 50.005 CSE
50.005 CSE
- Processes
- Process Management
- Operations on Processes
- Process Creation
- Summary
- Appendix
50.005 Computer System Engineering
Information Systems Technology and Design
Singapore University of Technology and Design
Natalie Agus (Summer 2025)
Processes
Detailed Learning Objectives
- Discuss the Differences Between Process and Program
- Recognize that a process is a dynamic execution instance of a static program.
- Demonstrate that a program is a passive entity containing the code, whereas a process is an active entity with executing code and associated resources.
- Point out components of a process image (address space)
- Explore Process Context
- Identify what constitutes a process’ context including the program counter, processor’s registers, stack, image, and more.
- Explain how multiple instances of a program can run as separate processes.
- Locate Concurrency and Protection in Processes
- Recall how processes allow for concurrency and provide protection, enabling processes to operate as if they are the only ones running on the system.
- Compare and contrast between concurrency and parallelism
- Summarize Process Lifecycle
- Examine different process states (New, Running, Waiting, Ready, Terminated) and their transitions.
- Explain UNIX data structures used to manage process lifecycle: Process Table and a Process Control Block (PCB) which store process attributes.
- Show how to create a new process, e.g: using
fork()in C and its implications- Show how to replace a process’ image with the
exec()system call family and comprehend its implications- Explain Process Management and Scheduling
- Demonstrate how processes are managed and scheduled by the operating system, including the role of the scheduler.
- Describe context switching and its impact on system performance.
These objectives are structured to provide a comprehensive overview of the concepts related to processes versus programs, their management, and the system’s handling of multiple processes.
Process vs Program
A process is formally defined as a program in execution. Process is an active, dynamic entity – i.e: it changes state overtime during execution, while a program is a passive, static entity. A program is the code and static data as they exist on the disk. A process is so much more than just a program code (text or instruction section)
Before we proceed, please remember that a program is not a process.
Process Context
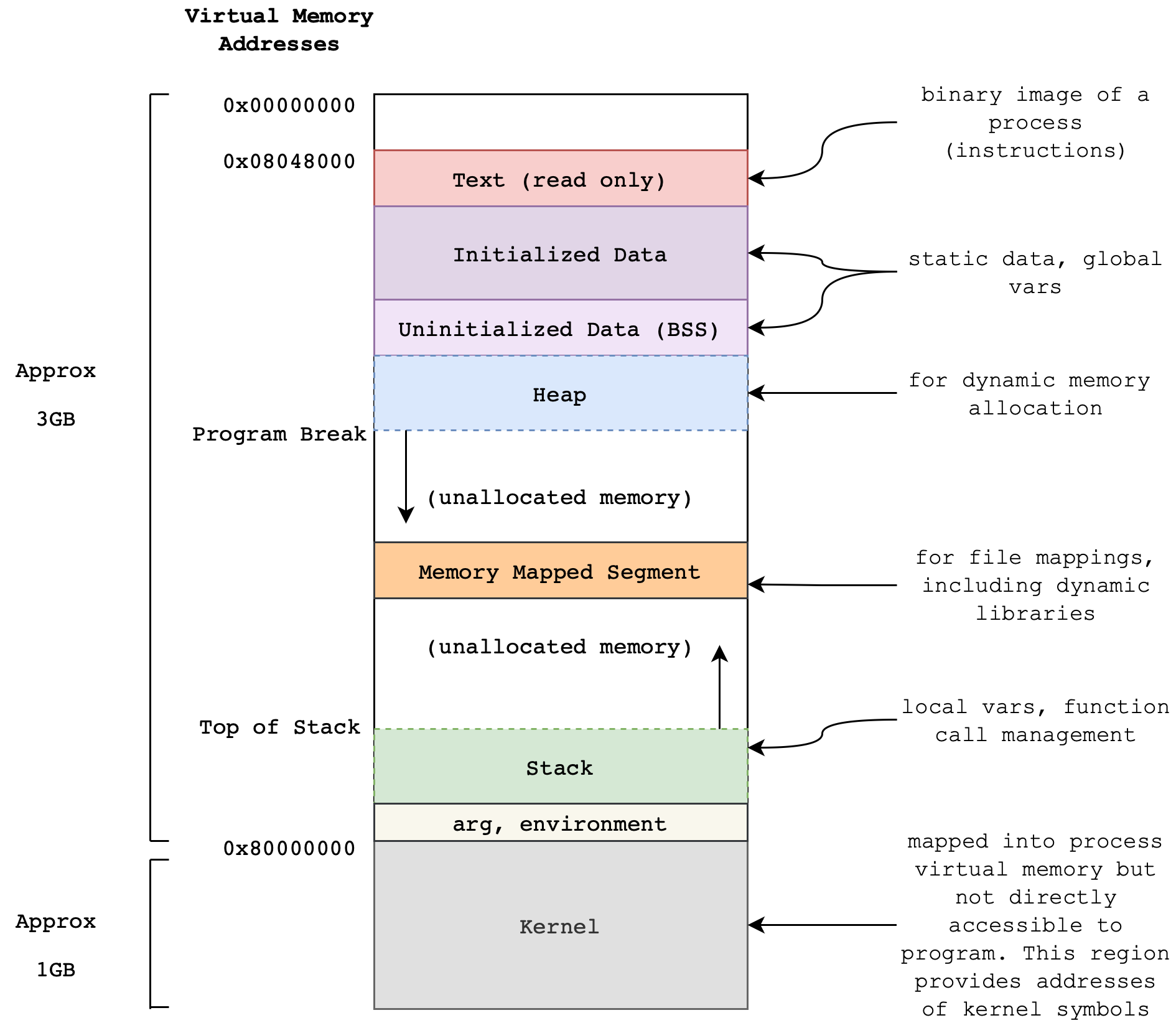
A single process includes all of the following information, which we call the process’ context:
- The text section (code or instructions)
- Value of the Program Counter (PC)
- Contents of the processor’s registers
- Dedicated1 address space (block of location) in memory
- Stack (temporary data such as function parameters, return address, and local variables),
- Data (allocated memory during compile time such as global and static variables that have predefined values)
- Heap (dynamically allocated memory – typically by calling
mallocin C – during process runtime, grows upwards)2
This set of information is also known as a process state, or a process context.
The same program can be run n times to create n processes simultaneously.
- For example, separate tabs on some web browsers are created as separate processes.
- The program for all tabs are the same: which is the part of the web browser code itself.
A program becomes a process when an executable (binary) file is loaded into memory (either by double clicking them or executing them from the command line)
Concurrency and Protection
A process couples two abstractions: concurrency and protection.
Protection: Each process runs in a different address space and sees itself as running in a virtual machine – unaware of the presence of other processes in the machine. Multiple processes execution in a single machine is concurrent, managed by the kernel scheduler.
Concurrency: Multiple processes being in progress at the same time, sharing system resources. These processes can run in parallel on multiple processors or cores, or they can be interleaved on a single processor through time slicing.
Piggybacking
From this point onwards, we are going to refer simply to the scheduler as the kernel. Remember this is just a running code (service routine) with kernel privileges whose task is to manage processes. Scheduler in itself, is part of the kernel, and is not a process.
Recall how the system calls piggyback the currently running user-process which mode has been changed to kernel mode. Likewise, the scheduler is just a set of instructions, part of the kernel realm whose job is to manage other processes. It is inevitable for the scheduler to be executed as well upon invoking certain system calls such as read or get stdin input which requires some waiting time.
