A file is a named collection of related information that is stored on the secondary storage. It acts as a logical storage unit in the computer, defined by the operating system. In layman terms, they are a group of data bytes which are stored neatly in a known location with a unique name (path).
Files are mapped by the operating system onto physical devices that are non-volatile. Sometimes they are memory-cached for performance.
Volatile storage devices are unable to store any data after the power source is removed.
- Physical memory (RAM) is generally volatile.
- SSDs, HDDs, and thumbdrives are non-volatile.
In this chapter, we will specifically learn about UNIX File system.
There are two types of file: regular files and directories. More information can be found in the later parts.
- Directories:
- Has a structured namespace, e.g: /users/Desktop
- Regular files:
- Can represent programs, or data
- Can take any format: .txt, .bin, etc
- Can contain any information defined by its creator
File Example
Consider the file with name: Banker.c below.
- The file consists of file attributes and file content.
- File attributes (stored in inode) contain important metadata such as name, size, datetime of creation, user ID, etc.
- Its content is a group of data bytes (~12KB) containing instructions to the Banker’s algorithm written in C.
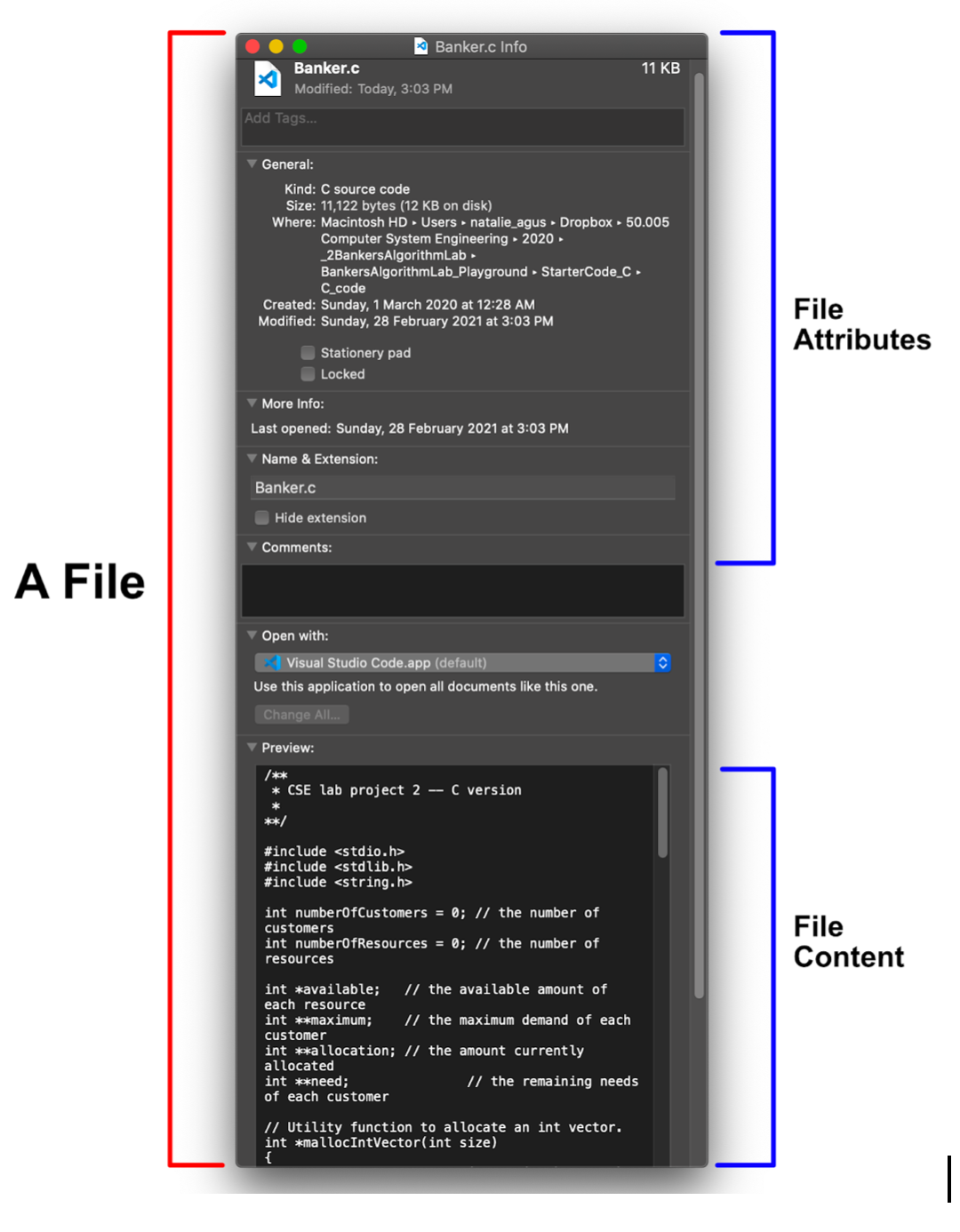
When we use this file, we don’t care about its physical address (where it is actually stored on disk). We only care about its path. The path is a “logical” storage unit.
Content Structure
File content structure that can exist in your computer varies greatly:
- None: uninterpreted sequence of bytes
- Simple:
- Lines (text files)
- Fixed Length Records (structured database, e.g: NRIC)
- Variable Length Records (unstructured database, e.g: audio, video, books, are all of variable length)
- Complex Structure:
- Executable files (
ELFfiles)
- Executable files (
File Format and Type
File format is the actual data structure of a certain file, defining the syntax (permitted values, formal structure or grammar) and semantics (meaning and interpretation) of data within a file.
