Process vs Program
→ A process is formally defined as a program in execution. Process is an active, dynamic entity – i.e: it changes state overtime during execution, while a program is a passive, static entity.
- A program is not a process.
- A process is much more than just a program code (text or instruction section).
A Process Context
A single process includes all of the following information:
- The text section (code or instructions)
- Value of the Program Counter (PC)
- Contents of the processor’s registers
- Dedicated1 address space (block of location) in memory
- Stack (temporary data such as function parameters, return address, and local variables, grows downwards),
- Data (allocated memory during compile time such as global and static variables that have predefined values)
- Heap (dynamically allocated memory – typically by calling
mallocin C – during process runtime, grows upwards)2 These information are also known as a process state, or a process context:
The same program can be run n times to create n processes simultaneously.
- For example, separate tabs on some web browsers are created as separate processes.
- The program for all tabs are the same: which is the part of the web browser code itself.
→ A program becomes a process when an executable (binary) file is loaded into memory (either by double clicking them or executing them from the command line)
Concurrency and Protection
→ A process couples two abstractions: concurrency and protection.
Each process runs in a different address space and sees itself as running in a virtual machine – unaware of the presence of other processes in the machine. Multiple processes execution in a single machine is concurrent, managed by the kernel scheduler.
Piggybacking
From this point onwards, we are going to refer simply to the scheduler as the kernel. Remember this is just a running code (service routine) with kernel privileges whose task is to manage processes. Scheduler in itself, is part of the kernel, and is not a process.
Recall how the system calls piggyback the currently running user-process which mode has been changed to kernel mode. Likewise, the scheduler is just a set of instructions, part of the kernel realm whose job is to manage other processes. It is inevitable for the scheduler to be executed as well upon invoking certain system calls such as read or get stdin input which requires some waiting time.
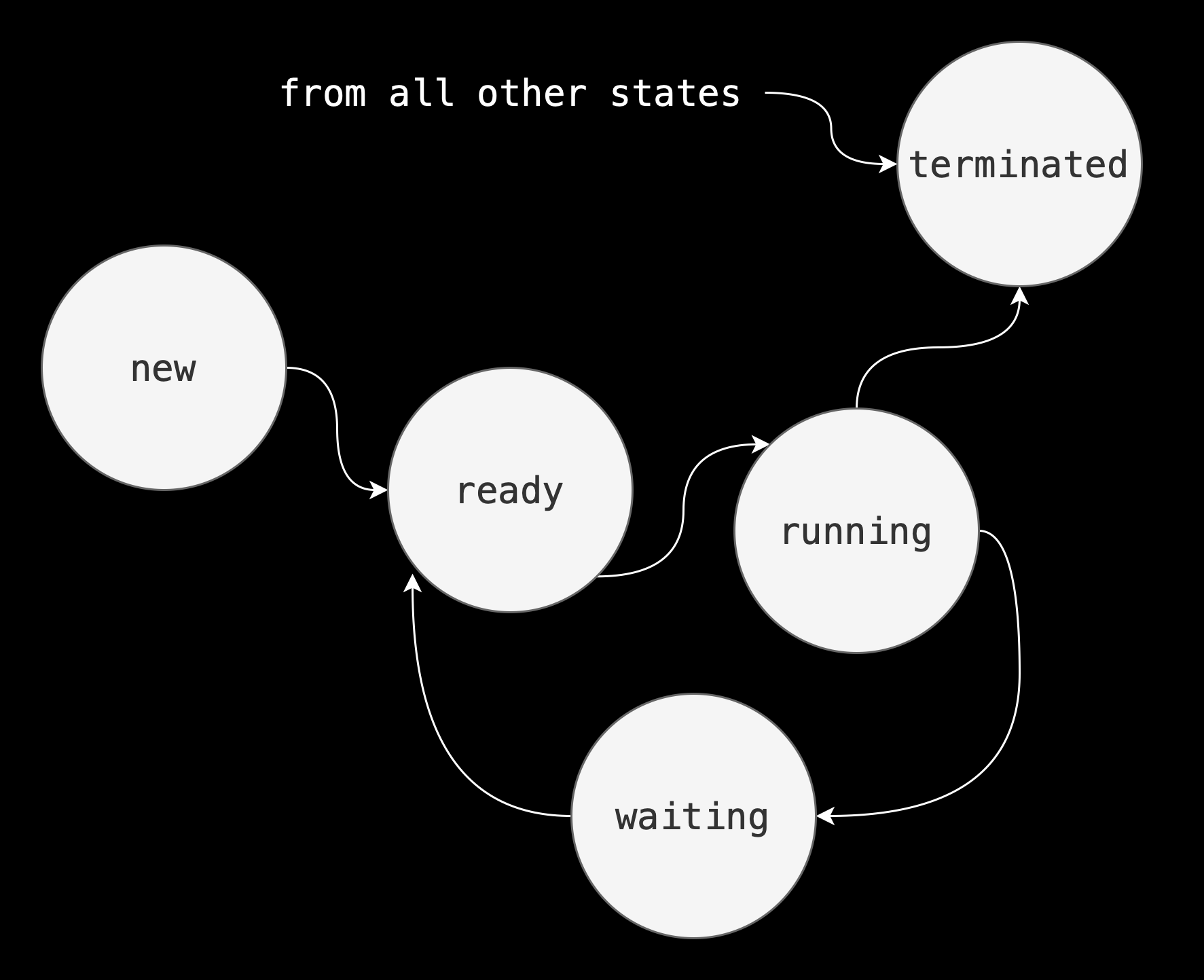
Process Scheduling States
As a process executes, it changes its scheduling state which reflects the current activity of the process.
