 50.005 CSE
50.005 CSE
- Deadlock
- The Deadlock Problem
- Deadlock Handling Methods
- Deadlock Prevention
- Deadlock Avoidance
- Deadlock Detection
- Summary
50.005 Computer System Engineering
Information Systems Technology and Design
Singapore University of Technology and Design
Natalie Agus (Summer 2025)
Deadlock
Detailed Learning Objectives
- Discover Finite System Resources
- Describe the concept of finite resources within a computing system.
- Identify different types of system resources and understand their management.
- Discover Resource Management and Lifecycle
- Explain the process of requesting, using, and releasing resources.
- Distinguish between kernel-managed and user-managed resources.
- Explain how mechanisms like semaphores and mutexes are used as resources.
- Analyze Deadlock Situations
- Define deadlock and understand its implications in systems with finite resources.
- Identify and discuss the 4 necessary conditions that lead to deadlock: Mutual Exclusion, Hold and Wait, No Preemption, and Circular Wait.
- Explain through examples how deadlocks can occur in systems.
- Explain Various Deadlock Handling Techniques
- Explain different methods of handling deadlocks: prevention, avoidance, detection, and recovery.
- Compare and contrast the specific strategies within each method to manage deadlocks.
- Explain General Deadlock Prevention Strategies
- Describe strategies to prevent deadlock by breaking one of the four necessary conditions.
- Analyze the advantages and limitations of each prevention strategy.
- Study Deadlock Avoidance Algorithm: the Banker’s Algorithm
- Explain the principles and application of the Banker’s Algorithm for deadlock avoidance.
- Discuss the Safety and Resource Allocation Algorithms as components of the Banker’s Algorithm.
- Explain Deadlock Detection and Recovery
- Explain how to detect deadlocks using algorithms and system state analysis.
- Describe options for recovering from deadlocks, including process termination and resource preemption.
- Evaluate Deadlock Algorithms: Banker’s Algorithm and Deadlock Detection Algorithm
- Critically assess the efficiency, complexity (time and space) and practicality of algorithms used for deadlock handling.
- Discuss the trade-offs involved in choosing different deadlock handling methods.
These learning objectives are designed to provide a comprehensive understanding of how finite resources are managed in computing systems, the challenges posed by deadlocks, and the various strategies employed to prevent, avoid, detect, and recover from deadlocks.
Finite System Resources

A system consists of a finite number of resources to be distributed among a number of competing processes. Each type of resource can have several finite instances. Some example include:
- CPU cycles / cores
- I/O devices
- Access to files or memory locations (guarded by locks or semaphores, etc)
A process must request a resource before using it and must release the resource after using it.
A process may request as many resources as it requires to carry out its designated task. Obviously, the number of resources requested should not exceed the total number of resources available in the system.
For instance: a process cannot request three printers if the system has only two. Usually, a process may utilize a resource in the following sequence:
- Request: The process requests the resource. If the request cannot be granted immediately (for example, if the resource is being used by another process), then the requesting process must wait until it can acquire the resource.
- Use: The process can operate on the resource (for example, if the resource is a printer, the process can print on the printer).
- Release: The process releases the resource.
The request and release of resources may require system calls, depending on who manages the resources.
Kernel Managed Resources
For each use of a kernel-managed resource, the operating system checks to make sure processes who requested these resources has been granted allocation of these resources. Examples are the request() and release() device, open() and close() file, and allocate() and free() memory system calls.
Some implementation detail
A typical OS manages some kind of system table (data structure) that records whether each resource is free or allocated. For each resource that is allocated, the table also records the process to which it is allocated. If a process requests a resource that is currently allocated to another process, it can be added to a queue of processes waiting for this resource.
Developers who write user programs that need kernel-managed resources will simply make the necessary system calls and need not care about how Kernel manages these resources. This is called abstraction.