File type is a group of file formats that serve similar functions. For instance: arc, zip, and tar are all the format of archive file type. The image below illustrates the common examples (don’t have to memorise them, image taken from SGG book):
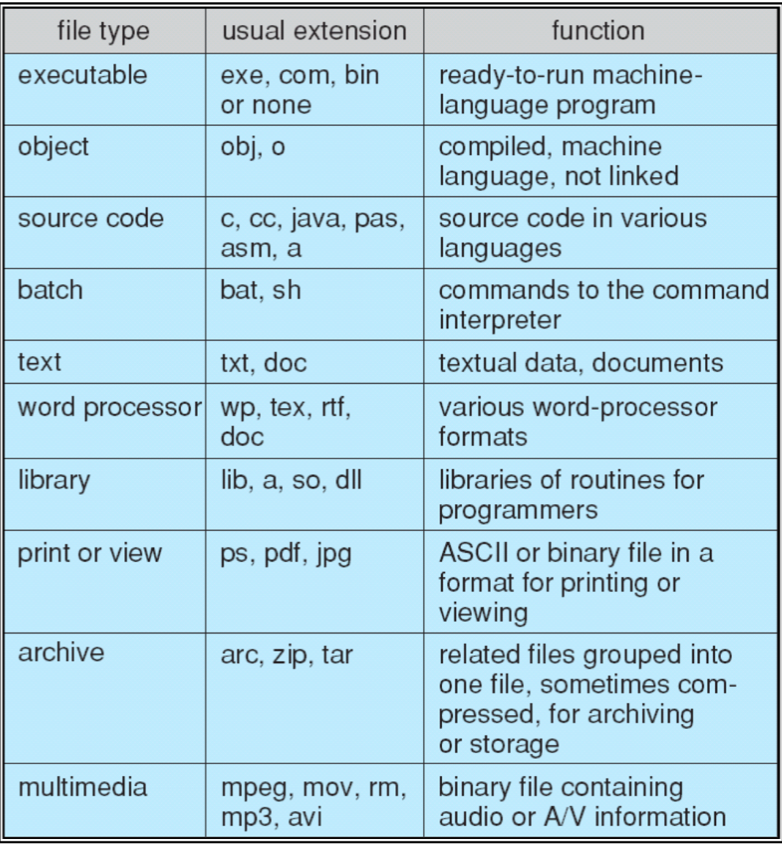
You can tell that different files have different formats from its extension. Some OS replaces the icons of the files depending on its extension to give us a visual representation of the file format.
File Extension vs File Format
A file extension is the character or group of characters after the period that makes up an entire file name. It often indicate the file type, or file format, of the file, but not always. We usually add it with a dot in the file name, e.g: grades.xls
- The file extension helps an OS to determine which program on your computer the file is associated with.
- For example, files ending with .xls will be associated with Excel – opening it will open Excel and load that file into Excel.
Any file’s extension can be renamed, but that won’t convert the file to another format or change anything about the file other than this portion of its name.
Hence, a file with a PDF format will NOT be converted into a ZIP format by simply changing it’s name from submission.pdf to submission.zip. You will need a tool (e.g: the zip system program) to convert its format into an actual ZIP formatted file.
Another example: a file named grades.csv contains an extension that is appropriately related to its actual format: comma separated values. A computer user could rename that file to grades.mp3, however that wouldn’t mean you could play the file as some sort of audio on a media player. The file itself is still rows of text (a CSV file), not a compressed musical recording (an MP3 file).
File Interpreters
Who can read and understand the content of the file?
- The OS Kernel:
- UNIX-based OS implements directories as special files
- It knows the difference between directory & regular files;
- It supports executable files
- Doesn’t otherwise require/interpret any formats of other regular files
- System Programs:
- Linker or loader that knows
ELFformatted files - Compilers that know certain file script formats (e.g:
.cforgcc)
- Linker or loader that knows
- User/Application Programs:
- Web browser understands HTML, web-assembly format
- Video players understands .mp4 format
- PDF readers understands .pdf format
- Excel understands .xls format, along with .csv
File Abstract Data Type
A file can be seen as an abstract data type, that will be implemented differently depending on the OS supporting it. Some file structures are universal (can be identified by any OS and the OS can find a suitable interpreter app in the system), such as .txt and .pdf files. However, some others are system specific.
Regardless of the structure, we can abstract the concept of file as having file attributes and file interface.
File Attributes
A file has attributes (metadata), analogous to how a class/object has states. These include:
- Name:
- The symbolic file name is the only information kept in human readable form (stored in directory)
- Identifier:
- This unique tag,usually a number, identifies the file within the file system; it is the non-human-readable name for the file (stored in inode, also known as inode id)
- Type/Format:
- This information is needed for systems that support different types of files.
- Location:
- This information is a pointer to a device and to the location of the file on that device.
- Size:
- The current size of the file (in bytes, words, or blocks) and possibly the maximum allowed size are included in this attribute.
- Protection:
- Access-control information determines who can do reading, writing, executing, and so on.
- Time, date, and user identification:
- This information may be kept for creation, last modification, and last use. These data can be useful for protection, security, and usage monitoring.