In general these states are:
- New: The process is being created.
- Running: Instructions are being executed.
- Waiting: The process is waiting for some event to occur (such as an I/O completion or reception of a signal).
- Ready: The process is waiting to be assigned to a processor
- Terminated: The process has finished execution.
The figure below shows the scheduling state transition diagram of a typical process:
Process Table and Process Control Block
The system-wide process table is data structure maintained by the Kernel to facilitate context switching and scheduling. Each process metadata is stored by the Kernel in a particular data structure called the process control block (PCB). A process table is made up of an array of PCBs, containing information about of current processes3 in the system.
Also called a task control block in some textbooks.
The PCB contains many pieces of information associated with a specific process. These information are updated each time when a process is interrupted:
- Process state: any of the state of the process – new, ready, running, waiting, terminated
- Program counter: the address of the next instruction for this process
- CPU registers: the contents of the registers in the CPU when an interrupt occurs, including stack pointer, exception pointer, stack base, linkage pointer, etc. These contents are saved each time to allow the process to be continued correctly afterward.
- Scheduling information: access priority, pointers to scheduling queues, and any other scheduling parameters
- Memory-management information: page tables, MMU-related information, memory limits
- Accounting information: amount of CPU and real time used, time limits, account numbers, process id (pid)
- I/O status information: the list of I/O devices allocated to the process, a list of open files
Linux task_struct
In Linux system, the PCB is created in C using a data structure called task_struct. The diagram below4 illustrates some of the contents in the structure:
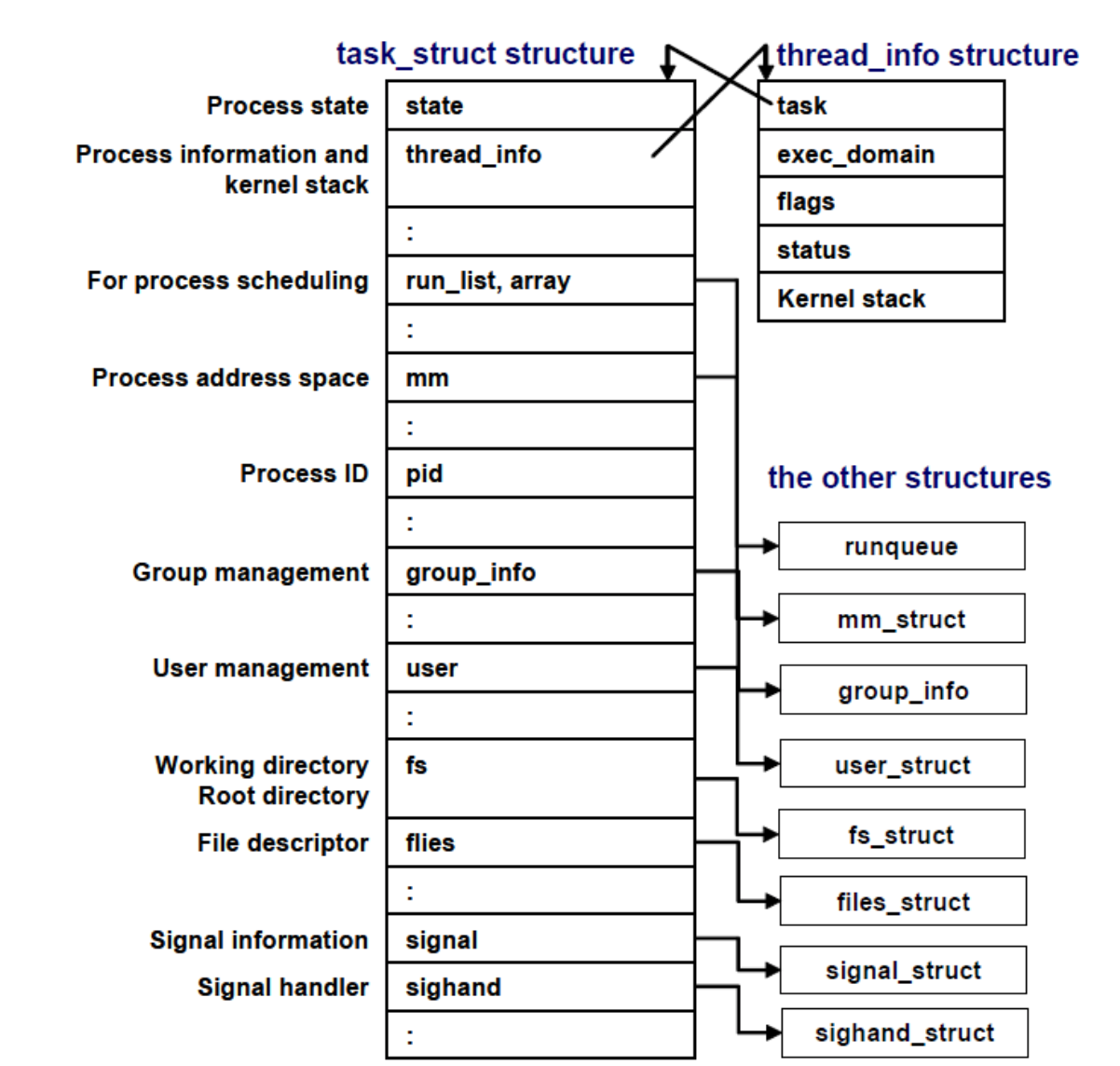
Do not memorize the above, it’s just for illustration purposes only.
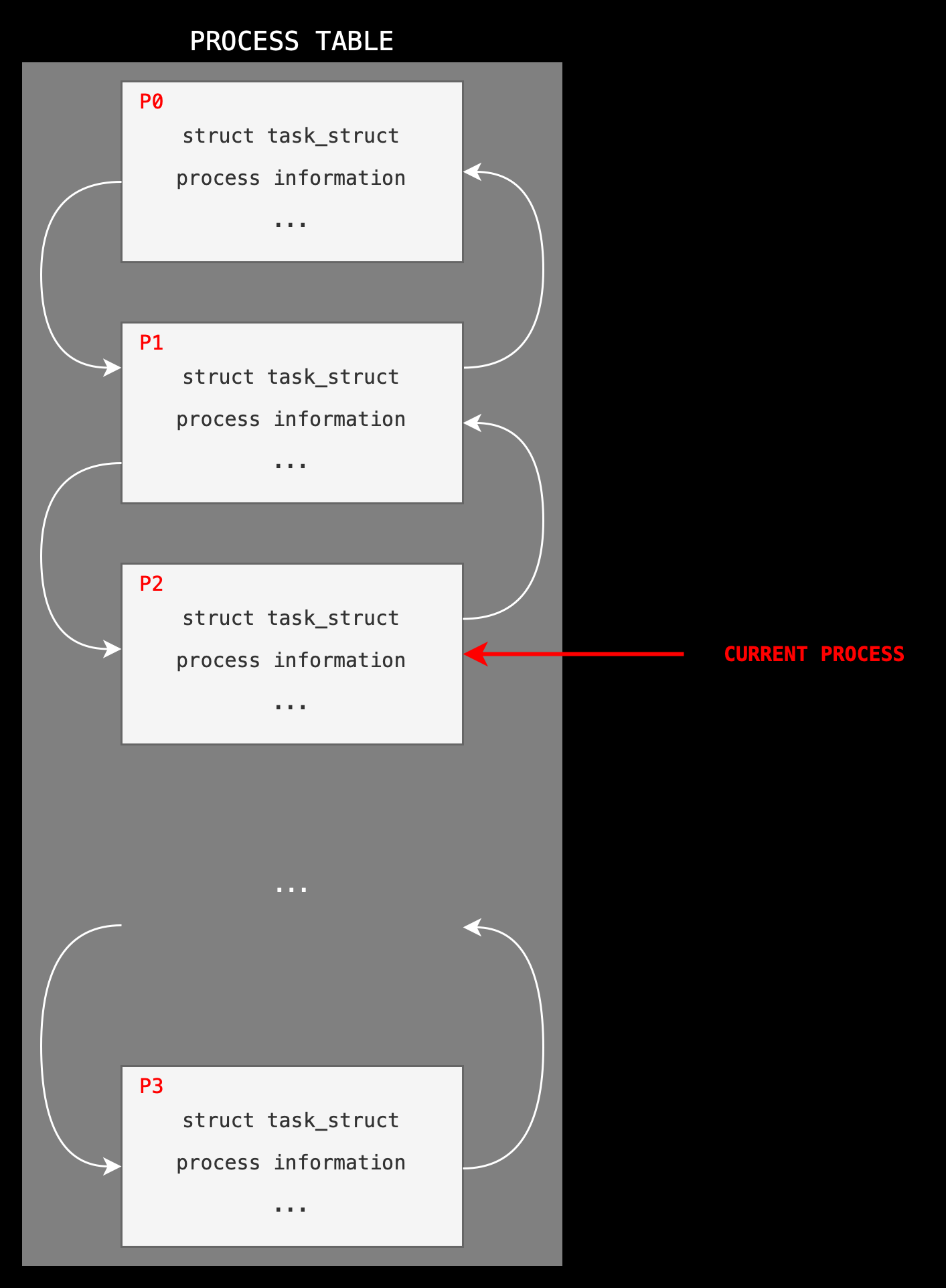
Within the Linux kernel, all active processes are represented using a doubly linked list of task_struct. The kernel maintains a current_pointer to the process that’s currently running in the CPU.
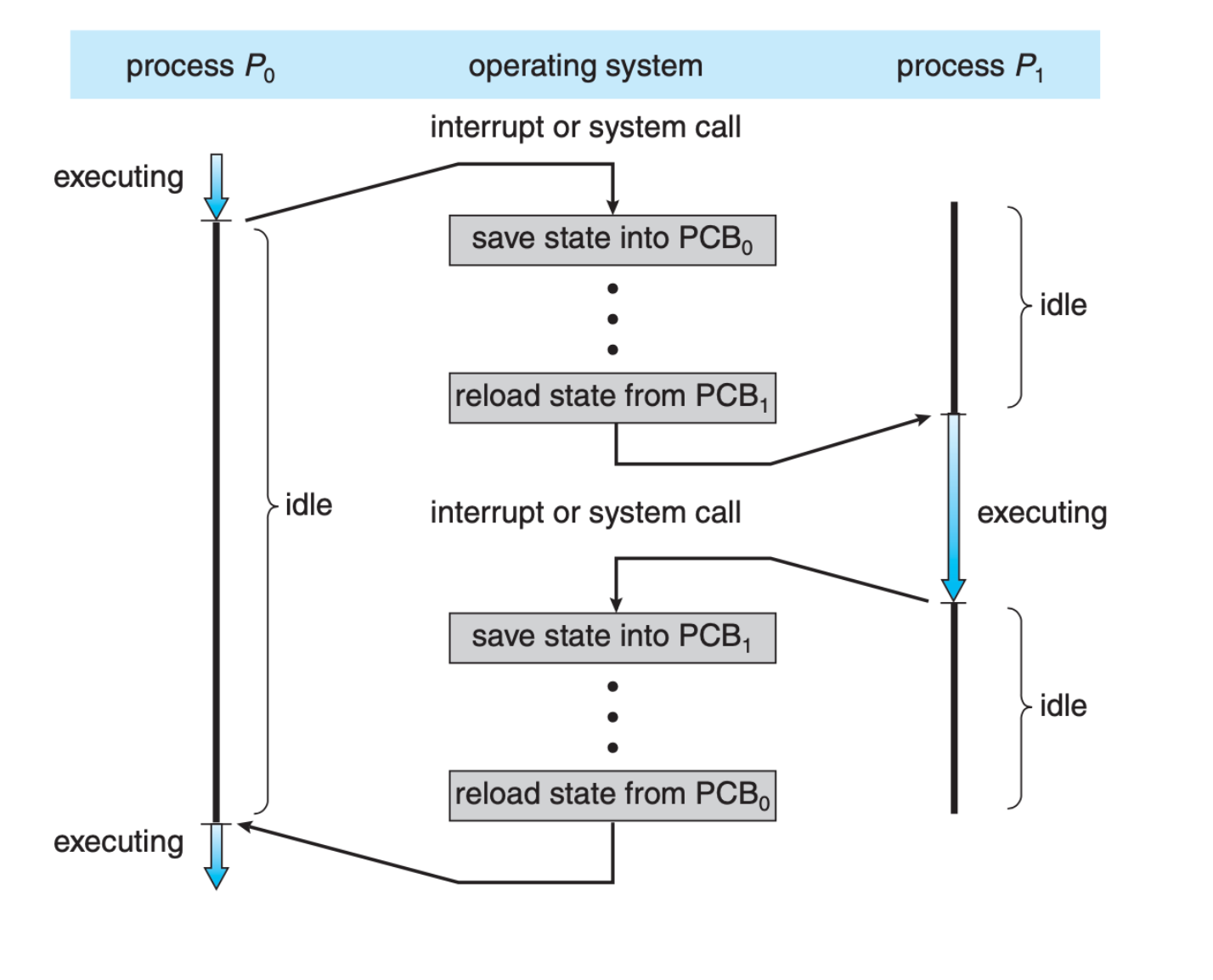
Context Switching
When a CPU switches execution between one process to another, the Kernel has to store all of the process states onto its corresponding PCB, and load the new process’ information from its PCB before resuming them as shown below, (image screenshot from SGG book):
Rapid Context Switching and Timesharing
Context switch definition: the mechanism of saving the states of the current process and restoring (loading) the state of a different process when switching the CPU to execute another process.
Timesharing Support
Timesharing requires interactivity, and this is done by performing rapid context switching between execution of multiple programs in the computer system.
When an interrupt occurs, the kernel needs to save the current context of the process running on the CPU so that it can restore that context when its processing is done, essentially suspending the process and then resuming it at the later time.