Process Management
When you master this chapter, this won’t look amusing to you anymore:

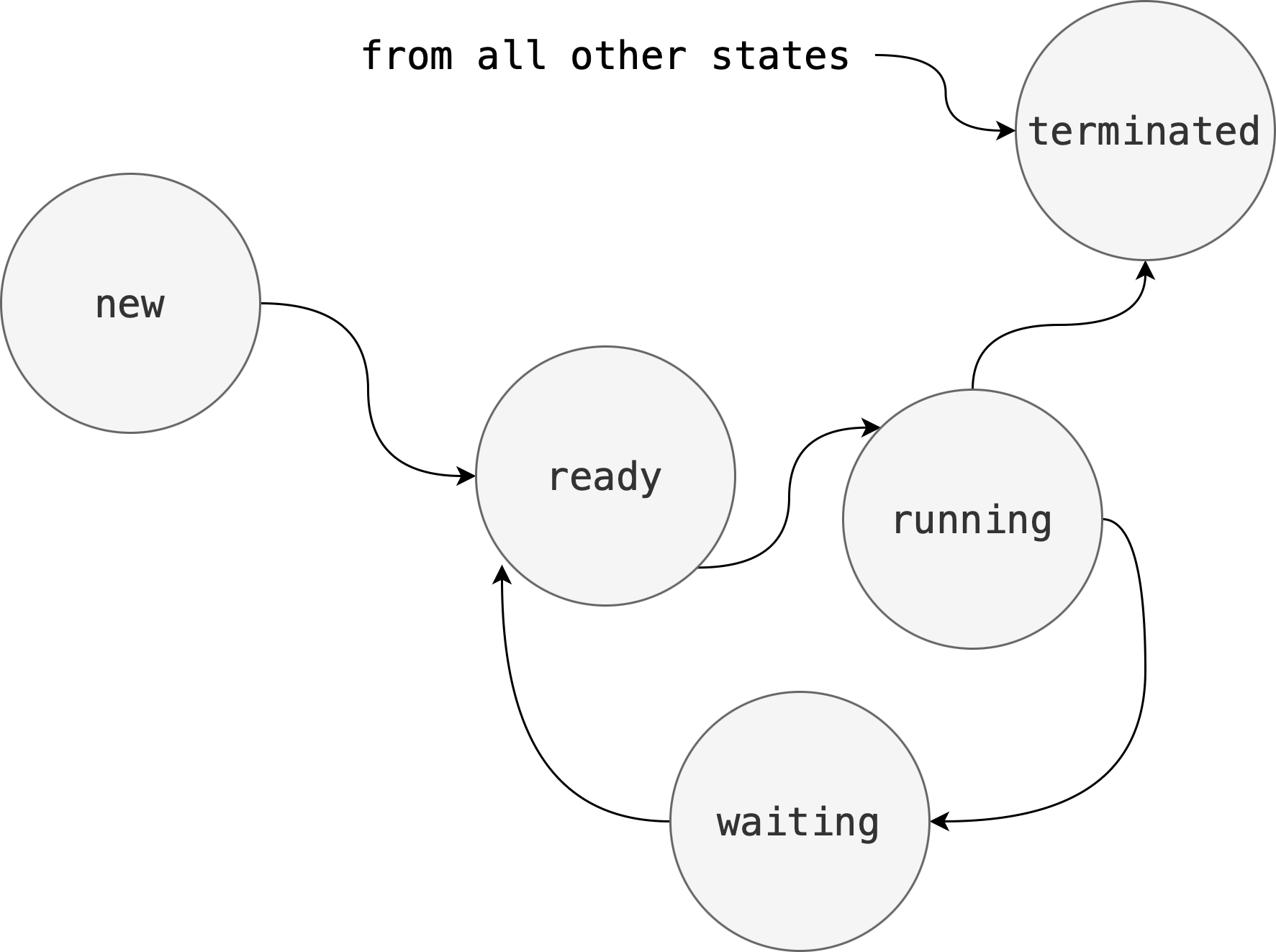
Process Scheduling States
As a process executes, it changes its scheduling state which reflects the current activity of the process.
In general these states are:
- New: The process is being created.
- Running: Instructions are being executed.
- Waiting: The process is waiting for some event to occur (such as an I/O completion or reception of a signal).
- Ready: The process is waiting to be assigned to a processor
- Terminated: The process has finished execution.
The figure below shows the scheduling state transition diagram of a typical process:
Process Table and Process Control Block
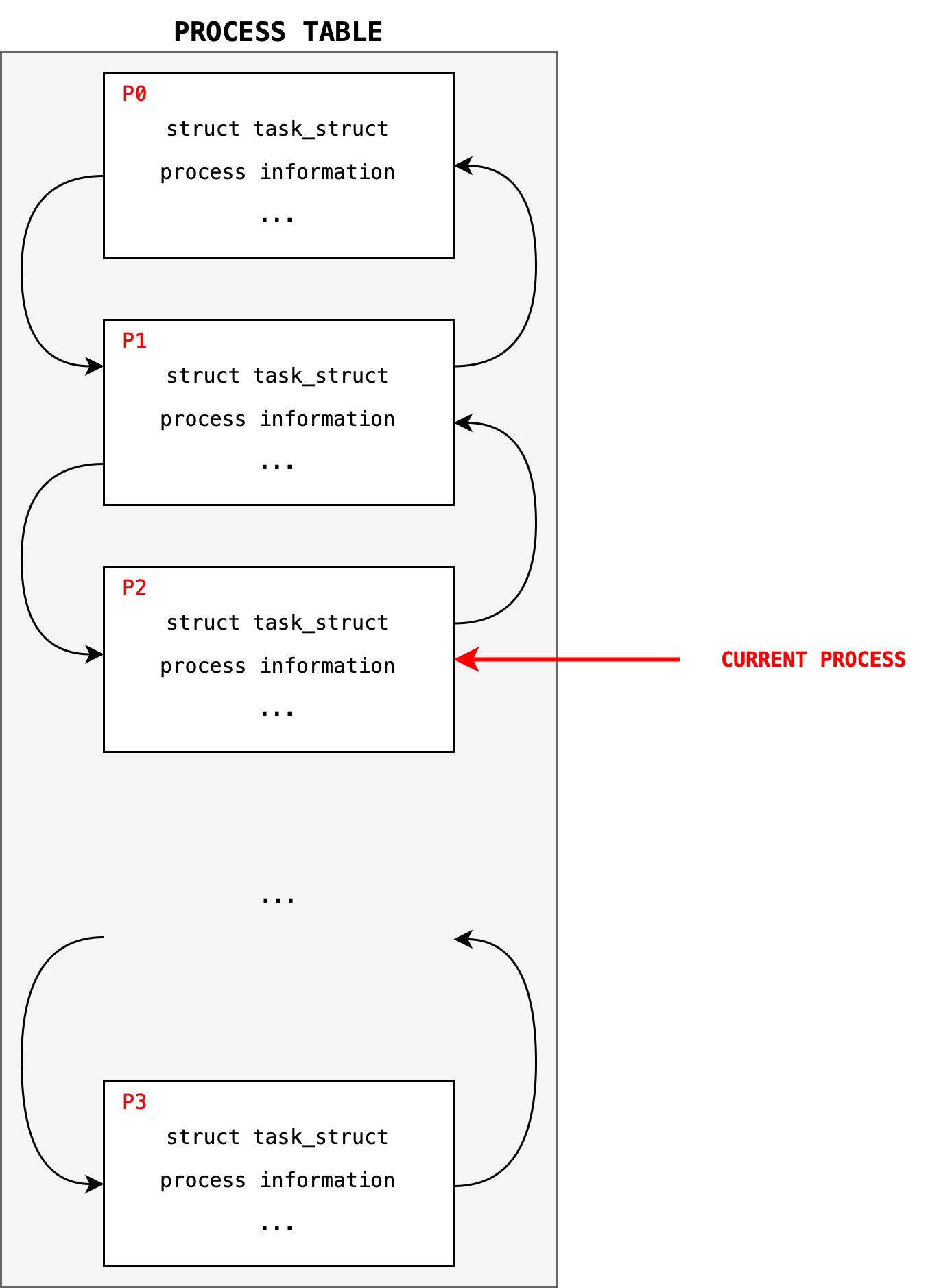
The system-wide process table is data structure maintained by the Kernel to facilitate context switching and scheduling. Each process metadata is stored by the Kernel in a particular data structure called the process control block (PCB). A process table is made up of an array of PCBs, containing information about of current processes3 in the system.
The PCB contains many pieces of information associated with a specific process. These information are updated each time when a process is interrupted:
- Process state: any of the state of the process – new, ready, running, waiting, terminated
- Program counter: the address of the next instruction for this process
- CPU registers: the contents of the registers in the CPU when an interrupt occurs, including stack pointer, exception pointer, stack base, linkage pointer, etc. These contents are saved each time to allow the process to be continued correctly afterward.
- Scheduling information: access priority, pointers to scheduling queues, and any other scheduling parameters
- Memory-management information: page tables, MMU-related information, memory limits
- Accounting information: amount of CPU and real time used, time limits, account numbers, process id (pid)
- I/O status information: the list of I/O devices allocated to the process, a list of open files
PCB is also called a task control block in some textbooks.