You can use the command ls -ali to list all files in the current directory, together with its identifier (inode number, will be explained in the later section):
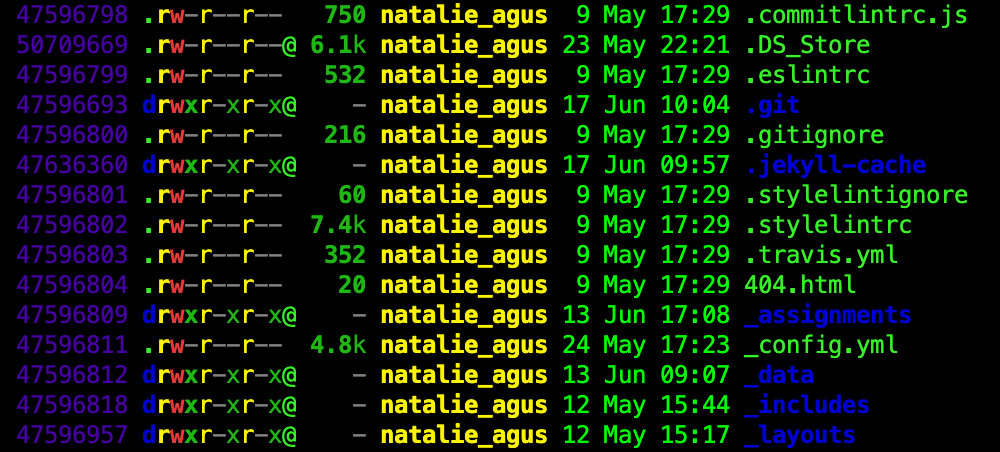
You should know how to interpret file permission from Lab 1.
File Interface
We can perform operations on files, and these operations are possible through the file interface or methods, analogous to the interface/methods we implement for classes in OOP.
Operations that can be performed on files are: create, read, write, delete, reposition, and truncate among many others.
File Creation
To create a file, we need to ensure two things are done:
- A free space in the system storage must be found for the file.
- An entry for the new file must be made in the directory (details provided later).
File Read and Write
In order to R/W to a file, you must first have the permission to open the file.
Remember from Lab 1: The creator of the file can modify such permissions using
chmodcommand.
If permitted, you must then:
- Open the file.
- This can be done using system call
open(). There are other methods of opening the file depending on your programming language.
- This can be done using system call
- Perform the read/write operation using its respective file pointer, to indicate where exactly in the file we want to write or read, byte by byte.
- Close the file.
- This can be done using system call
close().
- This can be done using system call
File Deletion
To delete the file, we need to search the directory to find the file given the file’s path, and also remove it from the file system (more details later). This action also frees the space initially occupied by the file’s content
File Truncation
In file truncation, we want to keep all the file attributes but remove its content. We search the directory given the file’s path. Once found, the file length is reset to be zero, and its file space for the content is released.
File Reposition
This requires us to first have permission to open the file and gain a file pointer. And then we reposition the value of the file pointer to be pointing to other portion of the file (e.g: byte N of the file). This can be done in C using lseek()
Combining File Operations
These basic operations can then be combined to perform more complex file operations. For instance, we can create a copy of a file by creating a new file and then opening and reading from the old file and writing its content to the new one.
The File System
A file system controls how data is stored and retrieved in a system.
It is a set of rules (and features) applicable to determine the way the data is stored. A physical disc can be separated into multiple physical partitions, where each partition can have different file system
The purpose of a file system is to maintain and organize secondary storage. Without a file system, data placed in a storage medium would be one large body of data with no way to tell where one piece of data stops and the next begins.
The file system is able to logically separate the segments of data on disk and give each piece a unique name. Each group of data is the content of a file, and the file attributes may be stored elsewhere (details provided later). The structure and logic rules used to manage these groups of data and their names is called a “file system”.
The File System operates using specific data structure and has a specific format. Its interface is part of the OS, so they vary between operating systems.
Examples of common file system includes (no need to memorise):
- File allocation table (FAT) is supported by the Microsoft Windows OS
- New Technology File System (NTFS) is the default file system for Windows products from Windows NT 3.1 OS onward
- ext4 is a file system for many Linux Distributions
- Universal Disk Format (UDF) is a vendor-neutral file system used on optical media and DVDs
- Hierarchical file system (HFS) was developed for use with Mac operating systems. HFS is succeeded by HFS+
- Apple File System (APFS) for macOS
In this subject we are focused on the UNIX-specific file system and its data structure.
