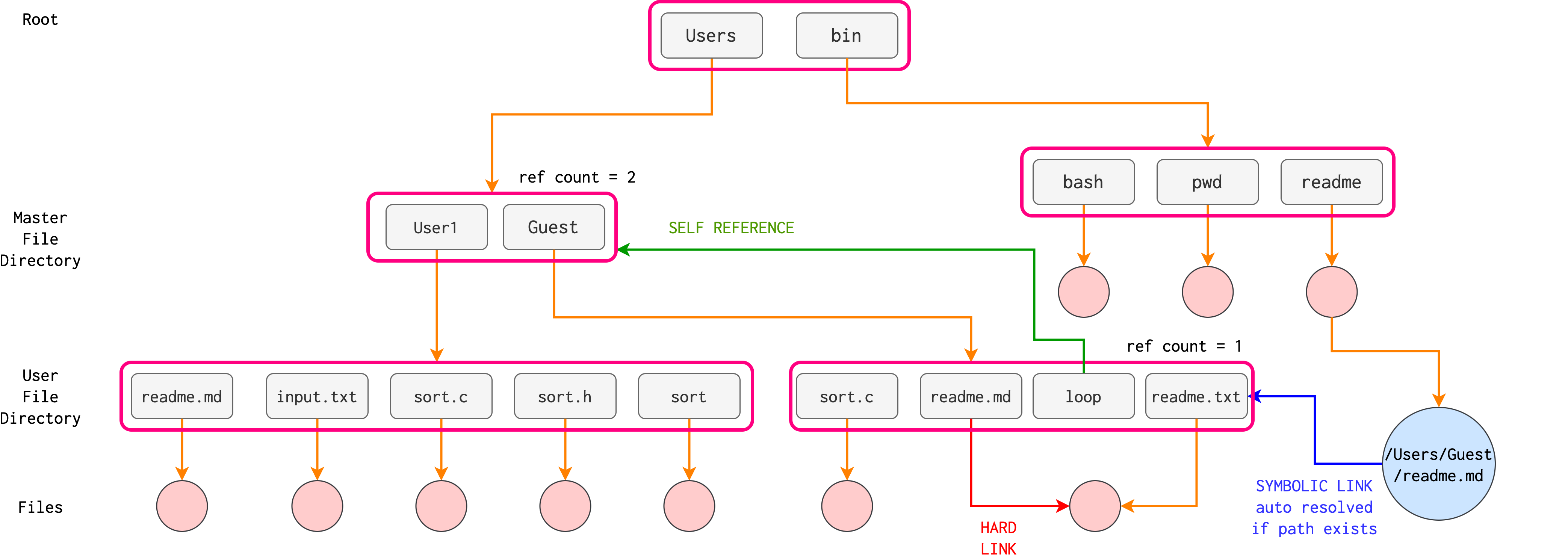
Caveat: if cycles are allowed to exist in the directory (red arrow above – can be either soft/symbolic link or hard link), we need to avoid searching any component twice or more for reasons of correctness as well as performance.
A poorly designed algorithm might result in an infinite loop continually searching through the cycle and never terminating. One solution is to limit the number of directories traversed when searching.
Self referencing
In a cyclic directory, using reference count to determine whether we need to delete a node might not work due to self referencing. You’d need other garbage-collection protocols.
For example, suppose we delete the reference edge as shown below.
This delete action will reduce the reference count of all the children of that edge (whatever node – file – that is pointed to by the edge). However due to self referencing nodes, the directory containing {User1, Guest} has their reference count set to 2 (for simplicity, we ignore reference count due to “.” and “..”).
Note that symbolic links do not increase reference count
As a result, the delete action does not reduce the reference count of this directory to zero. We are left with three inaccessible directories as shown in the image below.
Summary
Directories, also known as folders, play a crucial role in organizing and managing files within an operating system.
This chapter focuses on the concept of directories, explaining their purpose, structure, and functionality. It explores how directories are used to hierarchically organize files, providing a systematic way to navigate and access data stored on storage devices. We also discuss various directory operations, such as creating, renaming, moving, and deleting directories, elucidating their impact on file organization and system management. Additionally, we examine directory structures, including tree-based and graph-based representations, and elucidates their advantages and limitations.
Key learning points include:
- Directory Structure and Permissions: Covers the significance of directory permissions (read, write, execute) and the structure of directories including single-level, two-level, and tree-structured directories.
- File and Directory Operations: Explores operations such as creating, searching, and deleting files and directories, and explains how directories serve as a namespace to manage file organization.
- Links and Inodes: Discusses the concepts of hard and symbolic links, their use cases, and how inodes play a critical role in file system structure.
Understanding directories is essential for effectively managing file systems and ensuring efficient data organization within an operating system.