Linux task_struct
In Linux system, the PCB is created in C using a data structure called task_struct. The diagram below4 illustrates some of the contents in the structure:
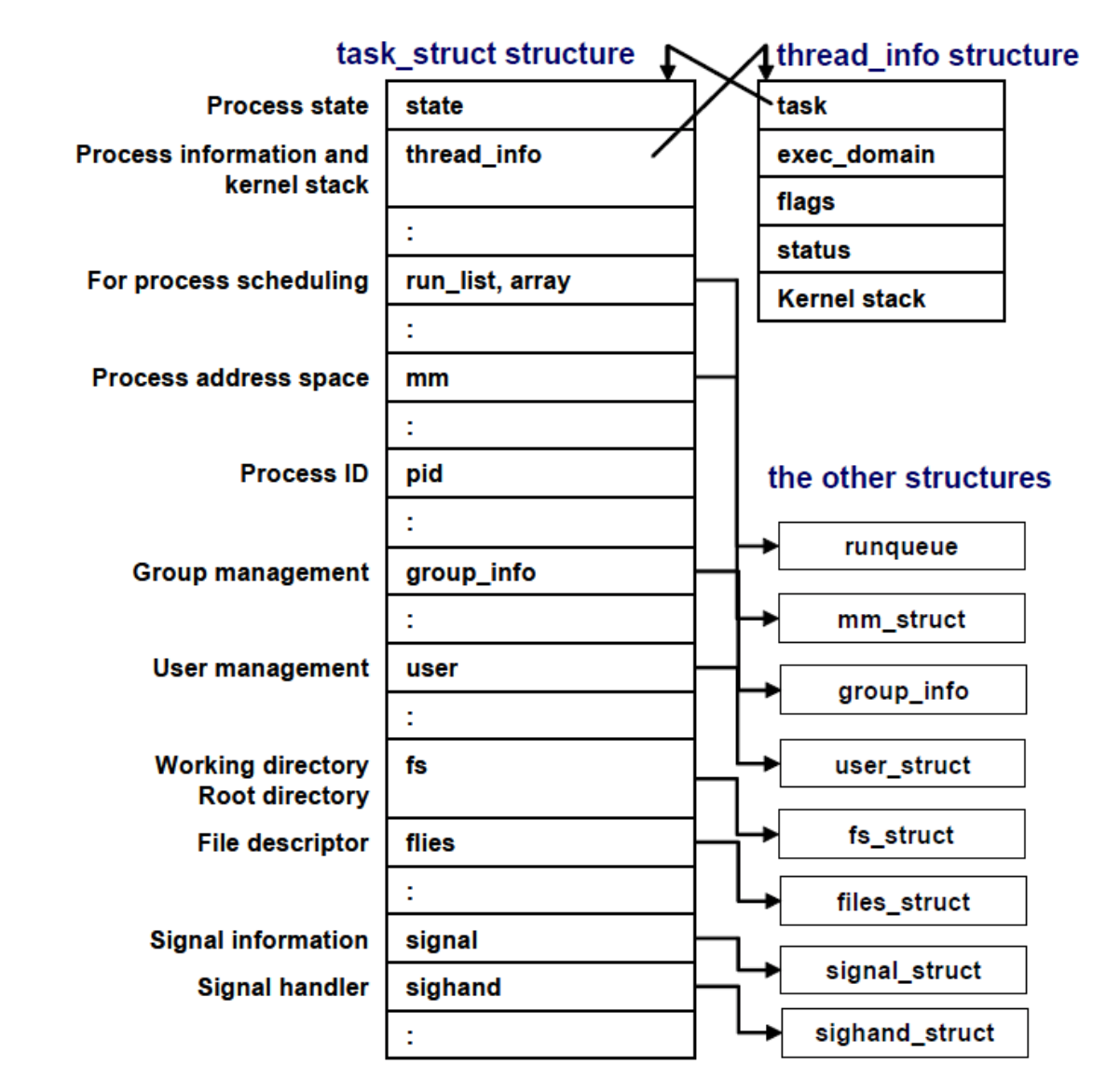
Do not memorize the above, it’s just for illustration purposes only. The task_struct is a relatively large data structure, at around 1.7 kilobytes on a 32-bit machine.
Within the Linux kernel, all active processes are represented using a doubly linked list of task_struct. The kernel maintains a current_pointer to the process that’s currently running in the CPU.
Context Switching
When a CPU switches execution between one process to another, the Kernel has to store all of the process states onto its corresponding PCB, and load the new process’ information from its PCB before resuming them as shown below, (image screenshot from SGG book):
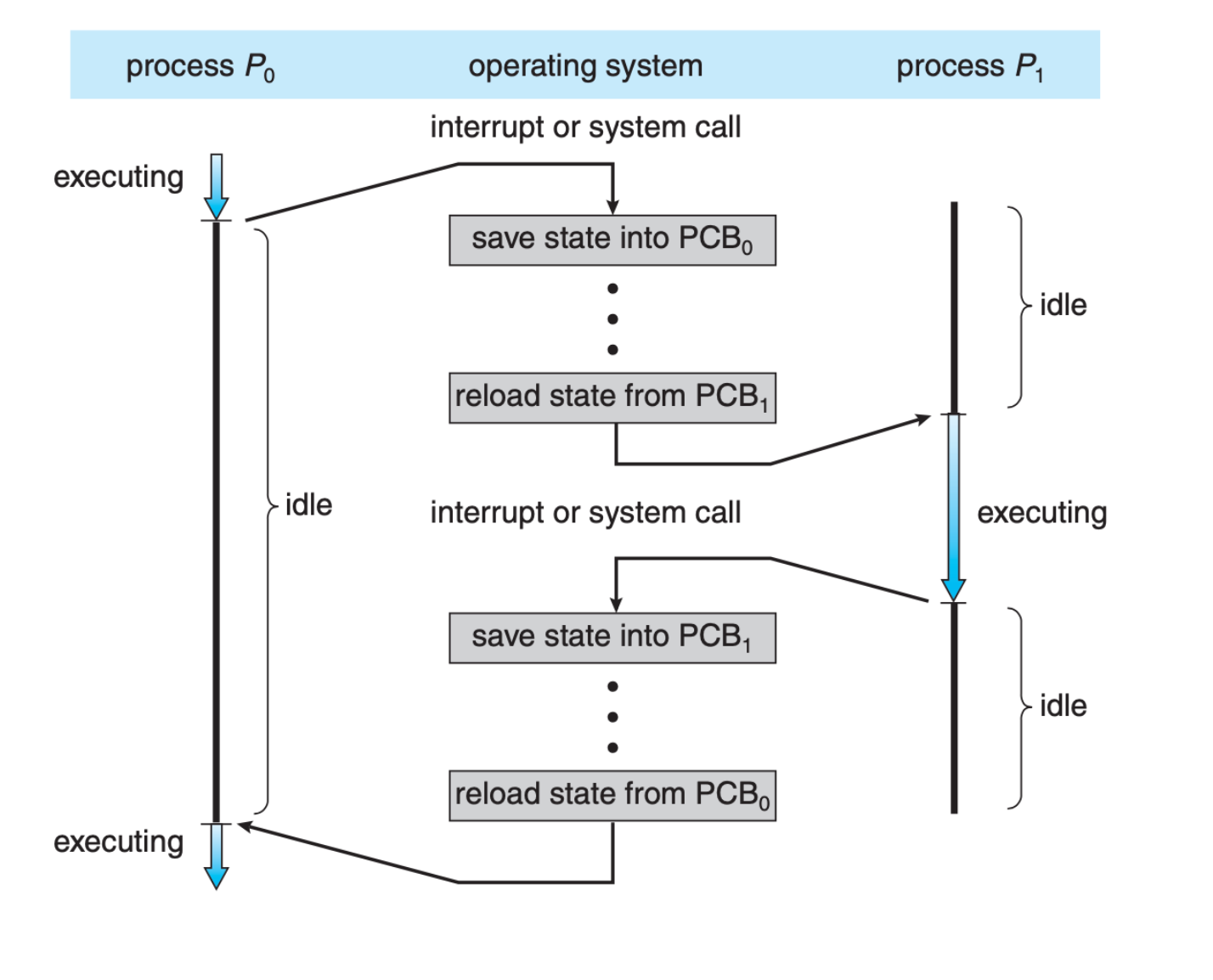
Rapid Context Switching and Timesharing
Context switch definition: the mechanism of saving the states of the current process and restoring (loading) the state of a different process when switching the CPU to execute another process.
Timesharing Support
From users’ point of view, a good computer system should be interactive. Interactivity requires timesharing, and this is done by performing rapid context switching between execution of multiple programs in the computer system.
When an interrupt occurs, the kernel needs to save the current context of the process running on the CPU so that it can restore that context when its processing is done, essentially suspending the process and then resuming it at the later time. The suspended process context is stored in the PCB of that process.
Benefits of Context Switching
Rapid Context switching is beneficial because it gives the illusion of concurrency in uniprocessor system.