UNIX File System Data Structure
The figure below illustrates a simplified UNIX file system data structure in-memory. All these data structures are implemented in the kernel space:
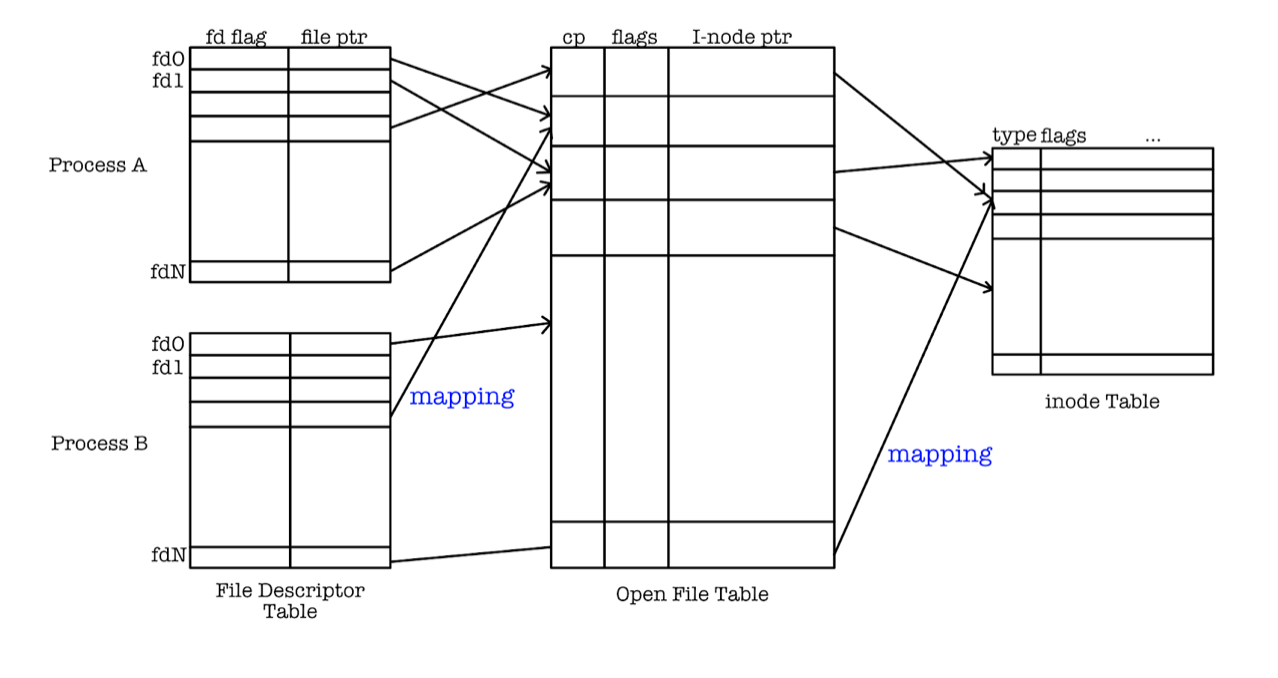
File Descriptor Table
The fd table exists per-process.
Whenever a process open() or dup() a file, the opened file is associated with a file descriptor.
- A file descriptor is a number that uniquely (unique in that process) identifies an open file in a computer’s operating system
- A file descriptor has a file
pointerfield, that is a pointer to the system wide open-file-table.
System-Wide Open File Table (swoft)
Managed by the Kernel, contains a list of opened files and its entries created by open().
Opened files in the system may include disk files, named pipes, network sockets and devices opened by all processes.
The fields of each opened files contains:
cp:current pointer offset, pointing to a specific byte in the file- Access status: such as read, write, append, execute, etc (not drawn)
- Open count: how many fd table entries point to it. We cannot remove open file table entry if reference count is more than 0.
- Inode pointer: a pointer to UNIX inode table.
Inode Table
Short for index node table or File Control Block (FCB): a database of all file attributes and location of file contents.
It does not contain the content of any file, and it also does not contain any file name. Each file is associated with an inode and has a unique inode number. You may view inode number of each file in the current directory using the command ls -i.
File name is stored in another file system cataloguing structure called directory (more details later).
Example
This example is created for you to observe per-process file descriptor table. Suppose there’s a blocking C-code as follows, compiled, and its binary output called out is stored at /Users/natalie_agus/Desktop:
#include <stdio.h>
#include <stdlib.h>
int main(){
char str1[20];
printf("Enter name: ");
scanf("%s", str1);
printf("Name entered : %s \n", str1);
fprintf(stdout, "EXIT! \n");
return 0;
}
The blocking instruction scanf is there to make the process not terminate yet, so that we can have enough time to observe it’s file descriptor table. Running this process twice, and then running the command ps | grep ./out | grep -v grep in the third terminal results in:
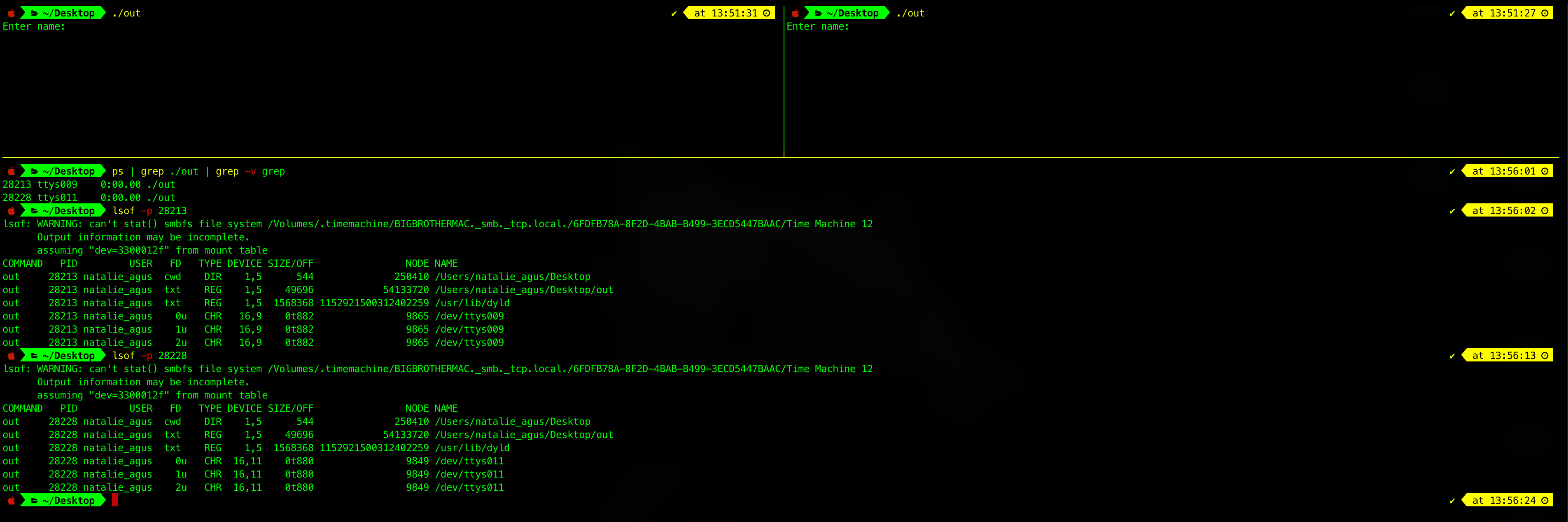
As you can see, there’s two instances of ./out at two terminals: ttys009 and ttys011. We can examine its file descriptor table content with the command lsof -p [pid].