User Managed Resources
User-managed resources are not protected by the Kernel. For each use of user-managed resources, developers need to deliberately “reserve” (guard) them using semaphores, mutexes, or other critical section solutions learned in the previous chapter.
Recall that the request and release of semaphores can be accomplished through the wait() and signal() operations on semaphores, or through acquire() and release() of a mutex lock. Writing these series of wait() and signal() are solely the decision of the developers writing that program. They have to be very careful in using them or else it might result in a deadlock.
The Deadlock Problem
Deadlock is a situation whereby a set of blocked processes (none can make progress) each holding a resource and waiting to acquire a resource held by another process in the set.
The critical section solutions we learned in the previous chapter prevents race condition, but if not implemented properly it can cause deadlock.
It is important to understand that deadlock is a system-level property, not a flaw in the primitive (CS solution like Semaphore, spinlocks, or mutex) itself.
A Simple Deadlock Example
For example, consider two mutex locks being initialized:
pthread_mutex_t first_mutex;
pthread_mutex_t second_mutex;
pthread_mutex_init(&first_mutex,NULL);
pthread_mutex_init(&second_mutex,NULL);
Two threads doing running these instructions concurrently may (not guaranteed) potentially result in a deadlock:
// Thread 1 Instructions
pthread_mutex_lock(&first_mutex);
pthread_mutex_lock(&second_mutex);
/**
* Do some work
*/
pthread_mutex_unlock(&second_mutex);
pthread_mutex_unlock(&first_mutex);
pthread_exit(0);
/************************************/
// Thread 2 Instructions
pthread_mutex_lock(&second_mutex);
pthread_mutex_lock(&first_mutex); /**
/**
* Do some work
*/
pthread_mutex_unlock(&first_mutex);
pthread_mutex_unlock(&second_mutex);
pthread_exit(0);
/************************************/
Question
Can you identify the order of execution that causes deadlock?
Consider the scenario where Thread 1 acquires first_mutex and then suspended, then Thread 2 acquires second_mutex.
- Neither thread will give up their currently held
mutex, - However they need each other’s mutex lock to continue,
- Hence neither made progress and they are in a deadlock situation.
Deadlock Necessary Conditions
Deadlock situation may arise if the following four conditions hold simultaneously in a system. These are necessary but not sufficient conditions:
- Mutual exclusion
- At least one resource must be held in a non-sharable mode.
- If another process requests that resource that’s currently been held by others, the requesting process must be delayed until the resource has been released.
- Hold and Wait
- A process must be holding at least one resource and waiting to acquire additional resources that are currently being held by other processes.
- No preemption1
- Resources can only be released only after that process has completed its task, voluntarily by the process holding it.
- Circular Wait
- There exists a cycle in the resource allocation graph (see next section)
“Simultaneously” means all of them must happen to even have a probability of deadlock. These conditions are necessary but not sufficient, meaning that if all four are present, it is not 100% guaranteed that there is currently a deadlock.
4 Necessary Conditions
Since all 4 conditions are necessary for deadlock to happen, removing just one of them prevents deadlock from happening at all.
Resource Allocation Graph
Deadlocks can be described more precisely in terms of a directed graph called a system resource-allocation graph. This graph describes the current system’s resource allocation state. It can give us several clues on whether a deadlock is already happening in the system.
