 50.005 CSE
50.005 CSE
- Resource Allocator and Coordinator: Interrupt-Driven I/O Operations
- Software Interrupt (Trap) via System Call
- Reentrant vs Preemptive Kernel
- Memory Management
- Process Management
- Providing Security and Protection
- System Structure
- Summary
- Appendix
50.005 Computer System Engineering
Information Systems Technology and Design
Singapore University of Technology and Design
Natalie Agus (Summer 2025)
Roles of Operating System Kernel
Detailed Learning Objectives
- Summarize the Role of Operating Systems
- Explain the purposes of an operating system including resource allocation, program execution control, and security enforcement.
- Outline Interrupt-Driven I/O Operations
- Define the concept of interrupt-driven I/O and differentiate between hardware and software interrupts.
- Explain the functions and benefits of vectored and polled interrupt systems.
- Describe the process of handling hardware interrupts, including the role of interrupt request lines and interrupt handlers.
- Compare vectored and polled interrupt scenarios and their suitability for different system complexities.
- Examine System Calls and Software Interrupts
- List out the role of system calls in software interrupts and their impact on process execution.
- Discuss how software interrupts (traps) facilitate interaction between user processes and the kernel.
- Explain Process Management
- Explore how the kernel manages processes to support multiprogramming and timesharing.
- Define the difference between a process and a program.
- Describe Kernel Reentrancy and Preemptiveness
- Compare reentrant and preemptive kernel operations and their implications for process management.
- Evaluate Memory and Process Management Techniques
- Discuss the implementation of virtual memory and the configuration of memory management units (MMU).
- Analyze cache performance and the role of the kernel in memory and process management.
- Assess Security and Protection Mechanisms
- Explain the mechanisms operating systems use to provide security and protection, including user identification and access control.
- Describe computer system organisation (basic architecture)
- Evaluate the differences between symmetric, asymmetric, and clustered system
These objectives aim to guide your exploration of operating system concepts, focusing on the interactions between the OS kernel and system hardware, the management of processes and memory, and the crucial role of security within computer systems.
There are several purposes of an operating system: as a resource allocator, controls program execution, and guarantees security in the computer system.
The kernel controls and coordinates the use of hardware and I/O devices among various user applications. Examples of I/O devices include mouse, keyboard, graphics card, disk, network cards, among many others.
Resource Allocator and Coordinator: Interrupt-Driven I/O Operations
Interrupt-Driven I/O operations allow the CPU to efficiently handle interrupts without having to waste resources (waiting for asynchronous IO requests). This notes explains how interrupt-driven I/O operations work in a nutshell. There are two kinds of interrupts:
- Hardware Interrupt: input from external devices activates the interrupt-request-line, thus pausing the current execution of user programs.
- Software Interrupt: a software generated interrupt that is invoked from the instruction itself because the current execution of user program needs to access Kernel services.
Hardware Interrupt

The CPU has an interrupt-request line that is sensed by its control unit before each instruction execution.
When there’s new input: from external events such as keyboard press, mouse click, mouse movement, incoming fax, or completion of previous I/O requests made by the drivers on behalf of user processes, the device controllers will invoke an interrupt request by setting the bit on this interrupt-request line.
Remember that this is a hardware interrupt: an interrupt that is caused by setting the interrupt-request line.
This forces the CPU to transfer control to the interrupt handler. This switch the currently running user-program to enter the kernel mode. The interrupt handler will do the following routine:
- Save the register states first (the interrupted program instruction) into the process table
- And then transferring control to the appropriate interrupt service routine, depending on the device controller that made the request.
Vectored Interrupt System
Interrupt-driven system may use a vectored interrupt system: the interrupt signal that INCLUDES the identity of the device sending the interrupt signal, hence allowing the kernel to know exactly which interrupt service routine to execute1. This is more complex to implement, but more useful when there is a large number of different interrupt sources that throws interrupts frequently.
This interrupt mechanism accepts an address, which is usually one of a small set of numbers for an offset into a table called the interrupt vector. This table holds the addresses of routines prepared to process specific interrupts.
With vectored interrupts, each interrupt source is associated with a unique vector address, which allows the processor to directly jump to the appropriate interrupt handler. This eliminates the need for the processor to search or iterate through a list of interrupt requests to identify the source, resulting in faster and more efficient interrupt handling. Therefore, when there are frequent interrupts from various sources, vectored interrupts can help improve the overall system performance.
Polled Interrupt System
An alternative is to use a polled interrupt system:
- The interrupted program enters a general interrupt polling routine protocol (a single entry point), where CPU scans (polls) devices to determine which device made a service request.
- Unlike vectored interrupt, there’s no such interrupt signal that includes the identity of the device sending the interrupt signal.
- The kernel must send a signal out to each controller to determine which device made a service request. It may determine the interrupt source by reading the interrupt status registers or other means.
This is simpler to implement, but more time-wasting if there’s frequent, unpredictable I/O requests only from one or some particular device in an array of devices. The CPU need to spend overhead to poll many devices. Does Linux implement a Polled interrupt or Vectored interrupt system? See here for clues.
This system may be more appropriate for systems with sparse interrupts, where there are only a few interrupt sources or the interrupts occur infrequently. In non-vectored interrupt systems, . While this approach requires more processing overhead for identifying the interrupt source, it may be sufficient and more straightforward for systems with a small number of interrupts.
Vectored Interrupt vs Polled Interrupt Scenarios
Polled interrupts are generally suitable in simple systems with a limited number of devices and low interrupt rates or predictable and moderate interrupt rates. For example, in embedded systems with a single or a few devices generating interrupts infrequently, such as basic sensor input or user interactions, polled interrupts can be sufficient.
Vectored interrupts are commonly used in more complex systems with multiple devices generating interrupts frequently. They are suitable when efficient handling of multiple interrupts and reduced latency are crucial, such as in high-performance systems, real-time operating systems, or systems with time-sensitive tasks.
Multiple Interrupts
If there’s more than one I/O interrupt requests from multiple devices, the Kernel may decide which interrupt requests to service first. When the service is done, the Kernel scheduler may choose to resume the user program that was interrupted.
Raw Device Polling
It takes time to perform a mode switch to handle interrupt requests. In some specifically dedicated servers, raw polling may be faster. The CPU periodically checks each device for requests. If there’s no request, then it will return to resume the user programs. Obviously, this method is not suitable in the case of sporadic I/O usage, or in general-purpose CPUs since at least a fixed bulk of the CPU load will always be dedicated to perform routine polling. For instance, there’s no need to poll for anything periodically when a user is watching a video.
Modern computer systems are interrupt-driven, meaning that it does not wait until the input from the requested external device is ready. This way, the computer may efficiently fetch I/O data only when the devices are ready, and will not waste CPU cycles to “poll” whether there are any I/O requests or not.