There are 3 standard fd per process:
- 0u: This is
stdin(standard input stream), obtained from the terminal (eg:/dev/ttys011) - 1u: This is
stdout(standard output stream), directed to the terminal - 2u: This is
stderr(standard error stream), directed to the terminal as well
Currently, scanf is blocking as it is “listening” from stdin (fd 0). Whatever we typed at the terminal window can be passed to the process, and then passed back out to stdout. The function printf() automatically outputs to stdout. Otherwise, we can explicitly “ask” the program to print to stdout using fprintf(stdout, … ).
Another observation that we can notice is that both processes are pointing to file with inode id 54133720, that is the inode id of the binary out (the program code).
This is an example of how the same program can be used to create multiple processes,
File Usage Information
It is not a good idea to pass file name to every file system operation (e.g., read(), open(), write(), etc) because:
- Name can be really long and of variable length
- Mapping of name to internal data structures takes time
A program translates name into file descriptor (“handle” to the file) at the beginning of a usage session.
fd is (integer) index into a per-process file-descriptor (fd) table. Its numerical index has meaning only in the context of its process. You witness this in the above example.
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
int main() {
int fd_a, fd_b, n;
char str[100];
/* 1. open a file in read mode */
fd_a = open("input.txt", O_RDONLY, 0);
/* create an output file with read write permissions, 0666 is the file permission created, the 0 in front means OCTAL notation --- 666 is the octal notation
if you want to create a directory, the same permission logic can be made also, but directories ARE EXECUTABLES:
if (mkdir("myFolder", 0777) == -1)
cerr << "Error : " << strerror(errno) << endl;
else
cout << "Directory created!";
*/
/* then, open a file in RW mode */
fd_b = open("output.txt", O_CREAT | O_RDWR, 0666);
/* 2. read the data from input file and write it to output file */
while ((n = read(fd_a, str, 10)) > 0) {
write(fd_b, str, n);
}
/* 3. move the cursor to the 13th byte of the input file */
lseek(fd_a, 12, 0);
/* write the given text in output file */
write(fd_b, "\nMoved cursor to 13th byte:\n", 28);
/* writes the contents of input file from 12 byte to EOF */
while ((n = read(fd_a, str, 10)) > 0) {
write(fd_b, str, n);
}
/* 4. close both input and output files */
close(fd_a);
close(fd_b);
return 0;
}
- The system call
open()with different arguments: one to read, the other to write.- Two file descriptors, fd_a and fd_b are returned from the system call. Now the program can read the content of
input.txt. input.txtis a text file with content “abcdefghijklmnopqrstuvwxyz” (the entire 26 alphabets, 26 bytes in content size).
- Two file descriptors, fd_a and fd_b are returned from the system call. Now the program can read the content of
- We can perform
readsystem call andwritesystem call with opened files throughfd_aandfd_b.- We no longer have to associate it with the name input.txt and output.txt
- Afterwards, we change the current pointer (
cp) of the file using system calllseek.- This updates the entry for this file in the system-wide opened file table. We move the pointer to point to the 13th byte, which is the letter ‘m’
- Do not forget to close the file descriptor using the
close()system call.
Upon execution, we found that the output.txt contains:
abcdefghijklmnopqrstuvwxyz
Moved cursor to 13th byte:
mnopqrstuvwxyz
File System Mapping
Case 1: Multiple file descriptor table entries can point to the same system-wide open file table entry.
For example:
- Two or more processes read the same file via:
- File descriptors are created by one of them and then passed through socket, or
- A child inheriting the parent’s file descriptor after
fork(). Note that child and parent processes have a separated file descriptor table (note that they are two different, separate processes)
- A single process that has two or more file descriptors referencing to the same file. In fact, you can do this by doing the system call
dup()ordup2()
Case 2: Multiple system-wide open file table entries can point to the same file in the inode table.
We can do this by calling open to the same file from multiple different processes. The system call open() creates a new entry in the swoft.
Both cases are considered as many-to-one mapping.
Example with dup and dup2
Look at the following example that illustrates Case 1.
int fd_a, fd_b, fd_c, n;
char str;
/* open an input file in read mode */
fd_a = open("input.txt", O_RDONLY, 0);
// fd_b will be the LOWEST available fd, which is 4
fd_b = dup(fd_a);
fd_c = dup2(fd_a, 9); // custom fd 9
We open(input.txt), and then duplicate the returned file descriptor as fd_b and fd_c.