Properties of the graph:
- It has a set of vertices V that is partitioned into two different types of nodes:
- Active processes (circle node) and
- All resource types (square node) in the system
- It has directed edges, from:
- Process to resource nodes: process requesting a resource (request edge)
- Resource to process nodes: assignment / allocation of that resource to the process (assignment edge)
- Resource instances within each resource type node (dots)
Example 1
Suppose a system has the following state:

The resource allocation graph illustrating those states is as follows:
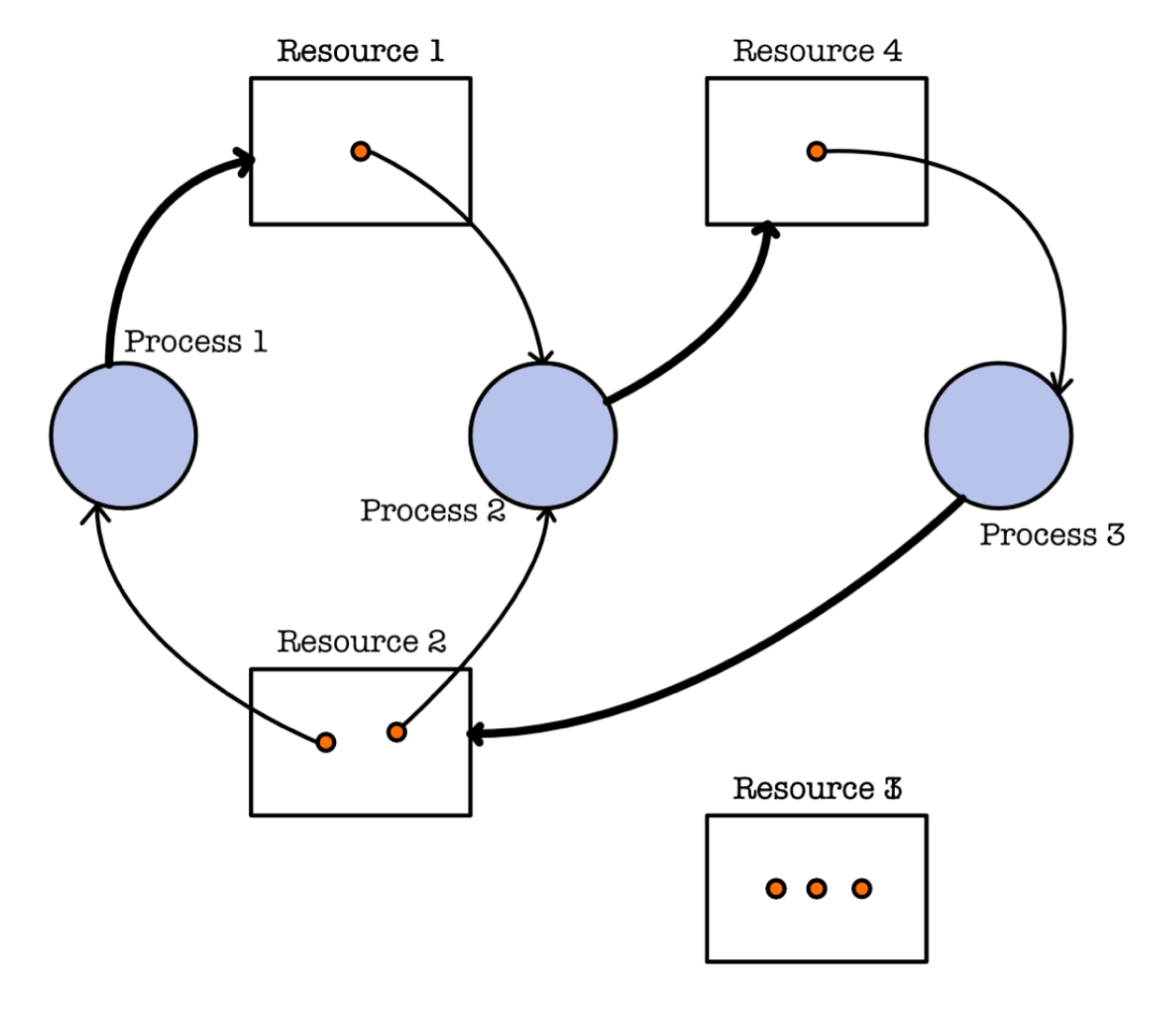
Analysing Resource Allocation Graph
You should apply the following preliminary analysis to determine whether deadlock is present in the system:
- If the graph has no cycle: deadlock will never happen.