- Improve system responsiveness and intractability, ultimately allowing timesharing (users can interact with each program when it is running).
- To support multiprogramming, we need to optimise CPU usage. We cannot just let one single program to run all the time, especially when that program blocks execution when waiting for I/O (idles, have nothing important to do).
Drawback of Context Switching
Context-switch time is pure overhead, because the system does no useful work while switching. To minimise downtime due to overhead, context-switch times are highly dependent on hardware support – some hardware supports rapid context switching by having a dedicated unit for that (effectively bypassing the CPU).
Mode Switch Versus Context Switch
Mode switch and Context switch – although similar in name; they are two separate concepts.
Mode switch
- The privilege of a process changes
- Simply escalates privilege from user mode to kernel mode to access kernel services.
- Done by either: hardware interrupts, system calls (traps, software interrupt), exception, or reset
- Mode switch may not always lead to context switch. Depending on implementation, Kernel code decides whether or not it is necessary.
Context switch
- Requires both saving (all) states of the old process and loading (all) states of the new process to resume execution
- Can be caused either by timed interrupt or system call that leads to a
yield(), e.g: when waiting for something.
Ask yourself
Think about scenarios that requires mode switch but not context switch.
Process Scheduling Detail
Motivation
The objective of multiprogramming is to have some process running at all times, to maximize CPU utilization.
The objective of time sharing is to switch the CPU among processes so frequently that users can interact with each program while it is running.
To meet both objectives, the process scheduler selects an available process (possibly from a set of several available processes) for program execution on the CPU.
- For a single-processor system, there will never be more than one actual running process at any instant.
- If there are more processes, the rest will have to wait in a queue until the CPU is free and can be rescheduled.
For Linux scheduler, see the man page here. We can set scheduling policies: SCHED_RR, SCHED_FIFO, etc. We can also set priority value and nice value of a process (the latter used to control the priority value of a process in user space5.
Process Scheduling Queues
There are three queues that are maintained by the process scheduler:
- Job queue – set of all processes in the system (can be in both main memory and swap space of disk)
- Ready queue – set of all processes residing in main memory, ready and waiting to execute (queueing for CPU)
- Device queues – set of processes waiting for an I/O device (one queue for each device)
Each queue contains the pointer to the corresponding PCBs that are waiting for the resource (CPU, or I/O).
Example
The diagram below shows a system with ONE ready queue, and FOUR device queues (image screenshot from SGG book):
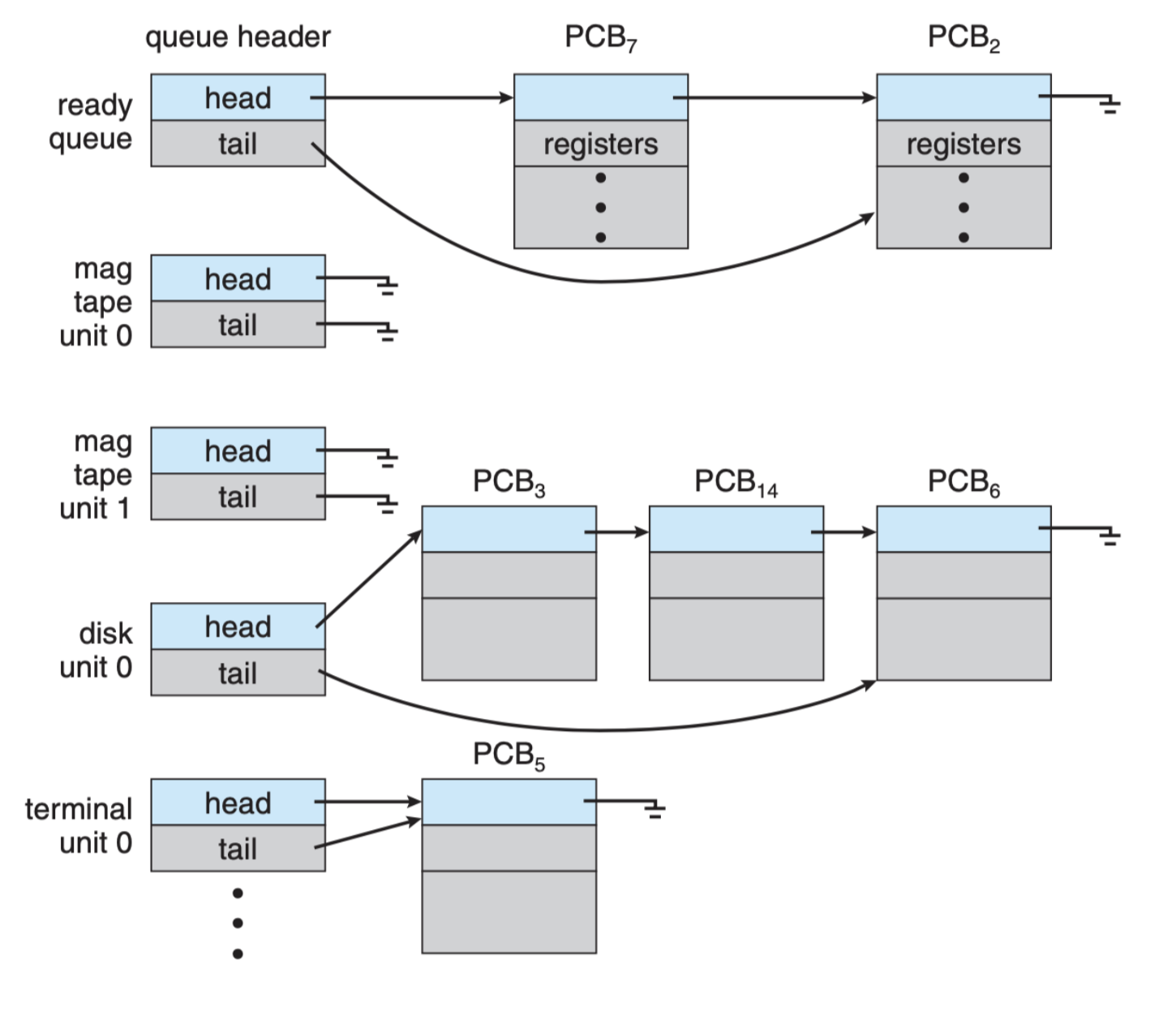
Queueing Diagram
A common representation of process scheduling is using a queueing diagram as shown below:
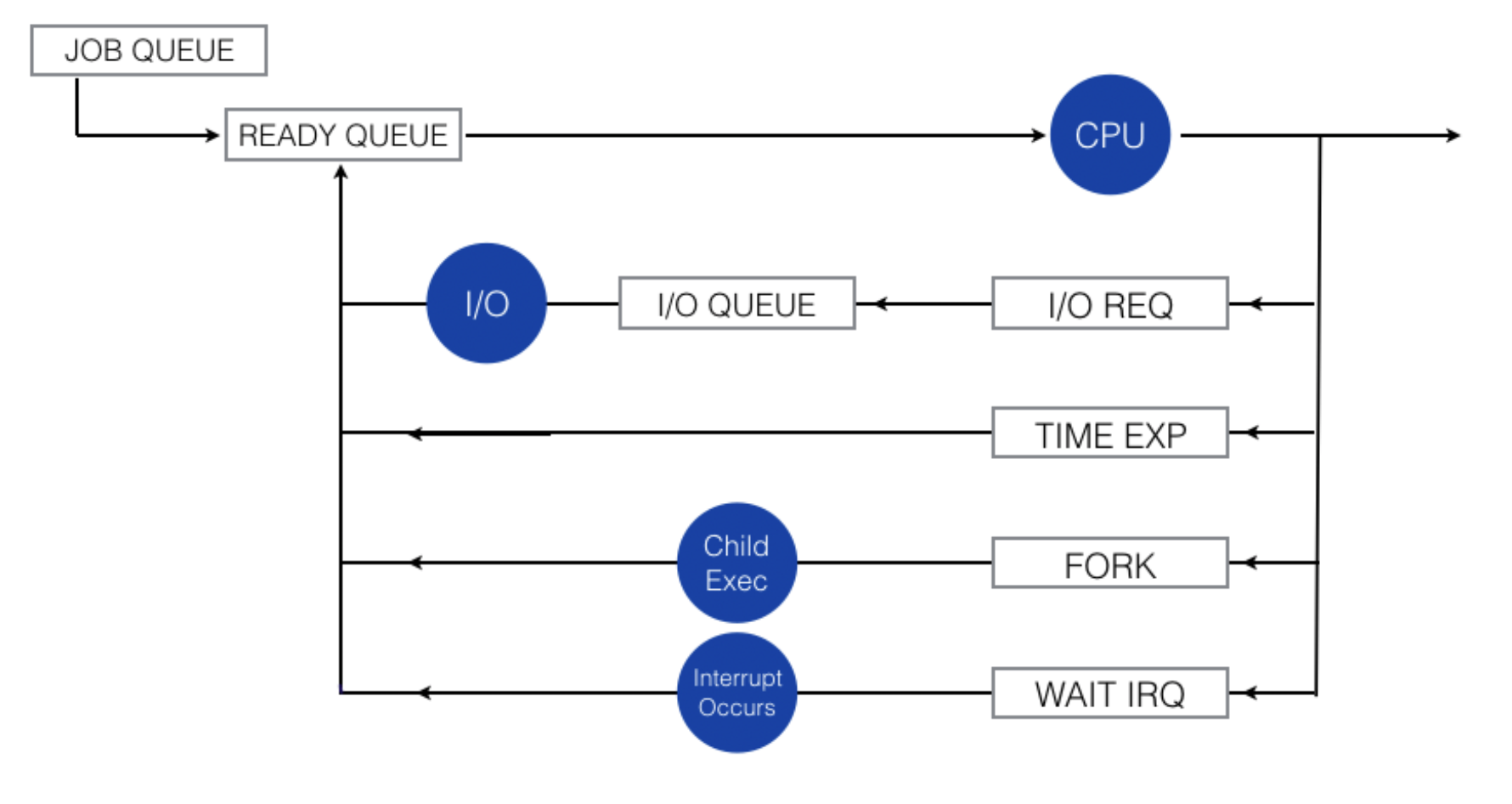
A note on the diagram’s symbols:
- Rectangular boxes represent queues,
- Circles represent resources serving the queue
- All types of queue: job queue, ready queue and a set of device queues (I/O queue, I/O Req, time exp, fork queue, and wait irq)
A new process is initially put in the ready queue. It waits there until it is selected for execution, or dispatched. Once the process is allocated the CPU, a few things might happen afterwards (that causes the process to leave the CPU):
- If the process issue an I/O request, it will be placed onto the I/O queue
- If the process
forks(create new process), it may queue (wait) until the child process finishes (terminated) - The process could be forcily removed from the CPU (e.g: because of an interrupt), and be put back in the ready queue.