The difference between the two system calls is that dup() will return the lowest available fd, which is 4 (since 0, 1, and 2 are reserved (set by default due to convention) as stdin, stdout, and stderr, and 3 is already used for open), while dup2(old fd, new fd) allows us to explicitly set the new fd.
If the new fd is already in use then the existing one will be closed first before being reused again. Note that fd 0, 1, and 2 can be closed or changed to point to another file as per other fds. The only difference is that upon process creation, these 3 fds are already set as convenience to stdin, stdout, and stderr.
We can cause the process to block itself (as shown in previous section, use scanf or some blocking operation that waits for user input) and meanwhile print its file descriptor table content (use ps to get its pid, and then use lsof -p pid).
Since they are sharing the same pointer to the system-wide open file table, these actions from fd_a and fd_b affects each other.
Take a look at this example:
/* read the data from fd_a */
printf("From fd_a: ");
int counter = 0;
while ((n = read(fd_a, &str, 1)) > 0) {
printf("%c", str);
counter++;
if (counter > 9) break;
}
printf("\n");
/* read the data from fd_b */
printf("From fd_b: ");
counter = 0;
while ((n = read(fd_b, &str, 1)) > 0) {
printf("%c", str);
counter++;
if (counter > 9) break;
}
printf("\n");
int fd_d = open("input.txt", O_RDONLY, 0);
/* read back the data from fd_a */
printf("From fd_d: ");
counter = 0;
while ((n = read(fd_d, &str, 1)) > 0) {
printf("%c", str);
counter ++;
if (counter > 9) break;
}
printf("\n");
If we read the first 10 char from fd_a, cp in the swoft would’ve been advanced by 10 bytes. Subsequent 10 bytes of read by fd_b will read off from byte 10 to 19. Assuming that input.txt contains all 26 alphabets as mentioned above, the output of the program above will be:
From fd_a: abcdefghij
From fd_b: klmnopqrst
From fd_d: abcdefghij
Note that fd_d is a different entry in the system-wide open file table because a read operation using fd_a and fd_b does not affect the read operation using fd_d.
fd_d does not share the same pointer cp as both fd_a and fd_b.
Appendix
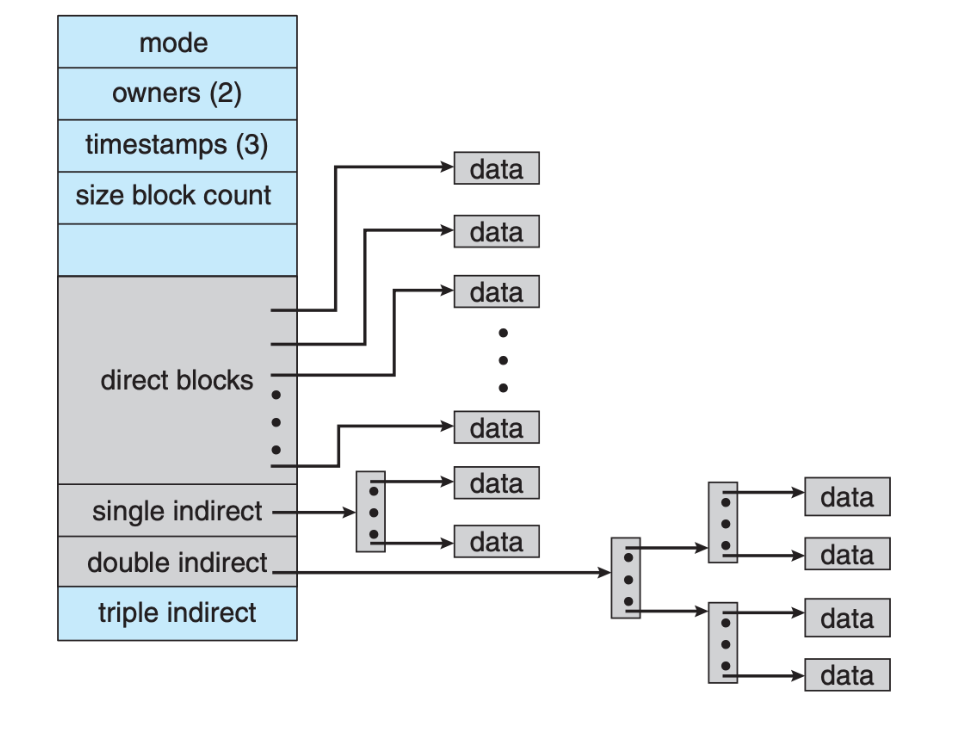
UNIX inode
The inode (index node) is a data structure in a Unix-style file system that describes a file-system object such as a file or a directory, as shown in the image, taken from the SGG book. You can think of it as Unix kernel’s internal data structure to manage its file system. The kernel maintains the inode table (a collection of inodes). Each inode stores the attributes and disk block locations of the object’s data.
The inode is the file, excluding its content, which is identified by a unique inode number. A filename on the other hand, is just metadata in the file system that refers to a file. A single file/inode can have multiple filenames referring to it (called links, which we will learn later).
The Logical and Physical File system
The logical file system is the level of the file system at which users can request file operations by system call. It is responsible for interaction with the user application. This is typically what we see.
The physical file system contains the actual data of the file system and the actual location. E.g: a huge file that is logically represented as one file is not necessarily physically stored near one another (it can be fragmented in the disk).