- If there’s at least 1 cycle, three possibilities may occur:
- If all resources has exactly one instance, then deadlock (deadlock necessary and sufficient condition)
- If cycle involves only a set of resource types with single instance, then deadlock (deadlock necessary and sufficient condition)
- Else if cycle involves a set of resource types with multiple instances, then maybe deadlock (we can’t say for sure, this is just a necessary but not sufficient condition)
In Example 1 graph above, these three processes are deadlocked (process and resource is shortened as P and R respectively):
P1needsR1, which is currently held byP2P2needsR4, which is currently held byP3P3needsR2, which is currently held by eitherP1orP2
Neither process can give up their currently held resources to allow the continuation of the others resulting in a deadlock.
Example 2
Now consider the another system state below. Although cycles are present, this system is not in a deadlocked state because:
P1might eventually releaseR2after its done, andP3may acquire it and eventually complete its execution- Finally,
P2may resume to completion afterP3is done.
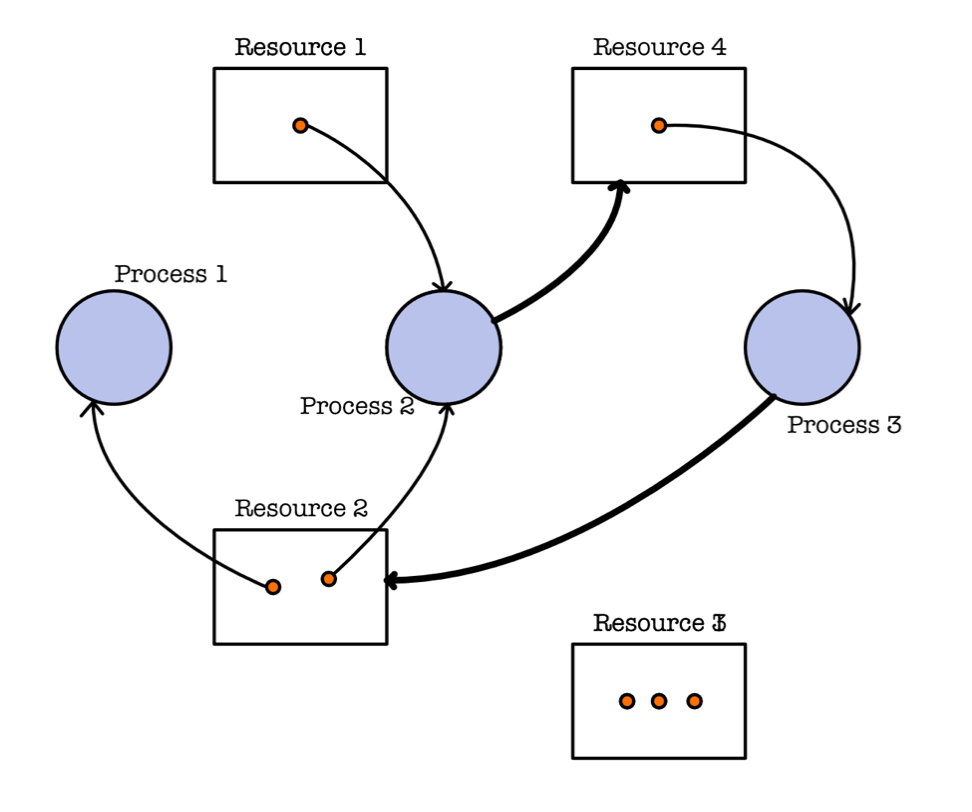
Deadlock Handling Methods
There are three deadlock handling methods in general:
- Deadlock Prevention
- Deadlock Avoidance
- Deadlock Detection
Deadlock Prevention
Deadlock prevention works by ensuring that at least 1 of the necessary conditions for deadlock never happens.
Mutual Exclusion Prevention
We typically cannot prevent deadlocks by denying the mutex condition, because some resources are intrinsically non-sharable. For example, a mutex lock cannot be simultaneously shared by several processes.