Process scheduler is typically divided into two parts: long term and short term. Refer to the appendix section if you’re interested to find out more.
Operations on Processes
We can perform various operations on a process: spawning child processes, terminate the process, set up inter-process communication channels, change the process priority, and many more. All of these operations require a system call (switching to Kernel Mode). In this example, we use the C API to make the system call.
Process Creation
We can create new processes using fork() system call.
- The process creator is called a parent process, the new processes are called the children of that process.
- Each of these new processes may in turn create more child processes, forming a tree of processes.
Process Tree
We can illustrate multiple process creation as a process tree:
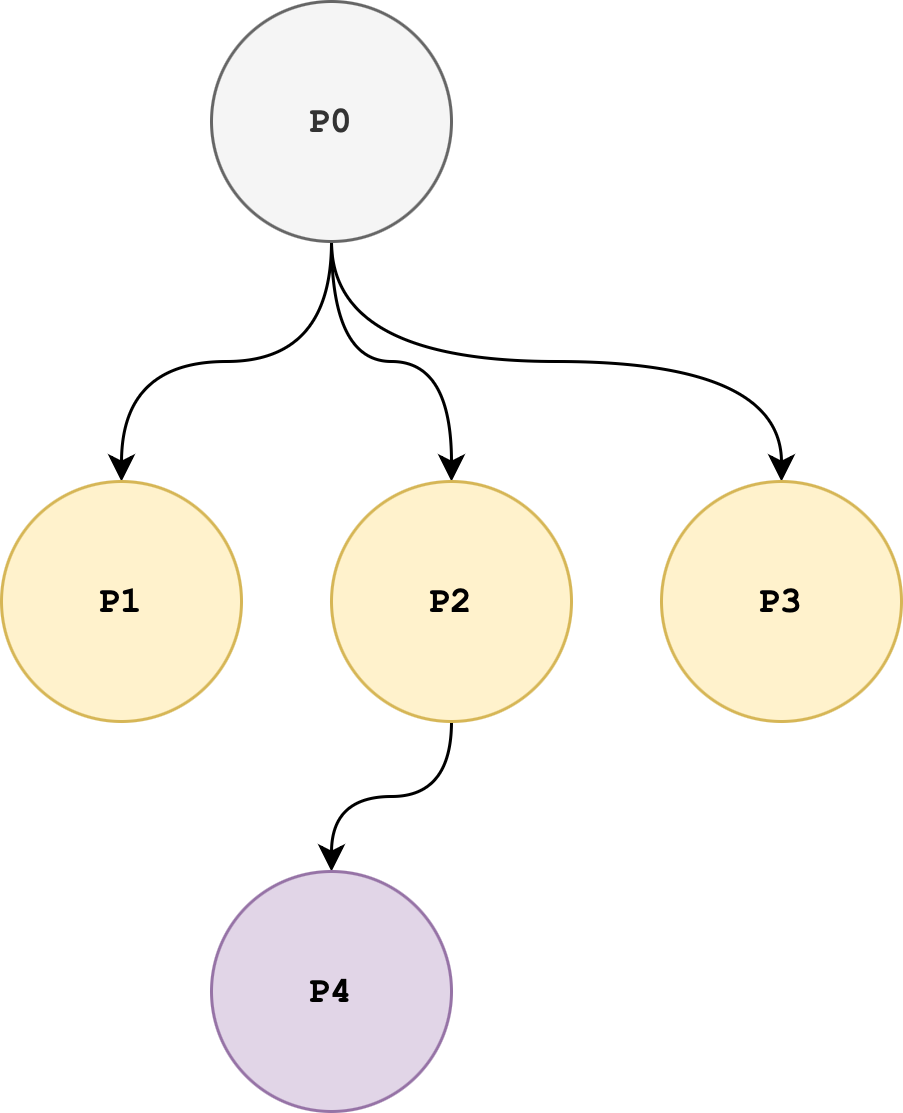
In the example above, there are 5 processes in total. Process 1, 2, and 3 are direct children of Process 0. Process 4 is created by Process 2.
Process id
Each process is identified by an integer called the process id (pid). Pid is unique in the system.
You can type the command ps [options] to observe all running processes in your system, along with the pid of each process. For instance,
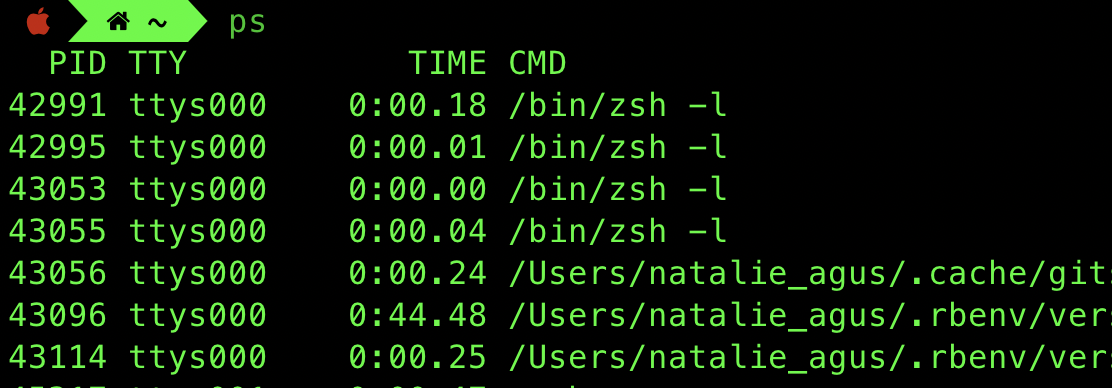
Child Process vs Parent Process
The new process consists of the entire copy of the address space (code, stack, process of execution, etc) of the original parent process at the point of fork().
The child process inherits the parent process’ state at the point of fork().
Parent and child processes operate in different address space (isolation). Since they are different processes, parent and children processes execute concurrently.
Practically, a parent process waits for its children to terminate (using wait() system call) to read the child process’ exit status and only then its PCB entry in the process table can be removed.
Child processes is unable wait for their parents to terminate (there’s no system call for that in UNIX systems). Since children processes are a duplicate of their parents (inherits the whole address space), they can either
- Execute the same instructions as their parents concurrently, or
- Load a new program into its address space
How fork works
It is best to explain how fork() process creation works by example.