Hardware Interrupt Timeline
The figure below summarises the interrupt-driven procedure of asynchronous I/O handling during hardware interrupt:
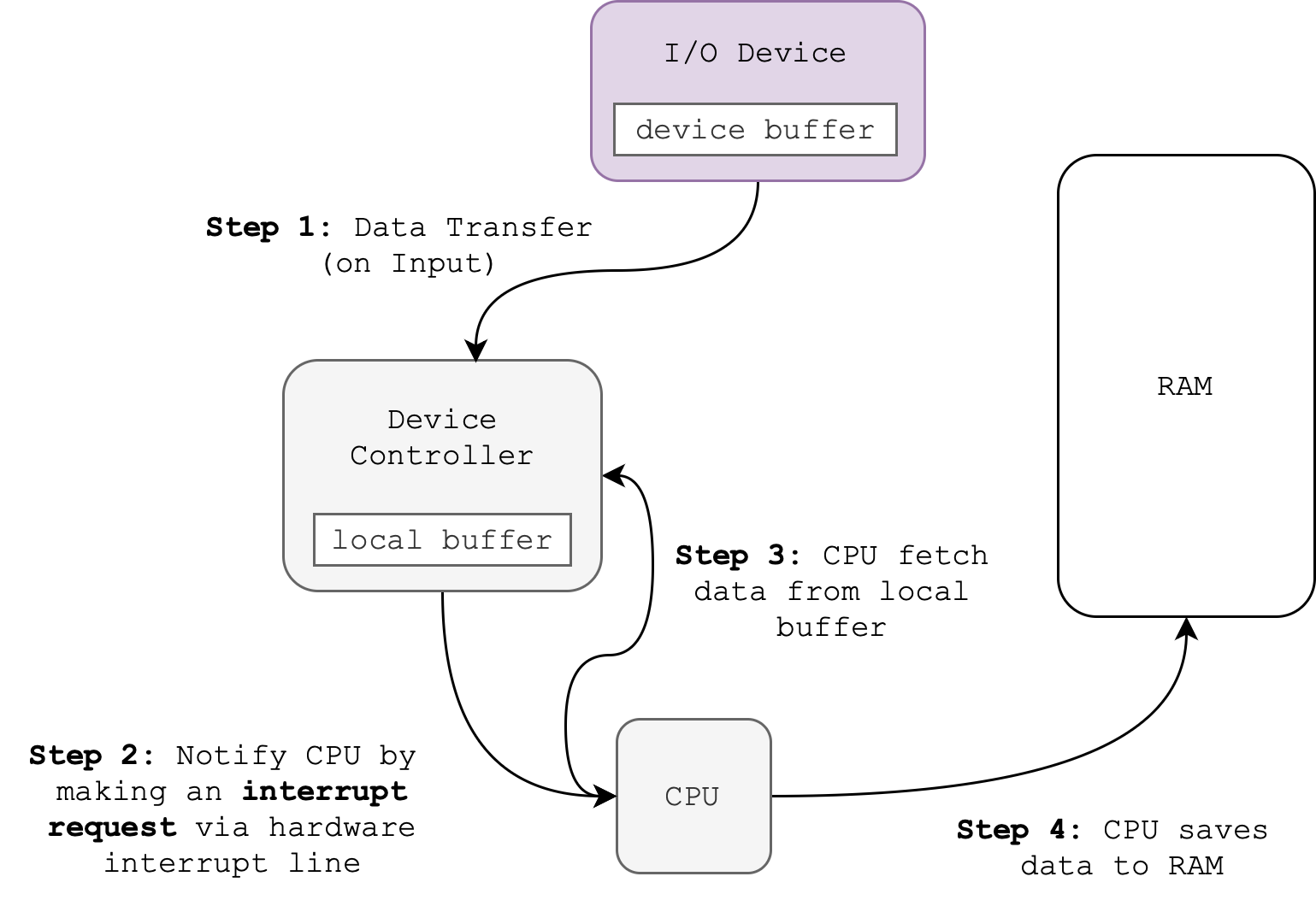
Notes:
- I/O Devices: External I/O Device, e.g: printer, mouse, keyboard. Runs asynchronously, capable of being “smart” and run its own instructions.
- Device Controller: Attached to motherboard. Runs asynchronously, may run simple instructions. Has its own buffers, registers, and simple instruction interpreter. Usually transfer data to and fro the I/O device via standard protocols such as USB A/C, HDMI, DP, etc.
- Disk Controller: Same as device controller, just that it’s specific to control Disks
Receiving asynchronous Input
From the figure above, you may assume that at first the CPU is busy executing user process instructions. At the same time, the device is idling.
Upon the presence of external events, e.g: mouse CLICK(), the device records the input. This triggers step 1: The I/O device sends data to the device controller, and transfers the data from the device buffer to the local buffer of the device controller.
When I/O transfer is complete, this triggers step 2: the device controller makes an interrupt request to signal that a transfer is done (and data needs to be fetched). The simplest way for the device controller to raise an interrupt is by asserting a signal on the interrupt request line (this is why we define I/O interrupts as hardware generated)
The interrupt request line is sensed by the CPU at the beginning of each instruction execution, and when there’s an interrupt, the execution of the current user program is interrupted. Its states are saved2 by the entry-point of the interrupt handler. Then, this handler determines the source of the interrupt (be it via Vectored or Polling interrupt) and performs the necessary processing. This triggers step 3: the CPU executes the proper I/O service routine to transfer the data from the local device controller buffer to the physical memory.
After the I/O request is serviced, the handler:
- Clears the interrupt request line,
- Performs a state restore, and executes a return from interrupt instruction (or
JMP(XP)as you know it from 50.002).
Consuming the Input
Two things may happen from here after we have stored the new input to the RAM:
- If there’s no application that’s currently waiting for this input, then it might be temporarily stored somewhere in kernel space first.
- If there is any application that is waiting (blocked, like Python’s
input()) for this input (e.g: mouse click), that process will be labelled as ready. For example, if the application is blocked upon waiting for this new input, then the system call returns. We will learn more about this in Week 3.
One thing should be crystal clear: in an interrupt-driven system, upon the presence of new input, a hardware interrupt occurs, which invokes the interrupt handler and then the interrupt service routine to service it. It does not matter whether any process is currently waiting for it or not. If there’s a process that’s waiting for it, then it will be scheduled to resume execution since its system call will return (if the I/O request is blocking).
Software Interrupt (Trap) via System Call
Firstly, this image says it all.

Sometimes user processes are blocked from execution because it requires inputs from IO devices, and it may not be scheduled until the presence of the required input arrives. For example, this is what happens if you wait for user input in Python:
inp = input("Enter your name:")
print(inp)
Running it will just cause your program to be stuck in the console, why:
bash-3.2$ python3 test.py
Enter your name:
User processes may trap themselves e.g: by executing an illegal operation (ILLOP) implemented as a system call, along with some value in designated registers to indicate which system call this program tries to make.
The details on which register, or what value should be put into these registers depends on the architecture of your CPU. This detail is not part of our syllabus.
Traps are software generated interrupts, that is some special instructions that will transfer the mode of the program to the Kernel Mode.
The CPU is forced to go to a special handler that does a state save and then execute (may not be immediate!) on the proper interrupt service routine to handle the request (e.g: fetch user input in the python example above) in kernel mode. Software interrupts generally have low priority, as they are not as urgent as devices with limited buffering space.
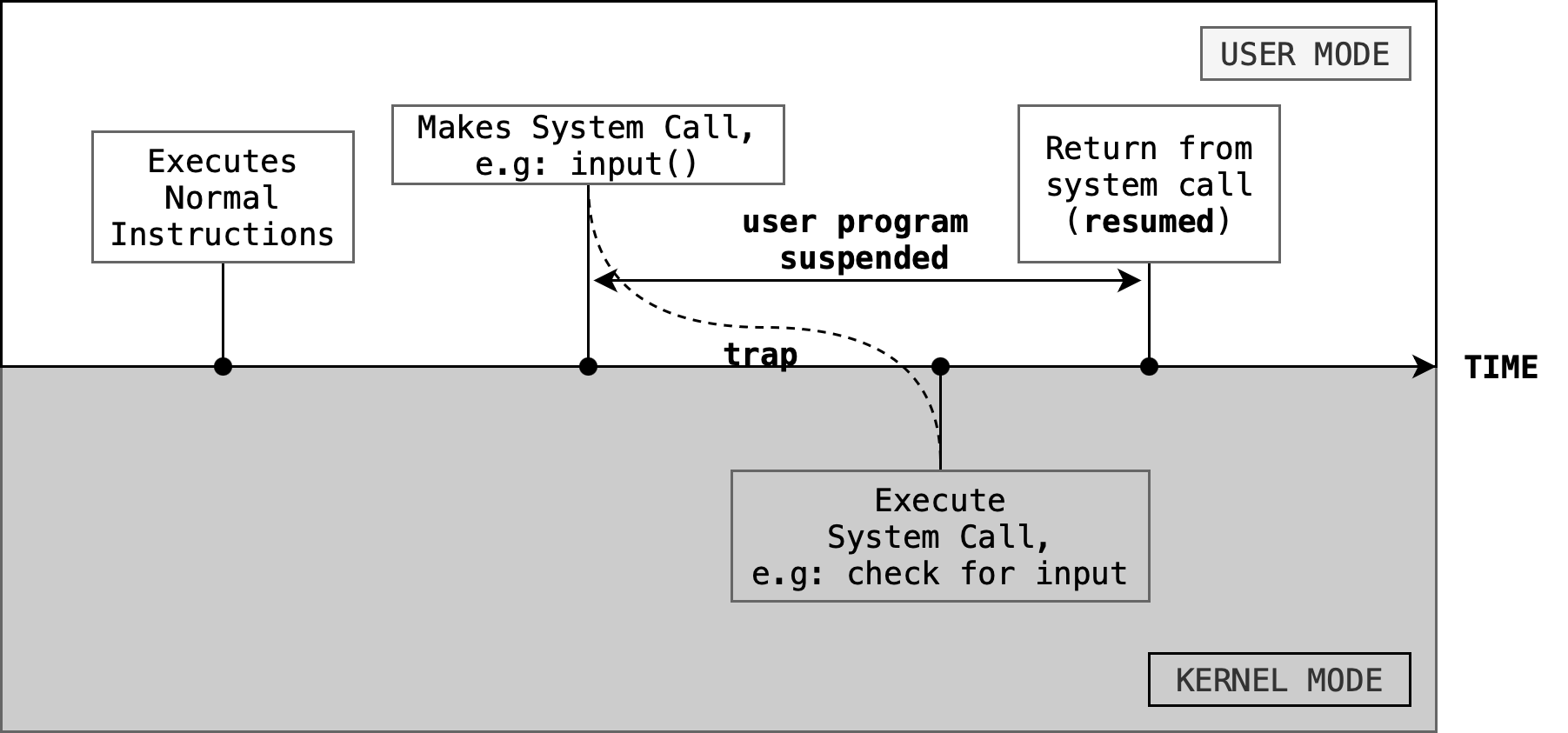
During the time between system call request until system call return, the program execution is paused. Examples of system calls are: chmod(), chdir(), print(). More Linux system calls can be found here.