Hold and Wait Prevention
To ensure that hold and wait never happens, we need to guarantee that whenever a process requests for a resource, it does not currently hold any other resources.
This is possible through such protocols:
- Protocol 1: Must have all of its resources at once before beginning execution, otherwise, wait empty handed.
- Protocol 2: Only can request for new resources when it has none.
Example
Consider a process that needs to write from a DVD drive to disk and then print a document from the disk to the printer machine.
With protocol 1: The process must acquire all three resources: DVD drive, disk, and printer before beginning execution, even though the task with the disk and DVD drive has nothing to do with the printer. After it finishes both tasks, it releases both the disk and printer.
With protocol 2: The process requests for DVD drive and disk, and writes to the disk. Then it releases both resources. Afterwards, it submits a new request to gain access to the disk (again) and the printer, prints the document, and releases both resources.
Disadvantages
Starvation: Process with protocol 1 may never start if resources are scarce and there are too many other processes requesting for it.
Low resource utilization: With Protocol 1, resources are allocated at once but it is likely that they aren’t used simultaneously (e.g: the sample process requests a printer but it doesn’t utilize it when writing to disk first). With Protocol 2, lots of time is wasted for requesting and releasing many resources in the middle of execution.
No Preemption Prevention (Allow Preemption)
To allow preemption, we need a certain protocols in place to ensure that progress is not lost.
A process is holding some resources and requests another resource that cannot be immediately allocated to it (that is, the process must wait). We can then decide to do either protocols below:
- Protocol A: All resources the process is currently holding are preempted – implicitly released.
- Protocol B: We shall perform some checks first if the resources requested are held by other waiting processes or not. Then two possibilities may happen:
- If held by other waiting process: preempts the waiting process and give the resource to the requesting process
- If neither held by waiting process nor available: requesting process must wait.
These protocols are often applied to resources whose state can be easily saved and restored later, such as CPU registers and memory space. It cannot generally be applied to such resources as mutex locks and semaphores.
Circular Wait Prevention
To prevent circular wait, one must have a protocol that impose a total ordering of all resource types, and require that each process requests resources according to that order.
Example
We are free to implement a protocol that ensures total ordering of all resource types however way we want. For instance, we can assign some kind of id to each resource and some resource acquiring protocols such as:
- The highest priority order of currently-held resources should be less than or equal to the current resource being requested, otherwise the process must release the resources that violate this condition.
- Each process can request resources only in an increasing order of enumeration.
This burdens the programmer to ensure the order by design to ensure that it doesn’t sacrifice resource utilization unnecessarily.
Deadlock Avoidance
In deadlock avoidance solution, we need to spend some time to perform an algorithm to check BEFORE granting a resource request, even if the request is valid and the requested resources are now available.
This Deadlock Avoidance algorithm is called the Banker’s Algorithm. Its job is to compute and predict whether or not a current request will lead to a deadlock.
- If yes, the current request for the resources will be rejected,
- If no, the current request will be granted.
This algorithm needs to run each time a process request any shared resources, which makes it costly to run.
The Banker’s Algorithm
The Banker’s Algorithm is comprised of two parts: The Safety Algorithm and the Resource Allocation Algorithm. The latter utilises the output of the former to determine whether the currently requested resource should be granted or not.
Required Information
Before we can run the algorithm, we need to have the following information at hand:
- Number of processes (consumers) in the system (denoted as
N) - Number of resource types in the system (denoted as
M), along with initial instances of each resource type at the start. - The maximum number of resources required by each process (consumers).