On disk, the physical file system contain information about how to:
- Boot an operating system stored there,
- The total number of blocks (recall blocksize from 50002)
- The number and location of free blocks,
- The directory structure, and
- Individual files location
The four main components of the entire file system is:
-
The Boot Control Block (per volume): contains information needed by the system to boot an operating system from that volume.
-
The Volume Control Block (per volume): contains volume (or partition) details, such as the number of blocks in the partition, the size of the blocks, a free-block count and free-block pointers, and a free-FCB count and FCB pointers.
-
The Directory Structure (per file system, it can span several volumes): used to organise the files.
-
The File Control Block (per file, also known as inode in UNIX): contains file attributes, has a unique id, and is associated with directory entry.
_Side note about partition vs volume: _
- Partition is always created on a single physical disk, however a volume can span multiple disks and have many partitions.
- Partitions only identified by numbers, but volumes have names.
- Finally, partitions are more suitable for individual devices, while volumes (especially logical volumes) are more flexible and suited for network attached storage.
Example on how user interacts with the logical file system to create a file (simplified):
- An application program calls the logical file system to create a file, e.g: by right click » create.
- The logical file system traverse the directory, and check the requested location.
- To create a new file, it allocates a new inode or FCB.
- The system then update the directory it with the new file name and FCB, and writes it back to the disk.
Mounting File System during Boot
All systems have a root partition, which contains the operating-system kernel and sometimes other system files, which are mounted at boot time. The system has an in-memory mount table that contains information about each mounted volume. Other volumes can be automatically mounted at boot or manually mounted later, depending on the operating system.
The mount procedure:
-
The operating system is given the name of the device and the mount point — the location within the file structure where the file system is to be attached.
-
Typically, a mount point is an empty directory. For instance, on a UNIX system, a file system containing a user’s home directories might be mounted as
/home; then, to access the directory structure within that file system, we could precede the directory names with/home,for example,/home/alice. -
Mounting that file system under
/usersinstead would result in the path name/users/alice, which we could use to reach the same content underalice.
The in-memory (means these are in RAM, as long as the computer is alive) information about file system that is loaded at mount time are the three data structures we show above and a few more:
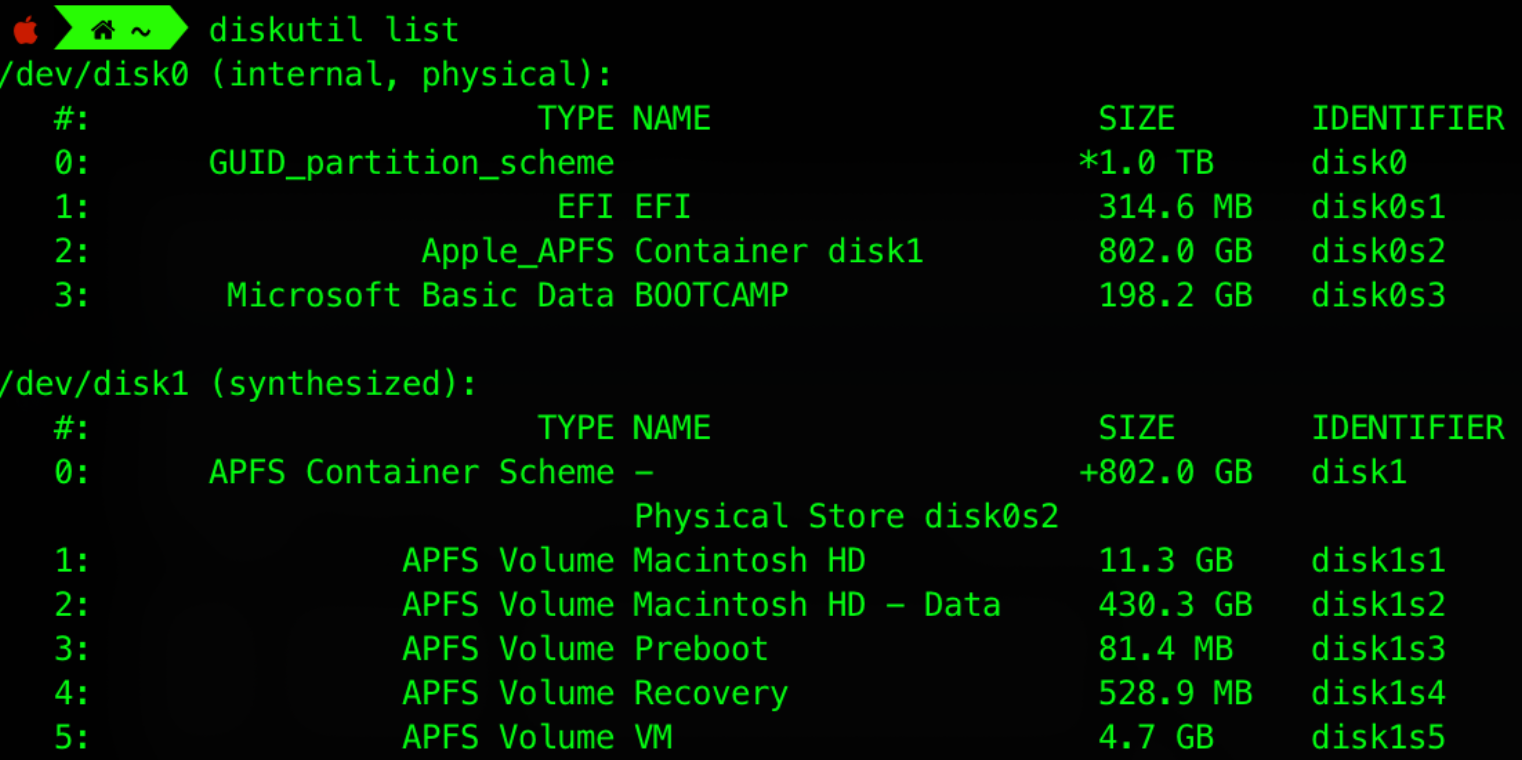
-
Mount-table: contains information about each mounted volume. Notice the list of all mounted volumes in the screenshot below. Disk image, USB drives, all those are also mounted devices.