Combining Hardware Interrupt and Trap
Consider another scenario where you want to open a very large file from disk. It takes some time to load (simply transfer your data from disk to the disk controller), and your CPU can proceed to do other tasks in the meantime. Here’s a simplified timeline:
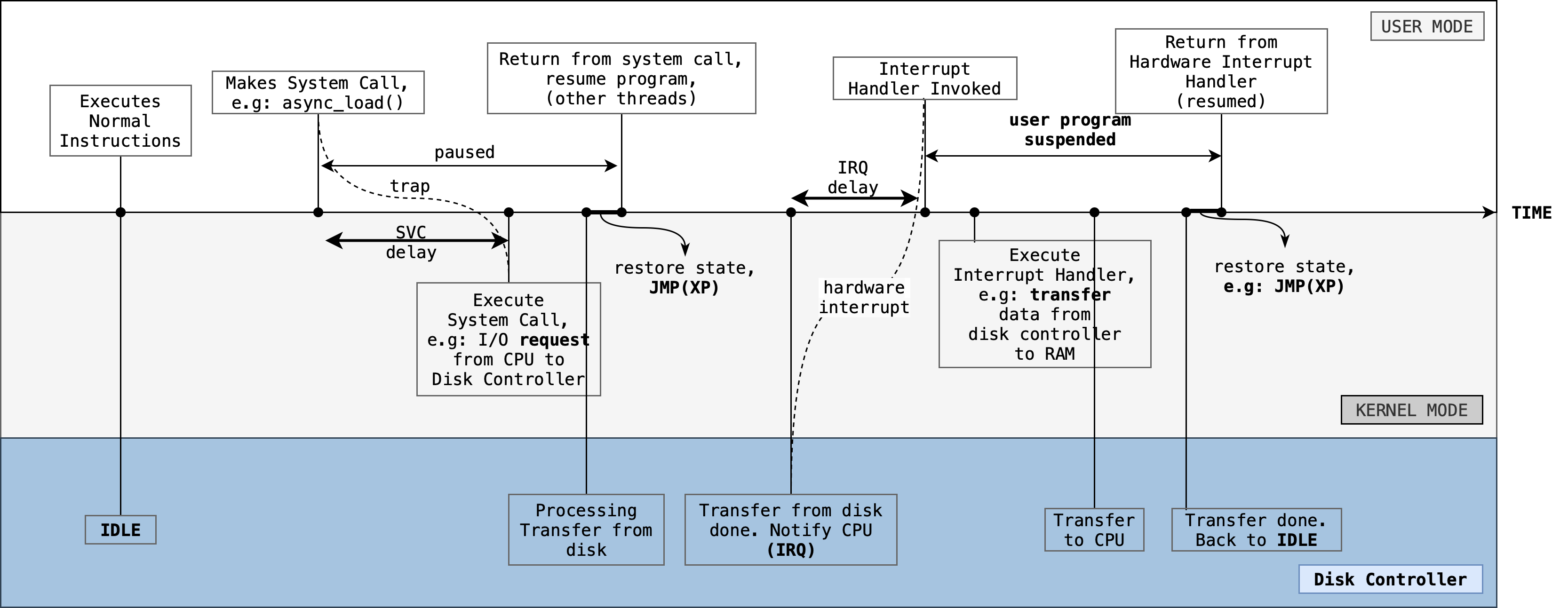
Imagine that at first, the CPU is busy executing process instructions in user mode. At the same time, the device is idling.
- The process requests for Kernel services (e.g: load data asynchronously) by making a system call.
- The context of the process are saved by the trap handler
- Then, the appropriate system call service routine is called. Here, they may require to load appropriate device drivers so that the CPU may communicate with the device controller.
- The device controller then makes the instructed I/O request to the device itself on behalf of the CPU, e.g: a disk, as instructed.
- Meanwhile, the service handler returns and may resume the calling process as illustrated.
The I/O device then proceeds on responding to the request and transfers the data from the device to the local buffer of the device controller.
When I/O transfer is complete, the device controller makes a hardware interrupt request to signal that the transfer is done (and data needs to be fetched). The CPU may respond to it by saving the states of the currently interrupted process, handle the interrupt, and resume the execution of the interrupted process.
- The interrupt handler simply migrates the data from controller into the RAM (Kernel space)
- It does not directly notify the requesting process, but instead the step is more complex (see next section), depending on the type resource (data) requested.
Note:
- SVC delay and IRQ delay: time elapsed between when the request is invoked until when the request is first executed by the CPU.
- Before the user program is resumed, its state must be restored. Saving of state during the switch between User to Kernel mode is implied although it is not drawn.
When Will the Requesting Process Gets the Resource?
When a user program performs a blocking system call like read() or recv(), it often ends up waiting for an external event such as keyboard input, network data, or disk I/O to become available. Behind the scenes, the operating system handles these events asynchronously as explained above via hardware interrupts. However, it’s not the interrupt handler itself that directly resumes the process.
Instead, each type of resource (e.g., TTYs, sockets, files) is managed by a specific kernel subsystem that takes responsibility for buffering the data, tracking which processes are waiting, and waking them up when the event completes. This design allows the kernel to efficiently manage many concurrent I/O operations, each linked to its own wait queue and triggered by different types of interrupts or internal signals.
The table below summarizes the type of data and Kernel subsystem responsible to wake the requesting process:
This is FYI only, there’s no need to memorize this table. It is not put into appendix because we would want you to understand the notion of interrupt-driven system by example.
| Asynchronous Event Source | Example Blocking Syscall | Who Handles the Interrupt/Event | Who Wakes Up the Blocked Process | Typical Wait Queue Owner |
|---|---|---|---|---|
| Keyboard | read(0, buf, n) (TTY stdin) |
IRQ1 → Keyboard Interrupt Handler | TTY Line Discipline (e.g., n_tty.c) |
TTY device struct / line discipline |
| Mouse/Touchpad | read() on input device |
Input device IRQ → input subsystem | Input handler | Input device driver |
| Disk I/O Completion (HDD/SSD) | read() from file |
Block device IRQ → block layer | VFS / I/O scheduler / bio completion | File / page cache / inode |
| Socket Data Arrival (TCP/UDP) | recv(), read() |
NIC IRQ → network stack | Socket layer (e.g., tcp_recvmsg()) |
Socket struct |
| Pipe/FIFO Write | read() from pipe |
No IRQ, this is user-level write() call |
Pipe driver (e.g., pipe_read(), pipe_write()) |
Pipe buffer (anon inode) |
| Child Process Exit | wait() / waitpid() |
No IRQ, process exit triggers internal signal | do_wait() subsystem in kernel/exit.c |
Parent process wait queue |
| Timer Expiry (alarm, sleep) | sleep(), nanosleep() |
APIC / timer IRQ → timer subsystem | Timerfd or kernel timer list handler | Timer wait queue / scheduler’s internal queue |
| File Descriptor Ready (epoll) | epoll_wait() |
Varies (underlying fd event) | ep_poll_callback() in fs/eventpoll.c |
Epoll instance’s internal wait queue |
| Signal Delivery | pause(), sigsuspend() |
Hardware or software signal (e.g., Ctrl+C) | Signal handling logic in signal.c |
Task’s signal wait queue |
| Eventfd | read() on eventfd |
Another thread writes to eventfd | Eventfd subsystem (fs/eventfd.c) |
Eventfd struct |
| Inotify/Fanotify | read() on inotify fd |
File system triggers internal event | Inotify handler | Inotify watch struct |
| USB Device Event | read() or device open |
USB IRQ → USB core | USB class driver (e.g., HID, storage) | USB device driver |
| GPU Event / VBlank | poll() on DRM/KMS fd |
GPU IRQ → DRM subsystem | DRM event queue manager | DRM file-private object |
| Audio Input/Output Ready | ALSA read/write | Audio device IRQ | ALSA PCM layer | ALSA runtime struct |
| Serial Port Data | read() on /dev/ttyS* |
UART IRQ → serial driver | TTY serial line discipline | Serial TTY driver |
The key takeaway is that interrupt handlers to not wake processes directly. They signal the appropriate subsystem who tracks which processes are waiting and performs wake_up() when conditions are met (data ready, EOF, etc.). Each resource (socket, tty, pipe, etc) maintains its own wait queue and the syscall handler (read(), recv(), etc.) puts the process to sleep on it. We will learn more about this in the next chapter (Processes).