In code, a resource can be:
- A mutex lock (Java: synchronized, Python: threading.Lock())
- A file handle
- A GPU/CPU core if there are quotas
- A limited pool of connections or threads
The System State
Using the above prior known information, the banker’s algorithm maintains these four data structures representing the system state:
available: 1 by M vectoravailable[i]: the available instances of resourcei
max: N by M matrixmax[i][j]: maximum demand of processifor resourcejinstances
allocation: N by M matrixallocation[i][j]: current allocation of resourcejinstances for processi
need: N by M matrixneed[i][j]: how much more of resourcejinstances might be needed by processi
Part 1: Resource Allocation Algorithm
You will be implementing this algorithm during Lab. As such, detailed explanation of the algorithm will not be repeated here.
This algorithm decides whether to give or not give resources to requesting processes over time. As time progresses, more resource request or resource release can be invoked by any of the processes. Releasing resources is a trivial process as we simply update the allocation, available, and need data structures. However, for each resource request received, we need to run the Safety Algorithm (next section) once. The output of the algorithm can be either Granted or Rejected depending on whether the system will be in a safe state if the resource is granted
Part 2: The Safety Algorithm
You will be implementing this algorithm during Lab. As such, detailed explanation of the algorithm will not be repeated here.
This algorithm receives a copy of available (named as work), need, and allocation data structures to perform a hypothetical situation of whether the system will be in a safe state if the current request is granted.
If we find that all processes can still finish their task (the elements of the finish vector is all True), then the system is in a safe state and we can grant this current request.
For example, given the following system state:
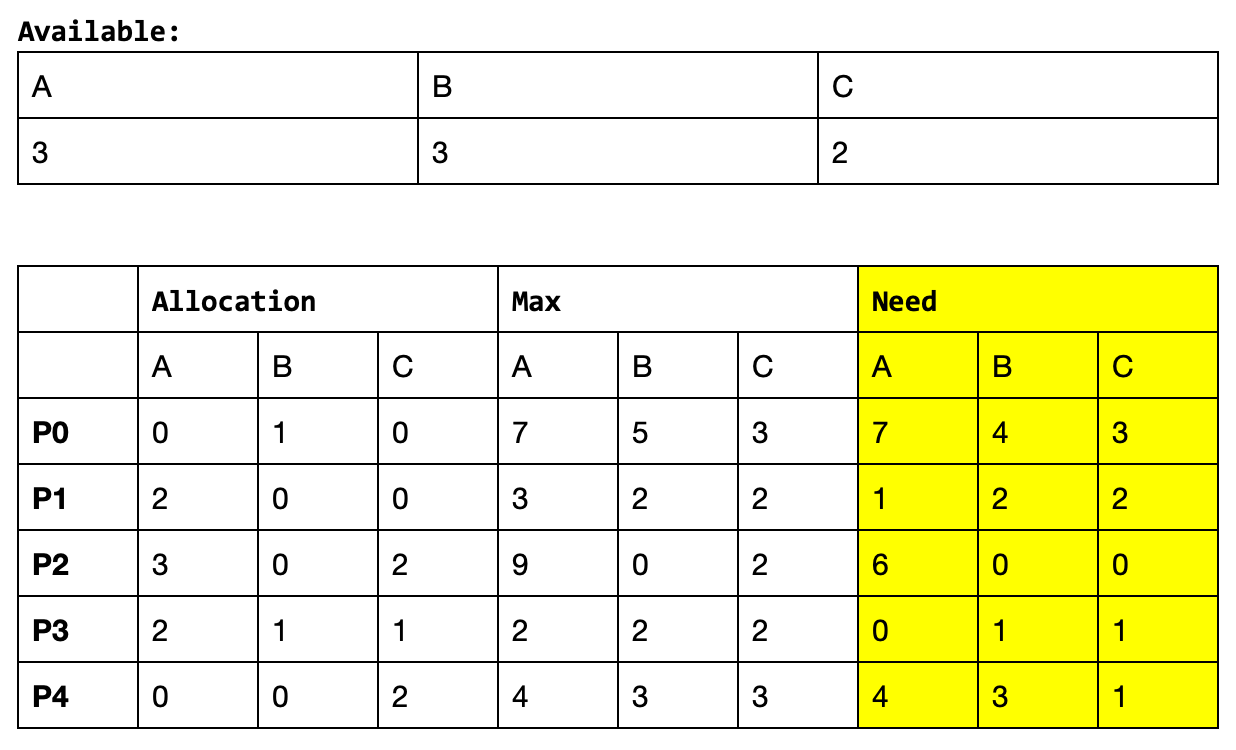
Suppose there exist a current request made by P1: [1,0,2]. You may find that granting this request leads to a safe state and there exist several possible execution sequence (depending on how you iterate through the finish vector, from index 0 onwards or from index N-1 backwards):
P1, P3, P4, P0, P2,P1, P3, P4, P2, P0
If you randomly iterate through the finish vector, you might end up with these other sequences too (which are also valid safe sequences):
P1, P3, P2, P4, P0P1, P3, P2, P0, P4P1, P3, P0, P2, P4P1, P3, P0, P4, P2P1, P4, P3, P0, P2P1, P4, P3, P2, P0
In this algorithm, you can also compute the sequence of possible process execution sequence if you store each value of index i acquired. This sequence is not unique.