#include <sys/wait.h>
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
pid_t pid;
pid = fork();
printf("pid: %d\n", pid);
if (pid < 0)
{
fprintf(stderr, "Fork has failed. Exiting now");
return 1; // exit error
}
else if (pid == 0)
{
execlp("/bin/ls", "ls", NULL);
}
else
{
wait(NULL);
printf("Child has exited.\n");
}
return 0;
}
The simple C program above is executed and when the execution system call fork() returns, two processes are present.
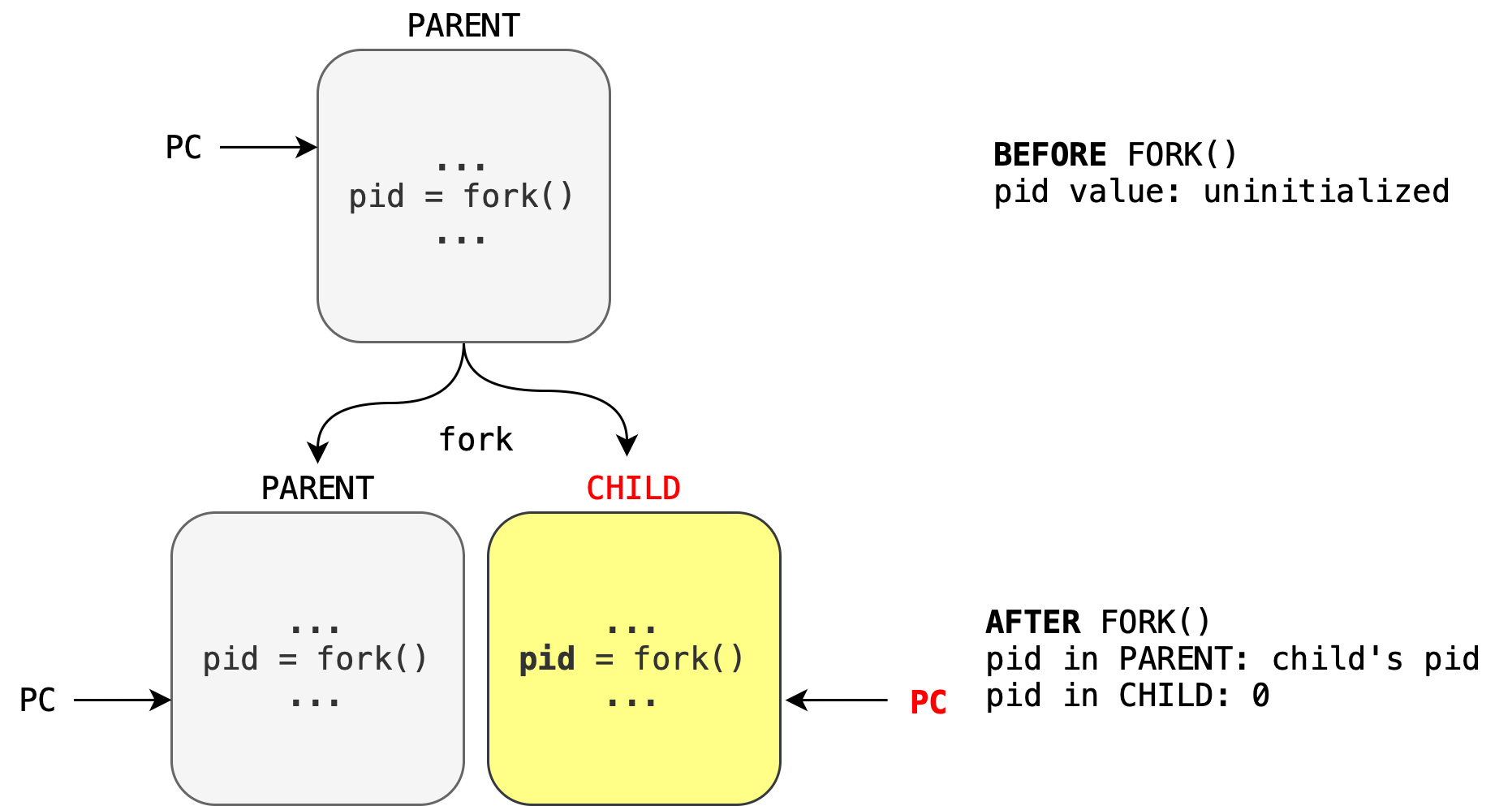
Both have the same copy of the text (code) and resources (any opened files, etc). The parent process is cloned, resulting in the child process. They’re at a different address space, executed concurrently by the system.
fork return value
fork()returns 0 in the child process while in the parent process it returns the pid of the child (>0).
We can write just one instruction for both parent and child process but each will take a different branch of the if clause. In the example code above:
- The child executes the line if-clause:
execlp - The parent process executes the
elseclause where itwaitfor the child process toexit
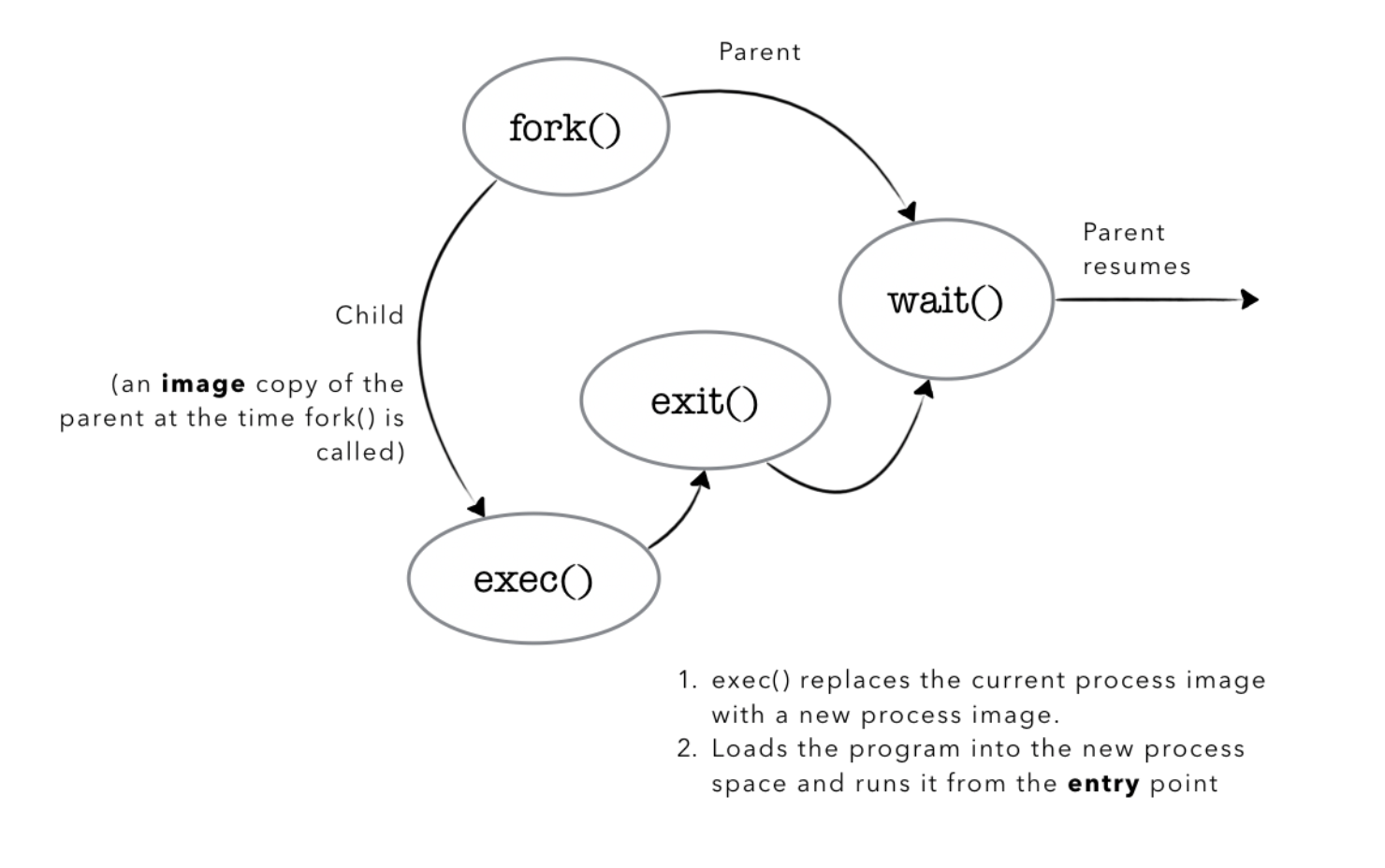
execlp
execlp is a system call that loads a new program called ls onto the child process’ address space, effectively replacing its text (code), data, and stack content.
execlp belongs to the exec system call family. Give this appendix a read to find out more.
wait
Concurrently, the parent process executes wait(NULL), which is a system call that suspends the parents’ execution until this child process that is executing ls has returned.