Exceptions
Exceptions are software interrupts that occur due to errors in the instruction: such as division by zero, invalid memory accesses, or attempts to access kernel space illegally. This means that the CPU’s hardware may be designed such that it checks for the presence of these serious errors, and immediately invokes the appropriate handler via a pre-built event-vector table.
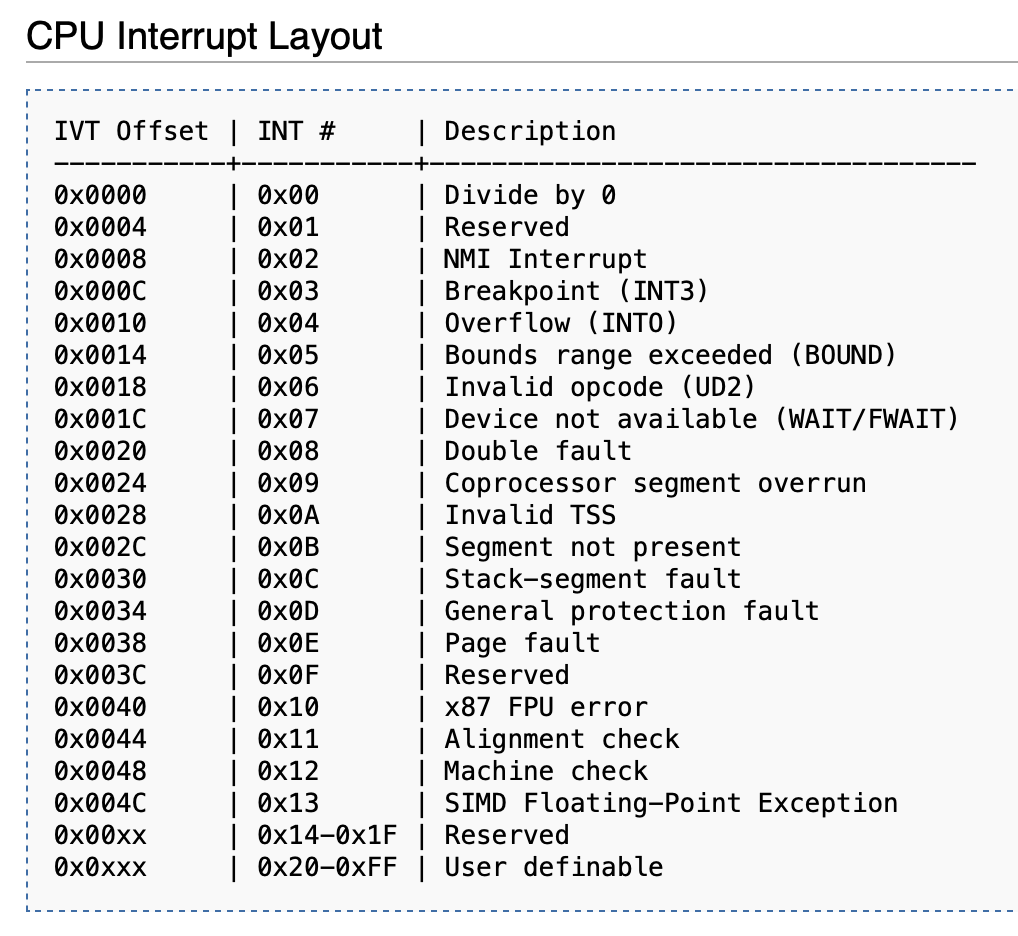
Interrupt Vector Table (IVT)
Definition
The IVT is a table of pointers to interrupt service routines (ISRs) used to handle interrupts in computing systems.
Purpose: Allows efficient handling of hardware and software interrupts by directing the processor to the appropriate ISR.
Structure: Comprises entries, each corresponding to a specific interrupt vector; each entry points to an ISR.
Location: Often found at a fixed memory address, particularly in systems like the Intel x86 in real mode.
Function: On an interrupt, the system uses the interrupt number to index into the IVT, fetch the ISR address, and execute the routine to address the event.
Generally speaking, CPU must be configured to receive interrupts (IRQs) and invoke correct interrupt handler using the Interrupt Vector Table (IVT). Operating system kernel must provide Interrupt Service Routines (ISRs) to handle interrupts.
Sometimes you might encounter the term IDT instead of IVT. The interrupt descriptor table (IDT) is a data structure used by the x86 architecture to implement an interrupt vector table.
Head to the appendix to learn more about actual implementation of IVT in different architecture.
Reentrant vs Preemptive Kernel
Reentrancy
A reentrant kernel is the one which allows multiple processes to be executing in the kernel mode at any given point of time (concurrent) without causing any consistency problems among the kernel data structures. This requires shared kernel structures such as the process table, file table, ready queue, and buffers to be protected properly. If the kernel is non re-entrant, the kernel is not designed to handle multiple overlapping system calls. A process could still be suspended in kernel mode, but that would mean that it blocks kernel mode execution on all other processes. No other processes can make system calls (will be put to wait) until the suspended process in kernel mode resumes and returns from the system call.
Head to appendix if you’d like to view a simple example of a reentrant Kernel that supports concurrency.
For example, consider Process 1 that is voluntarily suspended when it is in the middle of handling its read system call because the it has to wait for some data from disk to become available. It is suspended in Kernel Mode by yielding itself. Another Process 2 is now scheduled and wishes to make print system call.
- In a reentrant kernel: Process 2 is currently executed; able to execute its
printsystem call. - In a non-reentrant kernel: Process 2, although currently executed must wait for Process 1 to exit from the Kernel Mode if Process 2 wishes to execute its
printsystem call.
Preemption
A pre-emptive Kernel allows the scheduler to interrupt processes in Kernel mode to execute the highest priority task that are ready to run, thus enabling kernel functions to be interrupted just like regular user functions. The CPU will be assigned to perform other tasks, from which it later returns to finish its kernel tasks. In other words, the scheduler is permitted to forcibly perform a context switch.
This is more difficult than blocking reentrancy because the kernel code may be stopped at almost any point, so shared kernel data must be carefully protected with locks or interrupt disabling.
Likewise, in a non-preemptive kernel the scheduler is not capable of rescheduling a task while its CPU is executing in the kernel mode.
Using the same example of Process 1 and 2 above, assume a scenario whereby there’s a periodic scheduler interrupt to check which Process may resume next. Assume that Process 1 is in the middle of handling its read system call when the timer interrupts.
- In a non-preemptive Kernel: If Process 1 does not voluntarily
yieldwhile it is still in the middle of its system call, then the scheduler will not be able to forcibly interrupt Process 1. - In a preemptive Kernel: When Process 2 is ready, and it is time to schedule Process 2 or if Process 2 has a higher priority than Process 1, then the scheduler may forcibly suspend Process 1.
A kernel can be reentrant but not preemptive: That is if each process voluntarily yield after some time while in the Kernel Mode, thus allowing other processes to progress and enter Kernel Mode (make system calls) as well. However, a kernel should not be preemptive and not reentrant (it doesn’t make sense!).