In summary, the safety algorithm will return two possible output: safe or unsafe:
-
Safe State: A state is considered safe if there exists a sequence of all processes such that each process can be allocated the maximum resources it may need, then return all the allocated resources back, and this can be done for all processes without causing a deadlock. In other words, there is at least one sequence of process execution that avoids deadlock.
-
Unsafe State: A state is unsafe if no such sequence exists. However, being in an unsafe state does not guarantee that a deadlock will occur; it simply means that there is a possibility of a deadlock if future resource requests are not handled properly.
Unsafe != Guarantee of Deadlock
Entering an unsafe state does not guarantee a deadlock will occur. Here’s why:
- Potential for Future Resource Availability: Even if the current state is unsafe, future resource releases by other processes might allow the system to avoid deadlock. For instance, some processes might complete and release their resources, potentially creating a safe sequence that wasn’t apparent initially.
- Future Requests Might Be Different: Processes might not request the maximum resources they are theoretically entitled to. They might request fewer resources or none at all, which can also prevent a deadlock.
- Preemption: In some systems, certain resources or processes might be preempted or forcibly taken back from a process, allowing other processes to proceed and potentially avoid a deadlock situation.
- Resource Release: Some process might release its resources at one point in time, making it possible for other processes to progress.
System State Update
Note that these requests are made sequentially in time, so don’t forget to update the system state as you grant each request. When considering subsequent new requests, we perform the resource allocation algorithm with the UPDATED states that’s modified if you have granted the previous request.
However, the previous request is rejected, there’s no change in system state is made and you can leave the data structures as-is. This means that the requesting process must wait and send the request again in the future.
Algorithm Complexity
Deadlock avoidance is time-consuming, since due to the expensive while loop in the safety algorithm. The time complexity of the safety algorithm is \(O(MN^2)\) (which is also the complexity of the Banker’s Algorithm, since the complexity of the Resource Allocation Algorithm is way smaller).
Carefully think the Banker’s Algorithm is time consuming and compute its time complexity. Also, ask yourself: what is the space complexity of the Banker’s Algorithm?
Deadlock Detection
In deadlock detection, we allow deadlock to happen first (we don’t deny its possibility), and then detect it later.
Deadlock detection method is different from deadlock avoidance. The latter is one step ahead since will not grant requests that may lead to deadlocks in the first place.
Deadlock detection mechanism works using two steps:
- By running an algorithm that examines the state of the system to determine whether a deadlock has occurred from time to time,
- And then running algorithm to recover from deadlock condition (if any)
Deadlock Detection Algorithm
This algorithm is similar to the Safety Algorithm (Part 2 of the Banker’s Algorithm), just that this algorithm is performed on the actual system state (not the hypothetical work, need and allocation).