The suspended process context is stored in the PCB of that process.
Benefits of Context Switching
Rapid Context switching is beneficial because it gives the illusion of concurrency in uniprocessor system.
- Improve system responsiveness and intractability, ultimately allowing timesharing (users can interact with each program when it is running).
- To support multiprogramming, we need to optimise CPU usage. We cannot just let one single program to run all the time, especially when that program blocks execution when waiting for I/O (idles, have nothing important to do).
Drawbacks
Context-switch time is pure overhead, because the system does no useful work while switching. To minimise downtime due to overhead, context-switch times are highly dependent on hardware support – some hardware supports rapid context switching by having a dedicated unit for that (effectively bypassing the CPU).
Mode Switch Versus Context Switch
Mode switch and Context switch – although similar in name; they are two separate concepts.
Mode switch
- The privilege of a process changes
- Simply escalates privilege from user mode to kernel mode to access kernel services.
- Done by either: hardware interrupts, system calls (traps, software interrupt), exception, or reset
- Mode switch may not always lead to context switch. Depending on implementation, Kernel code decides whether or not it is necessary.
Context switch
- Requires both saving (all) states of the old process and loading (all) states of the new process to resume execution
- Can be caused either by timed interrupt or system call that leads to a
yield(), e.g: when waiting for something.
Think about scenarios that requires mode switch but not context switch.
Process Scheduling
Motivation
The objective of multiprogramming is to have some process running at all times, to maximize CPU utilization.
The objective of time sharing is to switch the CPU among processes so frequently that users can interact with each program while it is running.
To meet both objectives, the process scheduler selects an available process (possibly from a set of several available processes) for program execution on the CPU.
- For a single-processor system, there will never be more than one actual running process at any instant.
- If there are more processes, the rest will have to wait in a queue until the CPU is free and can be rescheduled.
For Linux scheduler, see the man page here. We can set scheduling policies: SCHED_RR, SCHED_FIFO, etc. We can also set priority value and nice value of a process (the latter used to control the priority value of a process in user space5.
Process Scheduling Queues
There are three queues that are maintained by the process scheduler:
- Job queue – set of all processes in the system (can be in both main memory and swap space of disk)
- Ready queue – set of all processes residing in main memory, ready and waiting to execute (queueing for CPU)
- Device queues – set of processes waiting for an I/O device (one queue for each device)
Each queue contains the pointer to the corresponding PCBs that are waiting for the resource (CPU, or I/O).