A preemptive kernel allows processes to be interrupted at any time, requiring the kernel to handle multiple simultaneous executions of its code safely. A non-reentrant kernel cannot handle concurrent execution of kernel code, leading to data corruption and instability if preempted. Thus, a kernel must be reentrant to function correctly in a supposed preemptive environment.
We can of course work around it by disallowing any other processes to make system calls when another process is currently suspended in Kernel Mode (eg: forcibly switched by scheduler in the middle of handling its system call). This setup avoids concurrent executions of kernel code but lead to inefficiencies and delayed response times: rendering the “preemptive kernel feature” useless.
Fun fact: Linux Kernel is reentrant and preemptive.
In simpler Operating Systems, incoming hardware interrupts are typically disabled while another interrupt (of same or higher priority) is being processed to prevent a lost interrupt i.e: when user states are currently being saved before the actual interrupt service routine began or various reentrancy problems3. Disabling hardware interrupts during critical moments like context switching typically indicates a non-preemptive kernel.
Memory Management
The Kernel has to manage all memory devices in the system (disk, physical memory, cache) so that they can be shared among many other running user programs. The hierarchical storage structure requires a concrete form of memory management since the same data may appear in different levels of storage system.
Virtual Memory Implementation
The kernel implements the Virtual Memory. It has to:
- Support demand paging protocol
- Keep track of which parts of memory are currently being used and by whom
- Decide which processes and data to move into and out of memory
- Mapping files into process address space
- Allocate and deallocate memory space as needed
- If RAM is full, migrate some contents (e.g: least recently used) onto the swap space on the disk
- Manage the pagetable and any operations associated with it.
CPU caches are managed entirely by hardware (cache replacement policy, determining cache HIT or MISS, etc). Depending on the cache hardware, the kernel may do some initial setup (caching policy to use, etc).
Configuring the MMU
The MMU (Memory Management Unit) is a computer hardware component that primarily handles translation of virtual memory address to physical memory address. It relies on data on the system’s RAM to operate: e.g utilise the pagetable. The Kernel sets up the page table and determine rules for the address mapping.
Recall from 50.002 that the CPU always operates on virtual addresses (commonly linear, PC+4 unless branch or JMP), but they’re translated to physical addresses by the MMU. The Kernel is aware of the translations and it is solely responsible to program (configure) the MMU to perform them.
Cache Performance
Caching is an important principle of computer systems. We perform the caching algorithm each time the CPU needs to execute a new piece of instruction or fetch new data from the main memory. Remember that cache is a hardware, built in as part of the CPU itself in modern computers as shown in the figure below:
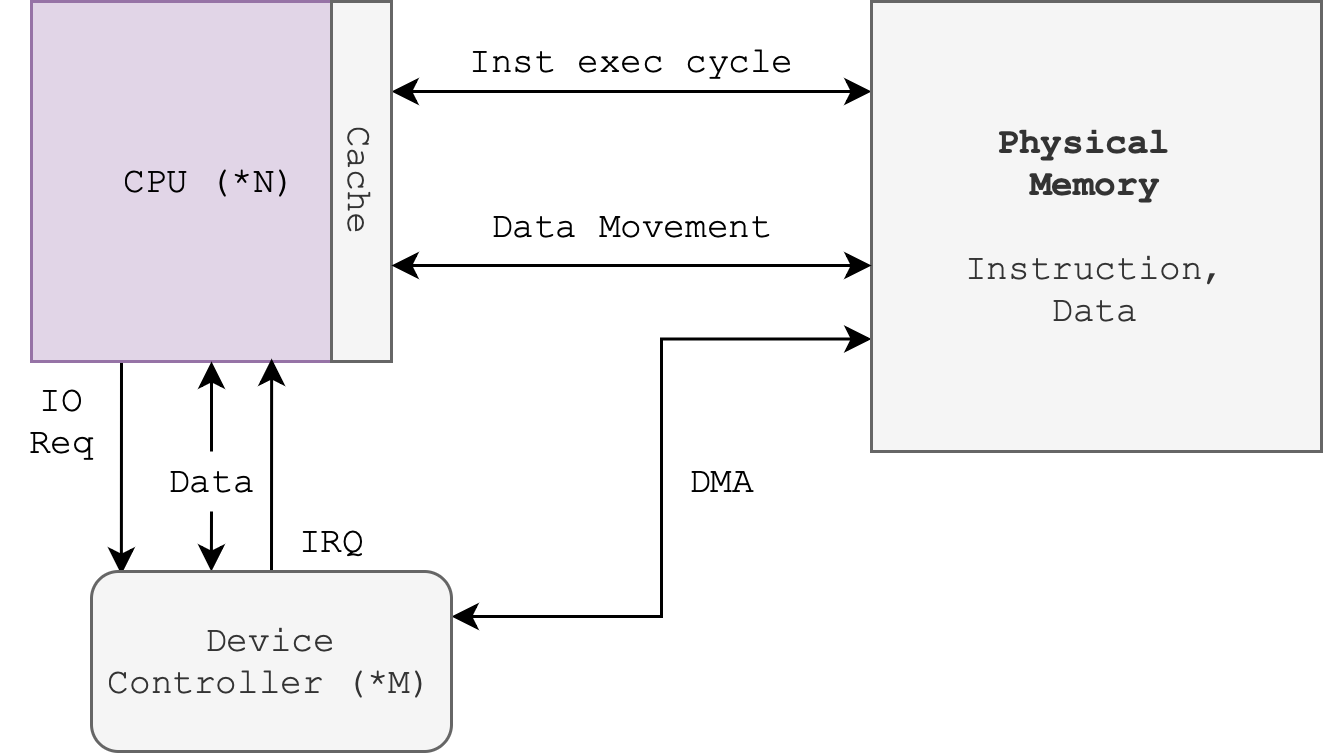
Note that “DMA” means direct memory access from the device controller onto the RAM4 (screenshot taken from SGG book).
Data transfer from disk to memory and vice versa is usually controlled by the kernel (requires context switching), while data transfer from CPU registers to CPU cache5 is usually a hardware function without intervention from the kernel. There is too much overhead if the kernel is also tasked to perform the latter.
Recall that the Kernel is responsible to program and set up the cache and MMU hardware, and manage the entire virtual memory. Kernel memory management routines are triggered when processes running in user mode encounter page-fault related interrupts. Careful selection of the page size and of a replacement policy can result in a greatly increased performance.
Given a cache hit ratio $\alpha$, cache miss access time $\epsilon$, and cache hit access time $\tau$, we can compute the cache effective access time as:
\[\alpha \tau + (1-\alpha) \times \epsilon\]Example
Suppose we have a hit rate of $\alpha = 0.5$, cache access time of 20ms, and RAM access time of 100 ms. What is the effective access time of this system?
In this case, $\epsilon = 20 + 100 = 120ms$ (cache miss time). Cache miss time includes the cache access time because we would have spent 20ms to check the cache in the first place to know that it’s a cache miss. Therefore, the effective access time is 70ms.
Process Management
The Kernel is also responsible for managing all processes in the system and support multiprogramming and timesharing feature.
Multiprogramming and time-sharing are both concepts in operating systems that aim to improve the efficiency and responsiveness of computer systems by managing how processes are executed. However, they differ in their goals, implementation, and user experience.
Multiprogramming
Goal: Increase CPU utilization and system throughput.
Multiprogramming involves running multiple programs (or processes) on a single processor system, a concept that is needed for efficiency. The operating system keeps several jobs in memory simultaneously. When one job waits for I/O operations to complete, the CPU can execute another job. This approach maximizes CPU usage by reducing idle time.
A kernel that supports multiprogramming increases CPU utilization by organizing jobs (code and data) so that the CPU always has one to execute. When one job waits for I/O operations to complete, the CPU can execute another job instead of idling.
Simplified implementation:
- The OS maintains a pool of jobs in the job queue.
- Jobs are selected and loaded into memory.
- The CPU switches between jobs when they are waiting for I/O, ensuring that it is always busy executing some job.
- Jobs are executed until they are complete or require I/O operations, at which point another job is scheduled.
- For example in diagram below, CPU will continue to run Job 3 as long as Job 3 does not
waitfor anything else.- When Job 3 waits for some I/O operation in the future, CPU will switch to READY jobs, e.g: either Job 1 or Job 2 (assuming Job 4 is still waiting then)

Practical Consideration
Since the clock cycles of a general purpose CPU is very fast (in Ghz), we don’t actually need 100% CPU power in most case. It is often too fast to be dedicated for just one program for the entire 100% of the time. Hence, if multiprogramming is not supported and each process has a fixed quantum (time allocated to execute), then the CPU might spend most of its time idling.