Firstly, we need all the state information as per the Banker’s algorithm: the available, request(renamed from need), and allocation matrices (no max/need). The only subtle difference is only that the need matrix (in safety algorithm) is replaced by the request matrix.
In a system that adapt deadlock detection as a solution to the deadlock problem, we don’t have to know the max(resource needed by a process), because we will always grant a request whenever whatever’s requested is available, and invoke deadlock detection algorithm from time to time to ensure that the system is a good state and not deadlocked.
The request matrix contains current requests of resources made by all processes at the instance we decide to detect whether or not there’s (already) a deadlock occuring in the system.
Row
iin therequestmatrix stands for: Processirequiring some MORE resources that’s what’s been allocated for it.
The deadlock detection algorithm works as follows:
- Step 1: Initialize these two vectors:
work(length is #resourcesM) initialized to be ==availablefinish(length is #processesN) initialized to be:Falseifrequest[i]!= {0} (empty set)- True
otherwise(means process i doesn’t request for anything else anymore and can be resolved or finished)
- No update of
allocation, needneeded. We are checking whether the CURRENT state is safe, not whether a HYPOTHETICAL state is safe.
- Step 2: find an index
isuch that both conditions below are fulfilled,finish[i] == Falserequest[i] <= work(element-wise comparison for these vectors)
- Step 3:
- If Step 2 produces such index
i, updateworkandfinish[i],work += allocation[i](vector addition)finish[i] = True- Go back to Step 2
- If Step 2 does not produce such index
i, prepare for exit:- If
finish[i] == Falsefor somei, then the system is already in a deadlock (caused by Processigetting deadlocked by another Processjwherefinish[j] == Falsetoo) - Else if
finish[i] == Truefor alli<N, then the system is not in a deadlock.
- If
- If Step 2 produces such index
Complexity of Deadlock Detection Algorithm
This deadlock detection algorithm requires an order of \(O(MN^2)\) operations to perform.
Frequency of Detection
When should we invoke the detection algorithm? The answer depends on two factors:
- How often is a deadlock likely to occur?
- How many processes will be affected by deadlock when it happens?
This remains an open issue.
Deadlock Recovery
After deadlock situation is detected, we need to recover from it. To recover from deadlock, we can either:
- Abort all deadlocked processes, the resources held are preempted
- Abort deadlocked processes one at a time, until deadlock no longer occurs
The second method results in an overhead since we need to run the detection algorithm over and over again each time we abort a process. There are a few design choices we have to make:
- Which order shall we abort the processes in?
- Which “victim” shall we select? We need to determine cost factors such as which processes have executed the longest, etc
- If we select a “victim”, how much rollback should we do to the process?
- How do we ensure that starvation does not occur?
Deadlock Recovery remains an open ended issue. Dealing with deadlock is also a difficult problem. Most operating systems do not prevent or resolve deadlock completely and users will deal with it when the need arises.
Summary
This chapter explores the concept of deadlock in operating systems, a critical issue that arises in concurrent programming when two or more processes are unable to proceed because each is waiting for the other to release a resource. It highlights the necessary conditions for deadlock to occur, including mutual exclusion, hold and wait, no preemption, and circular wait. The guide discusses strategies for preventing and handling deadlock, such as resource allocation graphs, deadlock detection, and recovery mechanisms.
Key learning points include:
- Conditions for Deadlock: Understanding the specific conditions that must all be present for a deadlock to occur.
- Deadlock Prevention and Avoidance: Techniques to prevent deadlock by structurally eliminating the possibility of its conditions, and using algorithms like the Banker’s Algorithm to avoid deadlocks dynamically.
- Deadlock Detection and Recovery: Methods to detect deadlocks and strategies to recover from them, such as process termination or resource preemption.
By understanding the causes and solutions to deadlock, programmers can design more robust and efficient concurrent systems.
-
Preemption: the act of temporarily interrupting a task being carried out by a process or thread, without requiring its cooperation, and with the intention of resuming the task at a later time. ↩