Example
The diagram below shows a system with ONE ready queue, and FOUR device queues (image screenshot from SGG book):
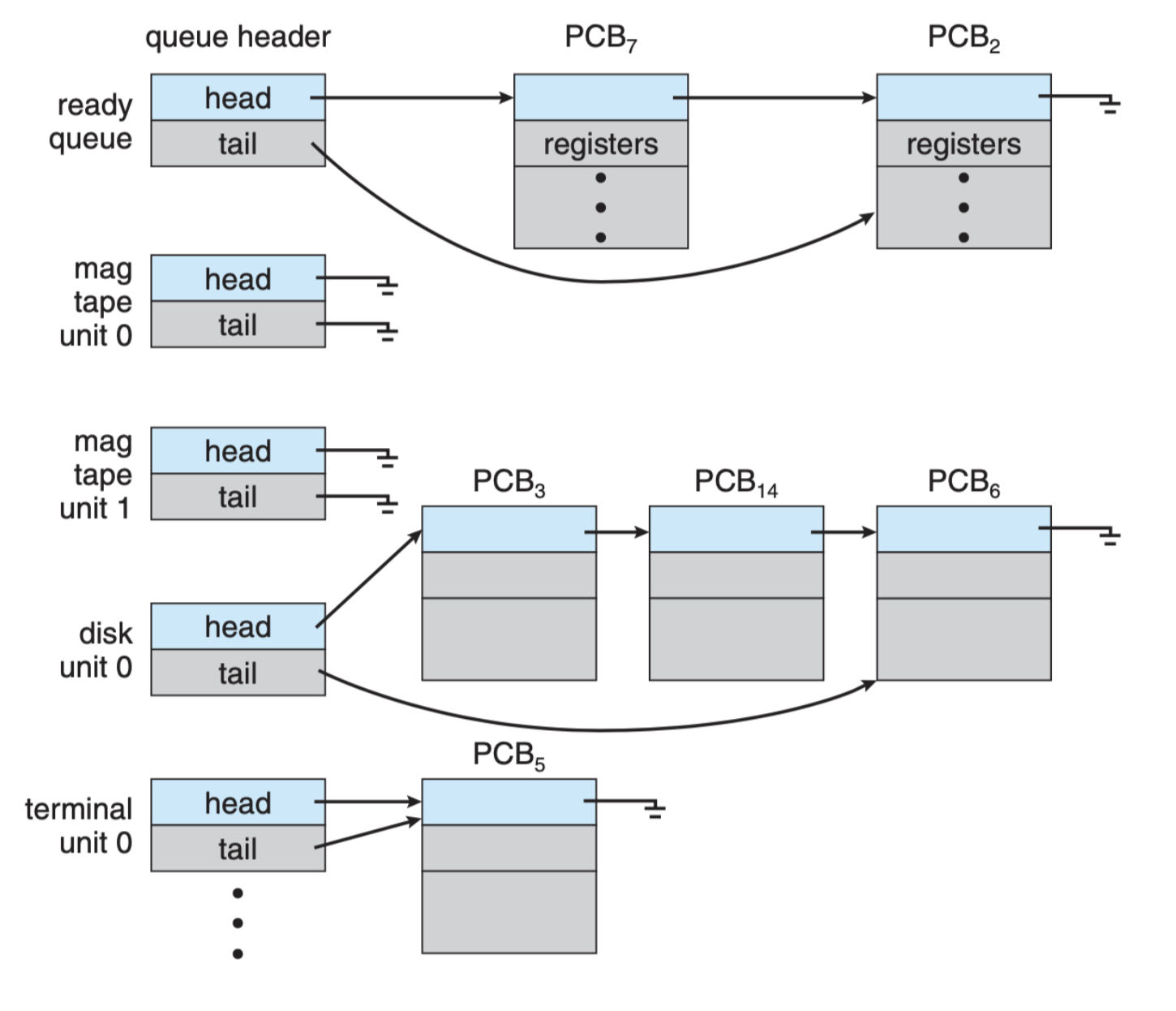
Queueing Diagram
A common representation of process scheduling is using a queueing diagram as shown below:
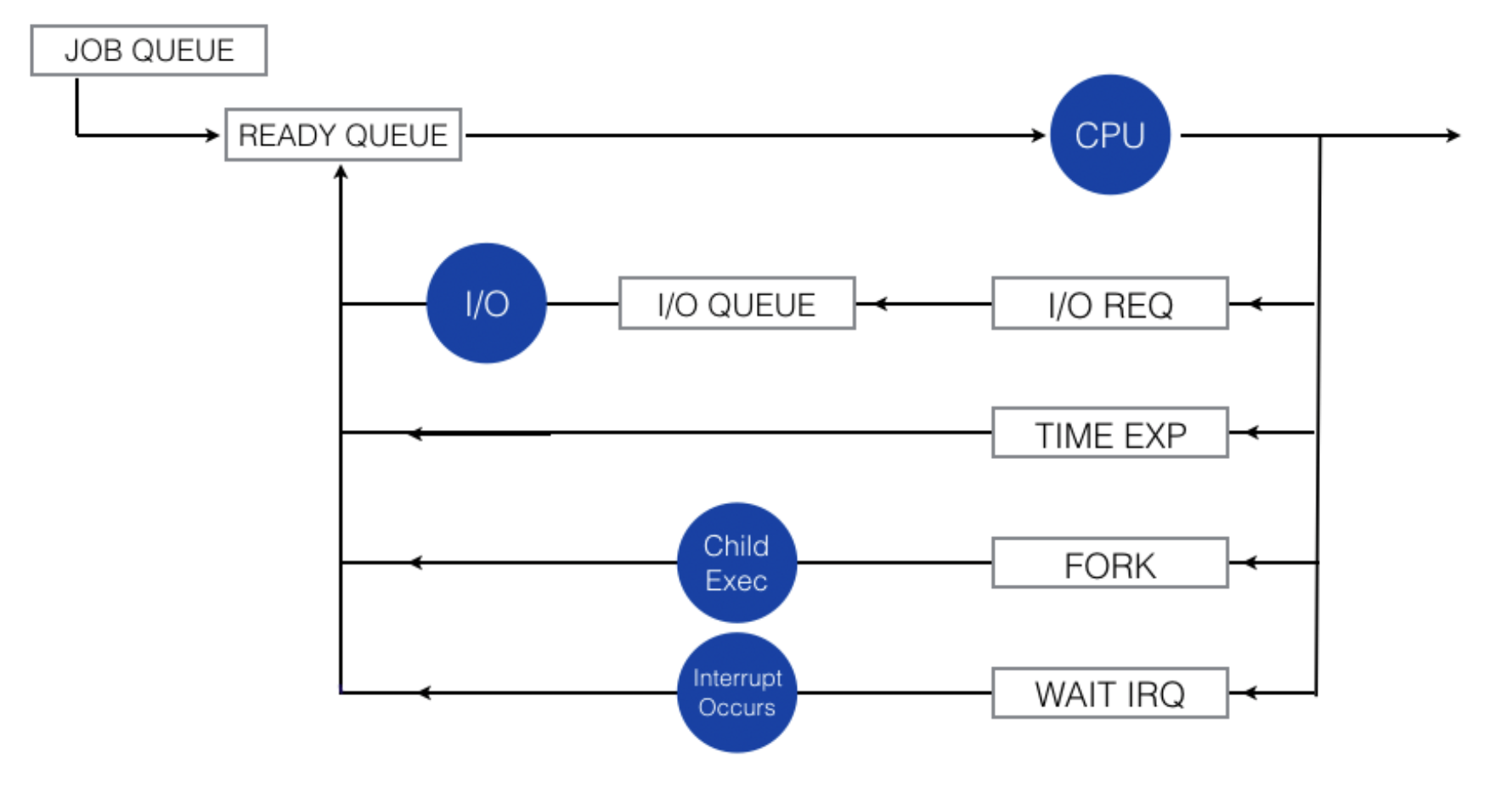
Legends:
- Rectangular boxes represent queues,
- Circles represent resources serving the queue
- All types of queue: job queue, ready queue and a set of device queues (I/O queue, I/O Req, time exp, fork queue, and wait irq)
A new process is initially put in the ready queue. It waits there until it is selected for execution, or dispatched. Once the process is allocated the CPU, a few things might happen afterwards (that causes the process to leave the CPU):
- If the process issue an I/O request, it will be placed onto the I/O queue
- If the process
forks(create new process), it may queue (wait) until the child process finishes (terminated) - The process could be forcily removed from the CPU (e.g: because of an interrupt), and be put back in the ready queue.