The kernel must organise jobs (code and data) efficiently so CPU always has one to execute. A subset of total jobs in the system is kept in memory and swap space of the disk.
Remember: Virtual memory allows execution of processes not completely in memory. One job is selected per CPU and run by the scheduler.
When a particular job has to wait (for I/O for example), context switch is performed.
- For instance, Process A asked for user
input(), enters Kernel Mode via supervisor call - If there’s no input, Process A is suspended and context switch is performed (instead of returning back to Process A)
- If we return to Process A, since Process A cannot progress without the given input, it will invoke another
input()request again – again and again until the input is present. This will waste so much resources
Context switch is the routine of saving the state of a process, so that it can be restored and resumed at a later point in time. For more details on what this state comprised of, see Week 2 notes.
User Experience: Users might experience delays as the system prioritizes CPU utilization over interactive performance. The system is not designed to provide immediate feedback.
Timesharing
Goal: Provide interactive user experience and fast response times.
Naturally, multiprogramming allows for timesharing. Time-sharing extends the concept of multiprogramming by allowing multiple users to interact with the system simultaneously. The CPU time is divided into small time slices (or quanta), and each user program is given a slice of time. The OS rapidly switches between user programs, giving the illusion that each user has their own dedicated machine.
Timesharing: context switch that’s performed so rapidly that users still see the system as interactive and seemingly capable to run multiple processes despite having limited number of CPUs.
Simplified implementation:
- The OS maintains a list of active user processes.
- The CPU scheduler allocates a fixed time slice to each process in a round-robin fashion.
- If a process’s time slice expires, the CPU switches to the next process in the queue.
- Processes that need I/O or user input can be interrupted and put into a waiting state, allowing other processes to use the CPU.
- For example in the diagram below, the CPU will run each job for a fixed quanta
tand switch to another (ready) job once that time slice ends:
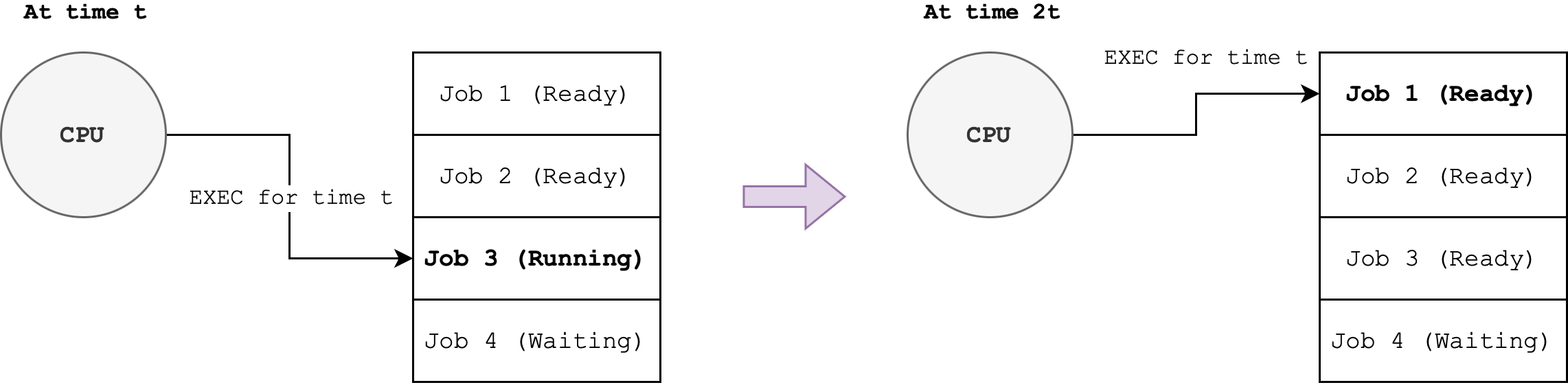
User Experience: Users experience a responsive system as the OS ensures that each user program gets regular CPU time. Interactive tasks, such as typing or browsing, feel immediate because the OS switches between tasks quickly.
Further Consideration
Multiprogramming alone does not necessarily provide for user interaction with the computer system. For instance, even though the CPU has something to do, it doesn’t mean that it ensures that there’s always interaction with the user, e.g: a CPU can run background tasks at all times (updating system time, monitoring network traffic, etc) and not run currently opened user programs like the Web Browser and Telegram.
Timesharing is the logical extension of multiprogramming. It results in an interactive computer system, which provides direct communication between the user and the system.
Key Differences
| Feature | Multiprogramming | Time-Sharing |
|---|---|---|
| Primary Goal | Maximize CPU utilization and throughput | Provide responsive, interactive user experience |
| User Interaction | Minimal, often non-interactive (batch processing) | High, interactive user experience |
| CPU Scheduling | Job-based, switches when I/O is needed | Time-based, fixed time slices (quanta) |
| Response Time | Can be longer, not optimized for interactivity | Short, optimized for user interaction |
| Implementation | Multiple jobs loaded in memory, CPU switches on I/O | Multiple user processes, rapid context switching |
| Examples | Early mainframe systems, batch processing | Modern operating systems, interactive applications |
While both multiprogramming and time-sharing aim to improve the efficiency of CPU utilization, they serve different purposes. Multiprogramming focuses on maximizing CPU usage by running multiple jobs simultaneously, often in a batch processing environment. Time-sharing, on the other hand, aims to provide a responsive, interactive experience for multiple users by rapidly switching between processes, giving the illusion of concurrent execution.
Process vs Program
A process is a program in execution. It is a unit of work within the system, and a process has a context (regs values, stack, heap, etc) while a program does not.
A program is a passive entity, just lines of instructions while a process is an active entity, with its state changing over time as the instructions are executed.
A program resides on disk and isn’t currently used. It does not take up resources: CPU cycles, RAM, I/O, etc while a process need these resources to run.
- When a process is created, the kernel allocate these resources so that it can begin to execute.
- When it terminates, the resources are freed by the kernel, such as RAM space is freed, so that other processes may use the resources.
- A typical general-purpose computer runs multiple processes at a time.
If you are interested to find the list of processes in your Linux system, you can type top in your terminal to see all of them in real time. A single CPU achieves concurrency by multiplexing (perform rapid context switching) the executions of many processes.
Kernel is not a process by itself
It is easy to perhaps misunderstand that the kernel is a process.
The kernel is not a process in itself (albeit there are kernel threads, which runs in kernel mode from the beginning until the end, but this is highly specific, e.g: in Solaris OS).
For instance, I/O handlers are not processes. They do not have context (state of execution in registers, stack data, heap, etc) like normal processes do. They are simply a piece of instructions that is written and executed to handle certain events.
You can think of a the kernel instead as made up of just instructions (a bunch of handlers) and data. Parts of the kernel deal with memory management, parts of it with scheduling portions of itself (like drivers, etc), and parts of it with scheduling processes.
User-mode processes can execute Kernel instructions to complete a particular service or task before resuming its own instructions:
- User processes running the kernel code will have its mode changed to Kernel Mode
- Once it returns from the handler, its mode is changed back to User Mode
Hence, the statement that the kernel is a program that is running at all times is technically true because the kernel IS part of each process. Any process may switch itself into Kernel Mode and perform system call routines (software interrupt), or forcibly switched to Kernel Mode in the event of hardware interrupt.
The Kernel piggybacks on any process in the system to run.
If there are no system calls made, and no hardware interrupts, the kernel does nothing at this instant since it is not entered, and there’s nothing for it to do.
Process Manager
The process manager is part of the kernel code. It is part of the the scheduler subroutine, may be called either when there’s timed interrupt by the timed interrupt handler or trap handler when there’s system call made. It manages and keeps track of the system-wide process table, a data structure containing all sorts of information about current processes in the system. You will learn more about this in Week 3.
The process manager is responsible for the following tasks:
- Creation and termination of both user and system processes
- Pausing and resuming processes in the event of interrupts or system calls
- Synchronising processes and provides communications between virtual spaces (Week 4 materials)
- Provide mechanisms to handle deadlocks (Week 5 materials)
Providing Security and Protection
The operating system kernel provides protection for the computer system by providing a mechanism for controlling access of processes or users to resources defined by the OS.