Another example
Run this program to further understand how fork works:
#include <sys/wait.h>
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char const *argv[])
{
pid_t pid;
pid = fork();
printf("Return value of fork stored in variable pid is: %d\n", pid);
if (pid < 0)
{
fprintf(stderr, "Fork has failed. Exiting now");
return 1; // exit error
}
else if (pid == 0)
{
// child
printf("This is child process with pid %d\n", getpid());
exit(0);
}
else
{
// parent
wait(NULL); // wait for any child to return
printf("This is parent process with pid %d\n", getpid());
}
return 0;
}
Carefully observe the output and do not confuse between variable pid to store the return value of fork vs actual process id returned by getpid.
Expected Output:
- You will see the
PIDreturned byfork()stored in the variablepidprinted by the parent process. It will be a positive number. - The child process will print its message first (or second, depending on the scheduler) showing that it is the child and its
PID. - The parent process will print its message after the child process has exited because it waits for the child to terminate with wait(NULL);. It will show that it is the parent and its
PID.
Program: The fork tree
Compile and run the C program below.
Compute
How many processes are created in total? (excluding the parent process). Can you draw the process tree?
#include <sys/wait.h>
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
int level = 3;
pid_t pid[level];
for (int i = 0; i < level; i++)
{
pid[i] = fork();
if (pid[i] < 0)
{
fprintf(stderr, "Fork has failed. Exiting now");
return 1; // exit error
}
else if (pid[i] == 0)
{
printf("Hello from child %d \n", i);
}
}
return 0;
}
The following shows the process tree resulted from running the above program:
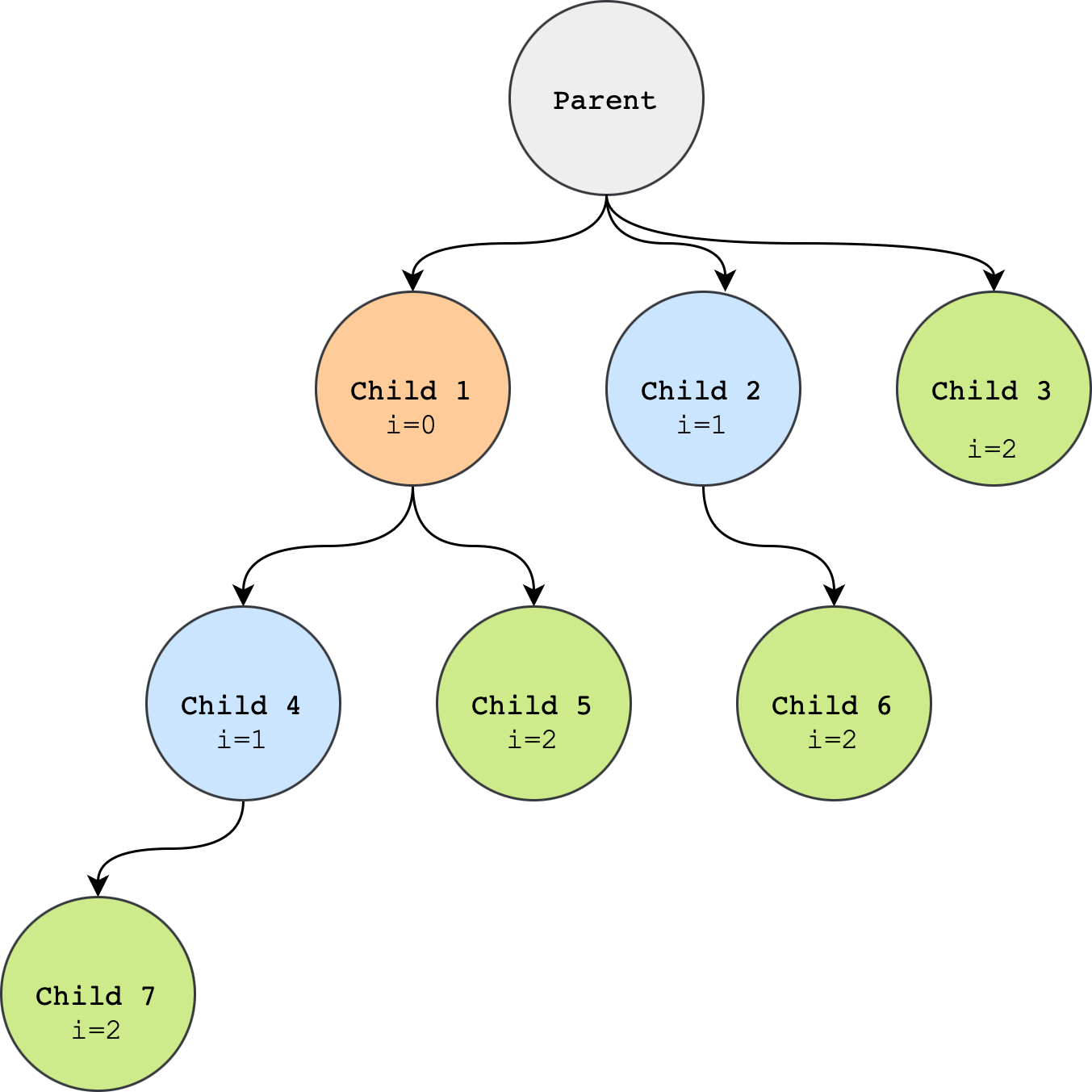
Process Termination
A process needs certain resources (CPU time, memory, files, I/O devices) to run and accomplish its task. These resources are limited.
A process can terminate itself using exit() system call. A process can also terminate other processes using the kill(pid, SIGKILL) system call.
Once a process is terminated, these resources are freed by the kernel for other processes. Parent processes may terminate or abort its children as it knows the pid of its children.
Orphaned processes
If a parent process with live children is terminated, the children processes become orphaned processes:
- Some operating system is designed to either abort all of its orphaned children (cascading termination) or
- Adopt the orphaned children processes (
initprocess usually will adopt orphaned processes)
About init
In UNIX-like OS, init is the first process started by the kernel during booting of the computer system. Init is a daemon process that continues running until the system is shut down. It is the direct or indirect ancestor of all other processes, and automatically adopts all orphaned processes.
Init is a user process like any other processes, and hence it is using virtual memory. The only special thing about init is that it is one of the two processes that the kernel started initially. When init is started by the kernel, it goes into user mode. When init calls system call fork(), it traps into the kernel mode, and the kernel does certain things to create the new process, and the new process will be scheduled in the future. When the fork() returns, the original process is back to user mode. The equivalent of init in macOS is launchd.
Zombie Processes
Zombie processes are processes that are ALREADY TERMINATED, and memory as well as other resources are freed, but its exit status is not read by their parents, hence its entry (PCB) in the process table remains.
A parent process must call wait or waitpid to read their children’s exit status. A call to wait or waitpid blocks the calling process until one of its child processes exits or a signal is received. Otherwise, their child process becomes a zombie process.
Children processes can terminate themselves after they have finished executing their tasks using exit(int status) system call.
- The kernel will free the memory and other resources from this process, but not the PCB entry.
- Parent processes are supposed to call
waitorwaitpidto obtain the exit status of a child. - Only after
waitorwaitpidin the parent process returns, the kernel can remove the child PCB entry from the system wide process table. - If the parents didn’t call
waitorwaitpidand instead continue execution of other things, then children’s entry in the pcb remains; a zombie process remains.
A zombie process generally takes up very little memory space, but pid of the child remains. Recall that pid is unique, so for example in a 32-bit system, there’re only 32768 available pids (thats what set by the OS). Well, actually it is 32767, because pid 0 and 1 are reserved, so user processes get 2 to 32767. On 64-bit systems, the maximum PID is 2^22.
You can find the maximum PID value for your system in Linux using cat /proc/sys/kernel/pid_max:

Having too many zombie processes might result in inability to create new processes in the system, simply because we may run out of pid.
All processes transition to this zombie state when they terminate, but generally they exist as zombies only briefly. Once the parent calls wait, waitpid the pid of the zombie process and its entry in the process table are released.
If a parent process has died, then all the zombie children will be cleared by the kernel. To observe zombie children, you need to artifically suspend the parent process after the children have terminated.