Long and Short Term Scheduler
Scheduler is typically divided into two parts: long term and short term. They manage each queue accordingly as shown:
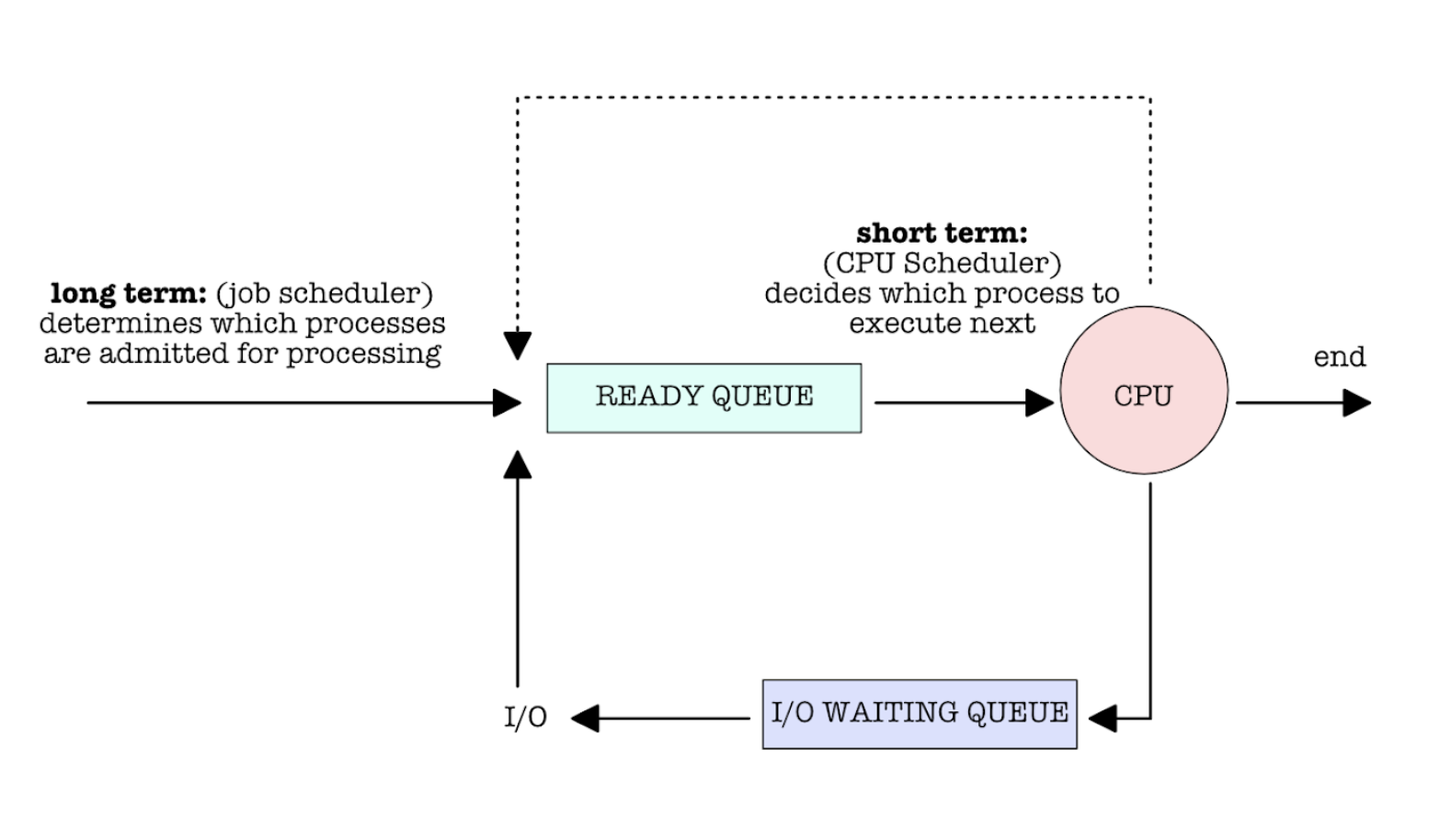
-
Because each process is isolated from one another and runs in different address space (forming virtual machines) ↩
-
Heap and stack grows in the opposite direction so that it maximises the space that both can have and minimises the chances of overlapping, since we do not know how much they can dynamically grow during runtime. If the heap / stack grows too much during runtime, we are faced with stack/heap overflow error. If there’s a heap overflow,
mallocwill return aNULLpointer. ↩ -
You can list all processes that are currently running in your UNIX-based system by typing
ps auxin the command line. ↩ -
Image referenced from IBM RedBooks – Linux Performance and Tuning Guidelines. ↩
-
The relation between nice value and priority is: Priority_value = Nice_value + 20 ↩