This is done by identifying the user associated with that process:
- Using user identities (user IDs, security IDs): name and associated number among all numbers
- User ID then associated with all files, processes of that user to determine access control
- For shared computer: group identifier (group ID) allows set of users to be defined and controls managed, then also associated with each process, file
You will learn more about this in Week 6 and Lab 3. During Lab 3, you will learn about Privilege Escalation: an event when a user can change its ID to another effective ID with more rights. You may read on how this can happen in Linux systems here.
Finally, the Kernel also provides defensive security measures for the computer system: protecting itself against internal and external attacks via firewalls, encryption, etc. There’s a huge range of security issues when a computer is connected in a network, some of them include denial-of-service, worms, viruses, identity theft, theft of service. You will learn more about this in Week 10.
System Structure
Multiprocessor System
Unlike single-processor systems that we have learned before, multiprocessor systems have two or more processors in close communication, sharing the computer bus and sometimes the clock, memory, and peripheral devices.
Multiprocessor systems have three main advantages:
- Increased throughput: we can execute many processes in parallel
- Economy of scale: multiprocessor system is cheaper than multiple single processor system
- Increased reliability: if one core fails, we still have the other cores to do the work
Symmetric Architecture
There are different architectures for multiprocessor system, such as a symmetric architecture where we have multiple CPU chips in a computer system:
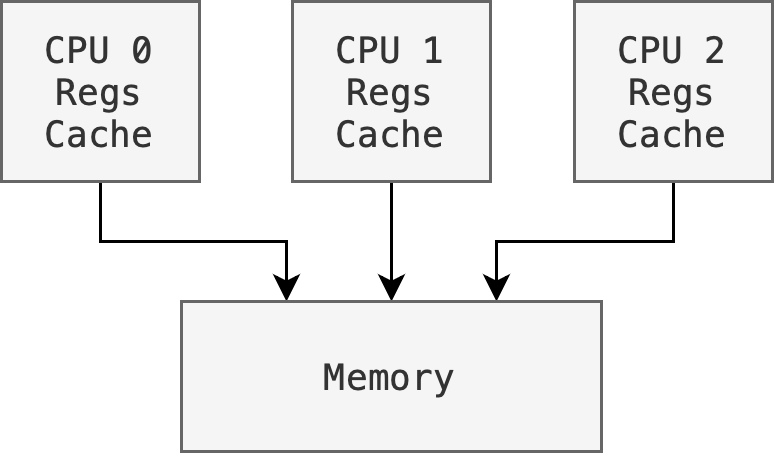
Notice that each processor has its own set of registers, as well as a private or local cache; however, all processors share the same physical memory. This brings about design issues that we need to note in symmetric architectures:
- Need to carefully control I/O o ensure that the data reach the appropriate processor
- Ensure load balancing: avoid the scenario where one processor may be sitting idle while another is overloaded, resulting in inefficiencies
- Ensure cache coherency: if a process supports multicore, makes sure that the data integrity spread among many cache is maintained.
Multi-Core Architecture
Another example of a symmetric architecture is to have multiple cores on the same chip as shown in the figure below:
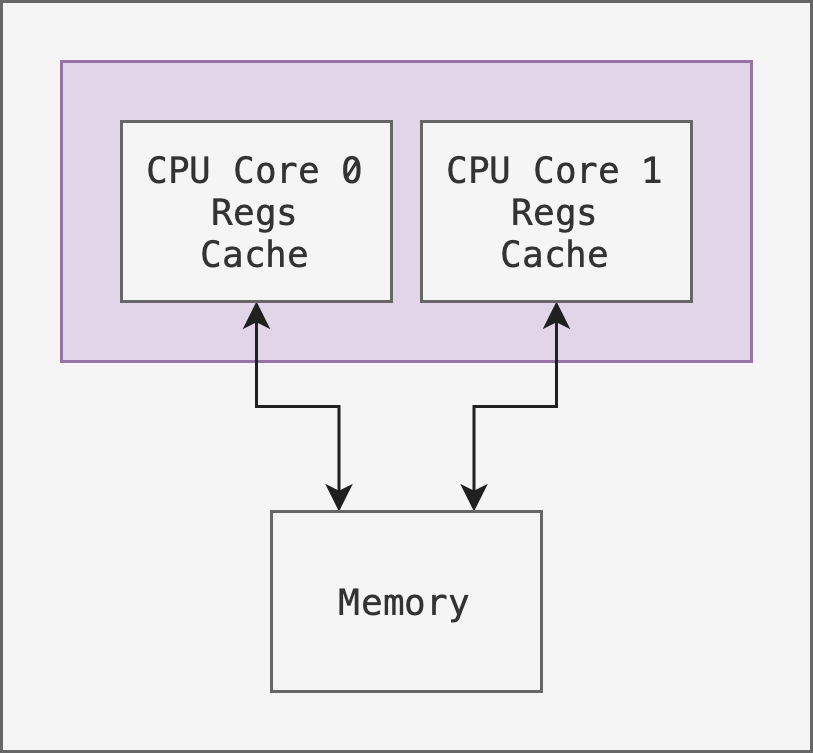
This carries an advantage that on-chip communication is faster than across chip communication. However it requires a more delicate hardware design to place multiple cores on the same chip.
Asymmetric Multiprocessing
In the past, it is not so easy to add a second CPU to a computer system when operating system had commonly been developed for single-CPU systems. Extending it to handle multiple CPUs efficiently and reliably took a long time. To fill this gap, operating systems intended for single CPUs were initially extended to provide minimal support for a second CPU.
This is called asymmetric multiprocessing, in which each processor is assigned a specific task with the presence of a super processor that controls the system. This scheme defines a master–slave relationship. The master processor schedules and allocates work to the slave processors. The other processors either look to the master for instruction or have predefined tasks.
Clustered System
Clustered systems (e.g: AWS) are multiple systems that are working together. They are usually:
- Share storage via a storage-area-network
- Provides high availability service which survives failures
- Useful for high performance computing, require special applications that are written to utilize parallelization
There are two types of clustering:
- Asymmetric: has one machine in hot-standby mode. There’s a master machine that runs the system, while the others are configured as slaves that receive tasks from the master. The master system does the basic input and output requests.
- Symmetric: multiple machines (nodes) running applications, they are monitoring one another, requires complex algorithms to maintain data integrity.
Summary
We have learned that the Operating System is a software that acts as an intermediary between a user of a computer and the computer hardware. It is comprised of the Kernel, system programs, and user programs. Each OS is shipped with different flavours of these programs, depending on its design.
In general, an operating system is made with the following goals in mind:
- Execute user programs and make solving user problems easier
- Make the computer system convenient to use
- Use the computer hardware in an efficient manner
It is a huge piece of software, and usually are divided into separate subsystems based on their roles:
- Process Management
- Resource Allocator and Coordinator
- Memory and Storage Management
- I/O Management,
… and many others. There’s too many to go into detail since modern Operating Systems kept getting expanded to improve user experience.
The Kernel is the heart of the OS, the central part of it that holds important pieces of instructions that support the roles stated above in the bare minimum. In the next chapter, we will learn how to access crucial OS Kernel services.
This chapter elaborates on the critical functionalities and management roles of the OS kernel. It provides a thorough understanding of how the kernel orchestrates interaction between software and hardware, manages processes and memory, and ensures system security and efficiency.
Key learning points include:
- Interrupt-Driven I/O Operations: Differentiating between hardware and software interrupts, and explaining vectored versus polled interrupt systems.
- Process and Memory Management: How the kernel manages virtual memory, handles multiple processes, and optimizes cache performance.
- Kernel Modes: Differences between reentrant and preemptive kernels, and their implications for multitasking.
Appendix
Timed Interrupts
We must ensure that the kernel, as a resource allocator maintains control over the CPU. We cannot allow a user program to get stuck in an infinite loop and never return control to the OS. We also cannot trust a user program to voluntarily return control to the OS. To ensure that no user program can occupy a CPU for indefinitely, a computer system comes with a (hardware)-based timer. A timer can be set to invoke the hardware interrupt line so that a running user program may transfer control to the kernel after a specified period. Typically, a scheduler will be invoked each time the timer interrupt occurs.