Running shell command in the background
In the lab, you’ve met the & operator which allows us to run a command in the background, for instance, exploit.sh from Lab 3 TOCTOU:
../Root/vulnerable_root_prog userfile.txt test-user-0 & ln -sf /etc/shadow userfile.txt & NEWFILE=`ls -l /etc/shadow`
This means that the shell returns control to the user and does not explicitly wait() for the child process to complete. However, this does not mean that zombie processes will be formed when these child processes terminate. Instead, there’s a way to ignore and prevent zombie processes from happening by declaring beforehand that the parent process does not need to reap the exit status of the child. You can read this appendix section if you’re interested.
Program: Zombie making
Compile and run the C program below. It will suspend itself at scanf, waiting for input at stdin. Do not type anything, leave it hanging there.
Question
What’s the (possible) maximum number of zombies created by this process?
#include <sys/wait.h>
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
int level = 5;
pid_t pid[level];
for (int i = 0; i < level; i++)
{
pid[i] = fork();
if (pid[i] < 0)
{
fprintf(stderr, "Fork has failed. Exiting now");
return 1; // exit error
}
else if (pid[i] == 0)
{
printf("Hello from child %d \n", i);
return 0;
}
}
int testInteger;
printf("Enter an integer: "); // artificially blocking parent
scanf("%d", &testInteger);
return 0;
}
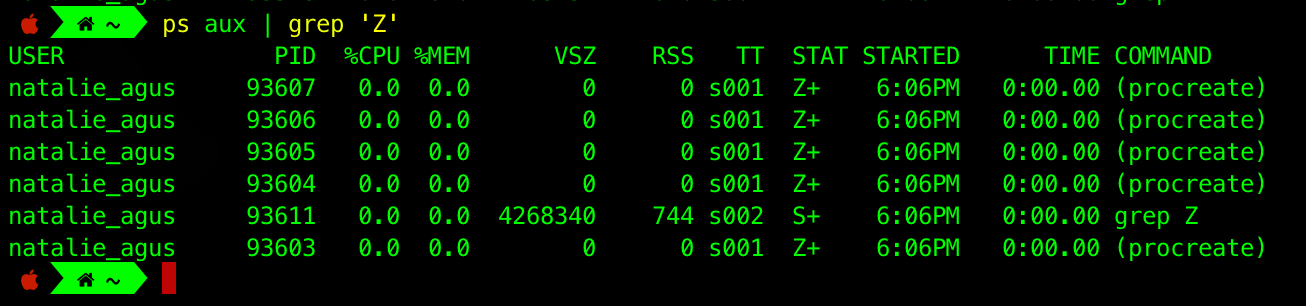
We can enter the ps aux | grep 'Z' command to list all zombie processes in the system caused by running the program above.
Summary
This chapter explores the concept of processes within operating systems, defining a process as a dynamic execution instance of a static program. It discusses the lifecycle of processes, from creation to termination, and explains key concepts such as process context, which includes the program counter, registers, and memory allocation. Additionally, it covers process scheduling and states (New, Running, Waiting, Ready, Terminated), illustrating how the OS manages multiple processes efficiently.
Key learning points include:
- Process vs. Program: A process is an active entity with executing code and resources, while a program is a static set of instructions on disk.
- Process Lifecycle and States: Detailed descriptions of process states: new, running, waiting, ready, and terminated, and their transitions.
- Process Management and Scheduling: Discusses how the operating system manages and schedules processes, including the use of the Process Control Block (PCB) and context switching to handle multiple processes efficiently.
- Process Creation and Termination: Explores mechanisms for process creation using
fork()and process termination, including handling orphaned and zombie processes.
Appendix
Exec System Call
The exec family of functions in Unix-like operating systems is used to replace the current process image with a new process image. The functions execlp, execvp, and execv are variants of this family, each serving slightly different purposes based on how they handle arguments and the environment. Here’s a breakdown of their differences:
execlp:- Function Prototype:
int execlp(const char *file, const char *arg, ..., NULL); - Behavior: Searches for the executable named
filein the directories listed in the environment’s PATH variable. It does not require the full path to the executable if it’s located in one of these directories. - Arguments: Takes the name of the program to execute as the first argument, followed by a NULL-terminated list of character strings that represent the arguments to the program. This list must be terminated by a
NULLpointer. - Use Case: Useful when the number of arguments is known at compile time and the program to execute is in the system’s path.
- Function Prototype:
execvp:- Function Prototype:
int execvp(const char *file, char *const argv[]); - Behavior: Similar to
execlpin that it searches for the executable in the PATH. However, instead of taking a variable number of arguments, it accepts an array of pointers to null-terminated strings that represent the arguments to the program. - Arguments: Takes the name of the program and an array of strings as arguments. The array of strings must be NULL-terminated.
- Use Case: Useful when the number of arguments is not known at compile time, and the program to execute is in the system’s path.
- Function Prototype:
execv:- Function Prototype:
int execv(const char *path, char *const argv[]); - Behavior: Executes the program pointed to by
path. Unlikeexeclpandexecvp,execvdoes not search the PATH. You need to specify the full path of the executable. - Arguments: Takes the full path of the program and an array of strings as arguments. The array of strings must be NULL-terminated.
- Use Case: Useful when the program’s location is known and fixed, and you have an array of arguments to pass to the executable.
- Function Prototype:
Each of these functions does not return to the calling process upon successful execution because the calling process’s image is completely replaced by the new program. If there’s an error (e.g., the executable is not found), the function returns -1.
Shell Background Process
When a command is executed in the background in a shell by appending & to it, the shell does not immediately wait() for it. Instead, the shell returns control to the user, allowing them to execute other commands.
However, to prevent the child process from becoming a zombie when it terminates, the shell needs to handle the termination of background processes. This is typically done by periodically calling waitpid() with the WNOHANG option to check for any terminated background processes without blocking the shell.
Here’s a high-level overview of how a typical shell handles background processes and prevents them from becoming zombies:
-
Fork and Execute Command: When a command is executed with
&, the shell forks a new process and executes the command in the child process. -
Parent Process (Shell): The parent process (the shell) does not immediately wait for the child process to terminate. Instead, it returns to the prompt, allowing the user to enter new commands.
-
Reaping Background Processes: The shell periodically reaps any terminated background processes to prevent them from becoming zombies. This is often done in an event loop or signal handler.
Creating a simple event loop with waitpid() and WNOHANG: The shell can periodically call waitpid() with the WNOHANG option to check for terminated child processes without blocking. For example:
while ((pid = waitpid(-1, &status, WNOHANG)) > 0) {
// Handle the termination of the child process with PID 'pid'
}
Using signal Handling: Alternatively, the shell can set up a signal handler for SIGCHLD, which is sent to the parent process when a child process terminates. The signal handler can then call waitpid() to reap the terminated child process. For example:
void sigchld_handler(int signum) {
int status;
pid_t pid;
// Reap all terminated child processes
while ((pid = waitpid(-1, &status, WNOHANG)) > 0) {
// Handle the termination of the child process with PID 'pid'
}
}
// Set up the signal handler
signal(SIGCHLD, sigchld_handler);
Here’s a simple example of a shell handling background processes:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <signal.h>
void sigchld_handler(int signum) {
int status;
pid_t pid;
// Reap all terminated child processes
while ((pid = waitpid(-1, &status, WNOHANG)) > 0) {
printf("Child process %d terminated\n", pid);
}
}
int main() {
char command[256];
pid_t pid;
// Set up the signal handler
signal(SIGCHLD, sigchld_handler);
while (1) {
printf("myshell> ");
fgets(command, sizeof(command), stdin);
if ((pid = fork()) == 0) {
// Child process
execlp(command, command, (char *) NULL);
perror("execlp");
exit(1);
} else if (pid > 0) {
// Parent process: Do not wait for the child process
} else {
perror("fork");
}
}
return 0;
}
In this example, the shell forks a new process for each command and sets up a signal handler to reap any terminated child processes, preventing them from becoming zombies.
-
Because each process is isolated from one another and runs in different address space (forming virtual machines) ↩
-
Heap and stack grows in the opposite direction so that it maximises the space that both can have and minimises the chances of overlapping, since we do not know how much they can dynamically grow during runtime. If the heap / stack grows too much during runtime, we are faced with stack/heap overflow error. If there’s a heap overflow,
mallocwill return aNULLpointer. ↩ -
You can list all processes that are currently running in your UNIX-based system by typing
ps auxin the command line. ↩ -
Image referenced from IBM RedBooks – Linux Performance and Tuning Guidelines. ↩
-
The relation between nice value and priority is: Priority_value = Nice_value + 20 ↩