-
inode table: Contains directory structure and file pointers to the actual data on secondary storage or cached memory
- You can list the disk file directory and see how many inodes are present using
df -i. You should be able to figure out by yourself what each column means, the leftmost one being the filesystem name.

- You can list the disk file directory and see how many inodes are present using
-
System-wide open file table
- You might not want to print this out even if you can, as there’s hundreds, even thousands of files that are probably opened right now.
-
Per-process file descriptor table (for currently alive processes)
- You can check opened files for your current terminal process opened files using
lsof -p $$command.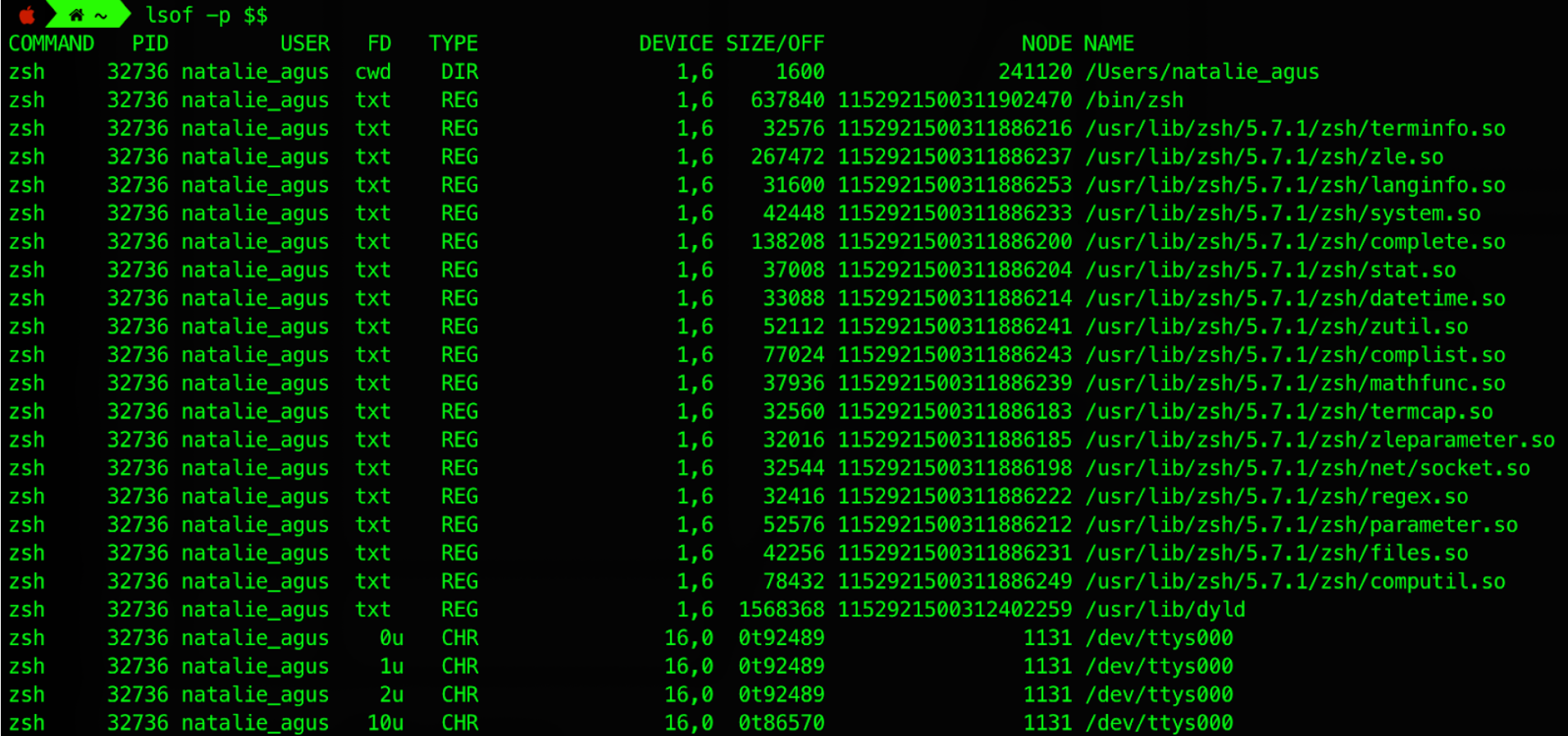
- You can check opened files for your current terminal process opened files using
Details:
FD – the file descriptor. Some of the values of FDs are,
cwd – current Working Directory
txt – text file
mem – memory mapped file
mmap – memory mapped device
<number> – the actual file descriptor.
the character after the number i.e ‘1u’ the MODE in which the file is opened:
r: read,
w: write,
u: read and write
TYPE – specifies the type of the file. Some of the values of TYPEs are,
REG – regular File
DIR – directory
FIFO – first in first out policy
CHR – character special file
NODE - the inode id that it is pointing to.