In the hardware, a timer is generally implemented by a fixed-rate clock and a counter. The kernel may set the starting value of the counter, just like how you implement a custom clock in your 1D 50.002 project, for instance, here’s one simple steps describing how timed interrupts work:
- Every time the sytem clock ticks, a counter with some starting value
Nis decremented. - When the counter reaches a certain value, the timer can be hardware triggered to set the interrupt request line
For instance, we can have a 10-bit counter with a 1-ms clock can be set to trigger interrupts at intervals anywhere from 1 ms to 1,024 ms, with precision of 1 ms. Let’s say we decide that every 512 ms, timed interrupt will occur, then we can say that the size of a quantum (time slice) for each process is 512ms. We can give multiple quantums (quanta) for a user process.
When timed interrupt happens, this transfers control over to the interrupt handler, and the following routine is triggered:
- Save the current program’s state
- Then call the scheduler to perform context switching
- The scheduler may then reset the counter before restoring the next process to be executed in the CPU. This ensures that a proper timed interrupt can occur in the future.
- Note that a scheduler may allocate arbitrary amount of time for a process to run, e.g: a process may be allocated a longer time slot than the other. We will learn more about process management in Week 3.
IVT in various Architectures
Below is an example of ARMv8-M interrupt vector table, which describe which RAM addresses should contain the handler entry (also called interrupt service routine, ISR) for all sorts of interrupts (both software and hardware). The table is typically implemented in the lower physical addresses in many architecture.

Each exception has an ID (associated number), a vector address that is the exception entry point in memory, and a priority level which determines the order in which multiple pending exceptions are handled. In ARMv8-M, the lower the priority number, the higher the priority level.
Based on the instruction set spec of ARMv8, integer division by zero returns zero and not trapped.
In x86 architecture, exception handlers are normally found via so called Interrupt Descriptor Table or IDT for short. The IDT is typically located in memory at a specific base address, stored in Interrupt Descriptor Table Register (IDTR, a special register). The value of this base address depends on the operating system. In some older hardware like Intel 8086, the interrupt vector table is placed at a fixed location: always located in the first 1024 bytes of memory at addresses 0x000000–0x0003FF and the more complex config of IDT + IDTR does not exist.
The IDT contains up to 256 entries and each of those entries is 16 bytes in size in 64 bit mode. For instance, a division by zero exception exists in x86 (unlike in ARMv8), and can be triggered by the CPU automatically (e.g: hardware is built to check that a divisor is not 0). By convention, this directs the PC to exec RAM address containing that division-by-zero handler entry directly (e.g: address 0, as it is customary to have division by zero as the first handler entry of IVT).
Reentrant Kernel Behavior
Here we explore a kernel-related analogy using simplified examples in C that demonstrate reentrant vs. non-reentrant behavior.
Non-Reentrant Kernel Function
#include <stdio.h>
#include <pthread.h>
#define BUFFER_SIZE 100
char global_buffer[BUFFER_SIZE];
int buffer_index = 0;
void non_reentrant_syscall(char data) {
global_buffer[buffer_index++] = data;
// Simulate processing
printf("Processing: %s\n", global_buffer);
}
void* thread_function(void* arg) {
char data = *(char*)arg;
non_reentrant_syscall(data);
return NULL;
}
int main() {
pthread_t thread1, thread2;
char data1 = 'A', data2 = 'B';
pthread_create(&thread1, NULL, thread_function, &data1);
pthread_create(&thread2, NULL, thread_function, &data2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
In this example, non_reentrant_syscall modifies a global buffer. If two threads call this function concurrently, it may lead to race conditions and inconsistent states in the global_buffer.
Reentrant Kernel Function
#include <stdio.h>
#include <pthread.h>
#include <string.h>
#define BUFFER_SIZE 100
void reentrant_syscall(char* buffer, char data) {
int len = strlen(buffer);
buffer[len] = data;
buffer[len + 1] = '\0';
// Simulate processing
printf("Processing: %s\n", buffer);
}
void* thread_function(void* arg) {
char data = *(char*)arg;
char local_buffer[BUFFER_SIZE] = "";
reentrant_syscall(local_buffer, data);
return NULL;
}
int main() {
pthread_t thread1, thread2;
char data1 = 'A', data2 = 'B';
pthread_create(&thread1, NULL, thread_function, &data1);
pthread_create(&thread2, NULL, thread_function, &data2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
In this example, reentrant_syscall operates on a local buffer passed as an argument. Each thread has its own buffer, avoiding shared state and making the function safe for concurrent execution.
Analogy to Kernel
-
Non-Reentrant Kernel Function: Uses global state (e.g.,
global_buffer). If two system calls modify the global state concurrently, it can lead to data corruption or inconsistent system states. This is like a kernel that isn’t designed for reentrancy and fails under concurrent execution. -
Reentrant Kernel Function: Uses local state or parameters (e.g.,
local_buffer). Each system call operates independently on its own data, making it safe for concurrent execution. This is like a kernel deliberately designed for reentrancy, ensuring correct and consistent behavior under concurrent execution.
In an operating system, reentrant kernel functions are crucial for handling multiple processes or threads safely, ensuring that shared resources are not corrupted and system stability is maintained.
TTY
A TTY device, originally short for “teletypewriter,” refers to a character-oriented device interface used to facilitate text-based input and output between user-space programs and the operating system. In contemporary systems, TTY devices encompass physical terminals, virtual consoles, and pseudoterminals. Physical terminals include hardware serial interfaces such as /dev/ttyS0, while virtual terminals refer to interfaces like /dev/tty1 through /dev/tty6, commonly accessed via keyboard shortcuts on local machines. Pseudoterminals, such as those represented by /dev/pts/*, are typically used by terminal emulators and remote sessions (e.g., SSH or tmux).
The TTY subsystem in the kernel is responsible for processing character input and output through these devices. It manages buffering, line editing, signal generation (such as Ctrl+C translating to SIGINT), and echo functionality via a component called the line discipline. When a user program performs a blocking read() call on a TTY device, the kernel places the process in a wait queue until sufficient input (e.g., a newline-terminated line) becomes available. Input events, typically triggered by keyboard interrupts, are processed by the input subsystem and forwarded to the TTY layer, which then wakes up any blocked processes when their input criteria are satisfied.
Not all processes interact with a TTY. Graphical user interface (GUI) applications, background daemons, and many automated system services operate independently of TTY devices. These processes do not rely on text-based standard input or output, and therefore do not require a controlling terminal. In fact, processes without an associated TTY cannot receive terminal-generated signals and typically redirect their input and output to other interfaces such as pipes, sockets, or log files. This separation allows modern operating systems to support both interactive and non-interactive process models efficiently.
In summary, TTY devices provide a standardized interface for interactive, text-based communication between the user and the system, primarily used by shell sessions and terminal-based applications. However, many user-space processes, particularly those in graphical or headless environments, operate without any reliance on TTY infrastructure.
-
Since only a predefined number of interrupts is possible, a table of pointers to interrupt routines can be used instead to provide the necessary speed. The interrupt routine is called indirectly through the table, with no intermediate routine needed. Generally, the table of pointers is stored in low memory (the first hundred or so locations), and its values are determined at boot time. These locations hold the addresses of the interrupt service routines for the various devices. This array, or interrupt vector, of addresses is then indexed by a unique device number, given with the interrupt request, to provide the address of the interrupt service routine for the interrupting device. Operating systems as different as Windows and UNIX dispatch interrupts in this manner. ↩
-
Depending on the implementation of the handler, a full context switch (completely saving ALL register states, etc) may not be necessary. Some OS may implement interrupt handlers in low-level languages such that it knows exactly which registers to use and only need to save the states of these registers first before using them. ↩
-
A reentrant procedure can be interrupted in the middle of its execution and then safely be called again (“re-entered”) before its previous invocations complete execution. There are several problems that must be carefully considered before declaring a procedure to be reentrant. All user procedures are reentrant, but it comes at a costly procedure to prevent lost data during interrupted execution. ↩
-
Interrupt-driven I/O is fine for moving small amounts of data but can produce high overhead when used for bulk data movement such as disk I/O. To solve this problem, direct memory access (DMA) is used. After setting up buffers, pointers, and counters for the I/O device, the device controller transfers an entire block of data directly to or from its own buffer storage to memory, with no intervention by the CPU. ↩
-
The CPU cache is a hardware cache: performing optimization that’s unrelated to the functionality of the software. It handles each and every access between CPU cache and main memory as well. They need to work fast, too fast to be under software control, and are entirely built into the hardware. ↩