The kernel controls and coordinates the use of hardware and I/O devices among various user applications. Examples of I/O devices include mouse, keyboard, graphics card, disk, network cards, among many others.
Interrupt-Driven I/O Operations
Interrupt-Driven I/O operations allow the CPU to efficiently handle interrupts without having to waste resources; waiting for asynchronous interrupts. This notes explains how interrupt-driven I/O operations work in a nutshell. There are two kinds of interrupts:
- Hardware Interrupt: input from external devices activates the interrupt-request-line, thus pausing the current execution of user programs.
- Software Interrupt: a software generated interrupt that is invoked from the instruction itself because the current execution of user program needs to access Kernel services.
Hardware Interrupt
The CPU has an interrupt-request line that is sensed by its control unit before each instruction execution.
- Upon the presence of new input: from external events such as keyboard press, mouse click, mouse movement, incoming fax, or completion of previous I/O requests made by the drivers on behalf of user processes, the device controllers will invoke an interrupt request by setting the bit on this interrupt-request line.
Remember that this is a hardware interrupt: an interrupt that is caused by setting the interrupt-request line.
This forces the CPU to transfer control to the interrupt handler. This switch the currently running user-program to enter the kernel mode. The interrupt handler will do the following routine:
- Save the register states first (the interrupted program instruction) into the process table
- And then transferring control to the appropriate interrupt service routine — depending on the device controller that made the request.
Vectored Interrupt System
Interrupt-driven system may use a vectored interrupt system: the interrupt signal that INCLUDES the identity of the device sending the interrupt signal, hence allowing the kernel to know exactly which interrupt service routine to execute1. This is more complex to implement, but more useful when there are sparse I/O requests.
This interrupt mechanism accepts an address, which is usually one of a small set of numbers for an offset into a table called the interrupt vector. This table holds the addresses of routines prepared to process specific interrupts.
Polled Interrupt System
An alternative is to use a polled interrupt system:
- The interrupted program enters a general interrupt polling routine protocol, where CPU scans (polls) devices to determine which device made a service request.
- Unlike vectored interrupt, there’s no such interrupt signal that includes the identity of the device sending the interrupt signal.
- In the polled system, the kernel must send a signal out to each controller to determine if any device made a service request periodically, or at any fixed interval.
This is simpler to implement, but more time-wasting if there’s sparse I/O requests. Does Linux implement a Polled interrupt or Vectored interrupt system? See here for clues.
Multiple Interrupts
- If there’s more than one I/O interrupt requests from multiple devices, the Kernel may decide which interrupt requests to service first.
- When the service is done, the Kernel scheduler may choose to resume the user program that was interrupted.
Raw Device Polling
It takes time to perform a context switch to handle interrupt requests. In some specifically dedicated servers, raw polling may be faster. The CPU periodically checks each device for requests. If there’s no request, then it will return to resume the user programs. Obviously, this method is not suitable in the case of sporadic I/O usage, or in general-purpose CPUs since at least a fixed bulk of the CPU load will always be dedicated to perform routine polling. For instance, there’s no need to poll for anything periodically when a user is watching a video.
Modern computer systems are interrupt-driven, meaning that it does not wait until the input from the requested external device is ready. This way, the computer may efficiently fetch I/O data only when the devices are ready, and will not waste CPU cycles to “poll” whether there are any I/O requests or not.
Hardware Interrupt Timeline
The figure below summarises the interrupt-driven procedure of asynchronous I/O handling during hardware interrupt:
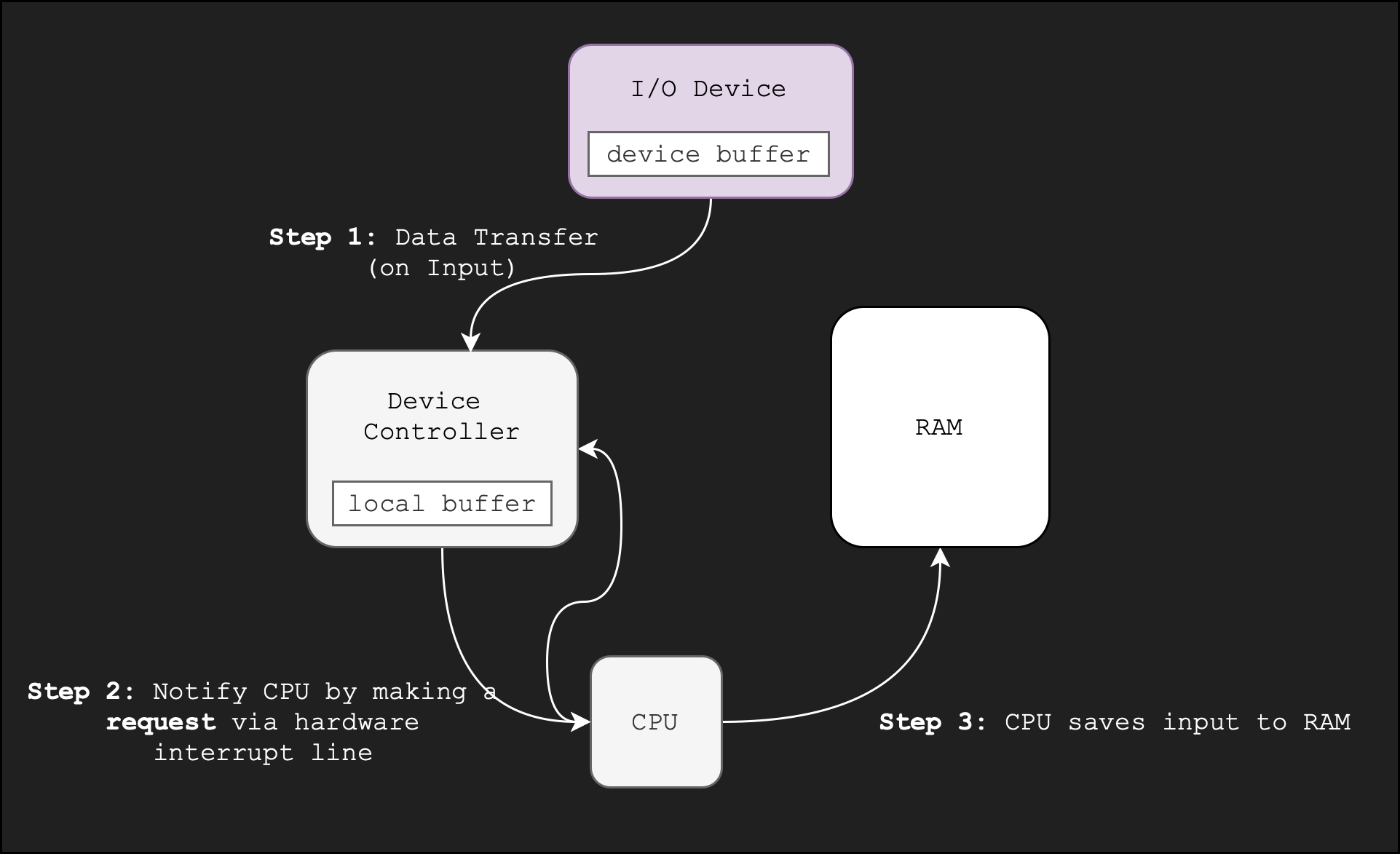
Notes:
- I/O Devices: External I/O Device, e.g: printer, mouse, keyboard. Runs asynchronously, capable of being “smart” and run its own instructions.
- Device Controller: Attached to motherboard. Runs asynchronously, may run simple instructions. Has its own buffers, registers, and simple instruction interpreter. Usually transfer data to and fro the I/O device via standard protocols such as USB A/C, HDMI, DP, etc.
- Disk Controller: Same as device controller, just that it’s specific to control Disks
Receiving asynchronous Input
From the figure above, you may assume that at first the CPU is busy executing user process instructions. At the same time, the device is idling.
Upon the presence of external events, e.g: mouse CLICK(), the device records the input.
- This triggers step 1: The I/O device sends data to the device controller, and transfers the data from the device buffer to the local buffer of the device controller.
When I/O transfer is complete, this triggers step 2: the device controller makes an interrupt request to signal that a transfer is done (and data needs to be fetched).
- The simplest way for the device controller to raise an interrupt is by asserting a signal on the interrupt request line (this is why we define I/O interrupts as hardware generated)
The interrupt request line is sensed by the CPU at the beginning of each instruction execution, and when there’s an interrupt, the execution of the current user program is interrupted.
- Its states are saved2 by the entry-point of the interrupt handler,
- Then, this handler determines the source of the interrupt (be it via Vectored or Polling interrupt) and performs the necessary processing.
- This triggers step 3: the CPU executes the proper I/O service routine to transfer the data from the local device controller buffer to the physical memory.
After the I/O request is serviced, the handler:
- Clears the interrupt request line,
- Performs a state restore, and executes a return from interrupt instruction (or
JMP(XP)as you know it from 50.002).
Consuming the Input
Two things may happen from here after we have stored the new input to the RAM:
- If there’s no application that’s currently waiting for this input, then it might be temporarily stored somewhere in kernel space first.
- If there is any application that is waiting (blocked, like Python’s
input()) for this input (e.g: mouse click), that process will be labelled as ready. For example, if the application is blocked upon waiting for this new input, then the system call returns. We will learn more about this in Week 3.
One thing is clear: in an interrupt-driven system, upon the presence of new input, a hardware interrupt occurs, which invokes the interrupt handler and then the interrupt service routine to service it. It does not matter whether any process is currently waiting for it or not. If there’s a process that’s waiting for it, then it will be scheduled to resume execution since its system call will return (if the I/O request is blocking).
Software Interrupt (Trap) via System Call
Firstly, this image says it all.

Sometimes user processes are blocked from execution because it requires inputs from IO devices, and it may not be scheduled until the presence of the required input arrives. For example, this is what happens if you wait for user input in Python:
inp = input("Enter your name:")
print(inp)
Running it will just cause your program to be stuck in the console, why:
bash-3.2$ python3 test.py
Enter your name:
User processes may trap themselves e.g: by executing an illegal operation (ILLOP) implemented as a system call, along with some value in designated registers to indicate which system call this program tries to make.
- The details on which register, or what value should be put into these registers depends on the architecture of your CPU. This detail is not part of our syllabus.
Traps are software generated interrupts, that is some special instructions that will transfer the mode of the program to the Kernel Mode.
The CPU is forced to go to a special handler that does a state save and then execute (may not be immediate!) on the proper interrupt service routine to handle the request (e.g: fetch user input in the python example above) in kernel mode. Software interrupts generally have low priority, as they are not as urgent as devices with limited buffering space.
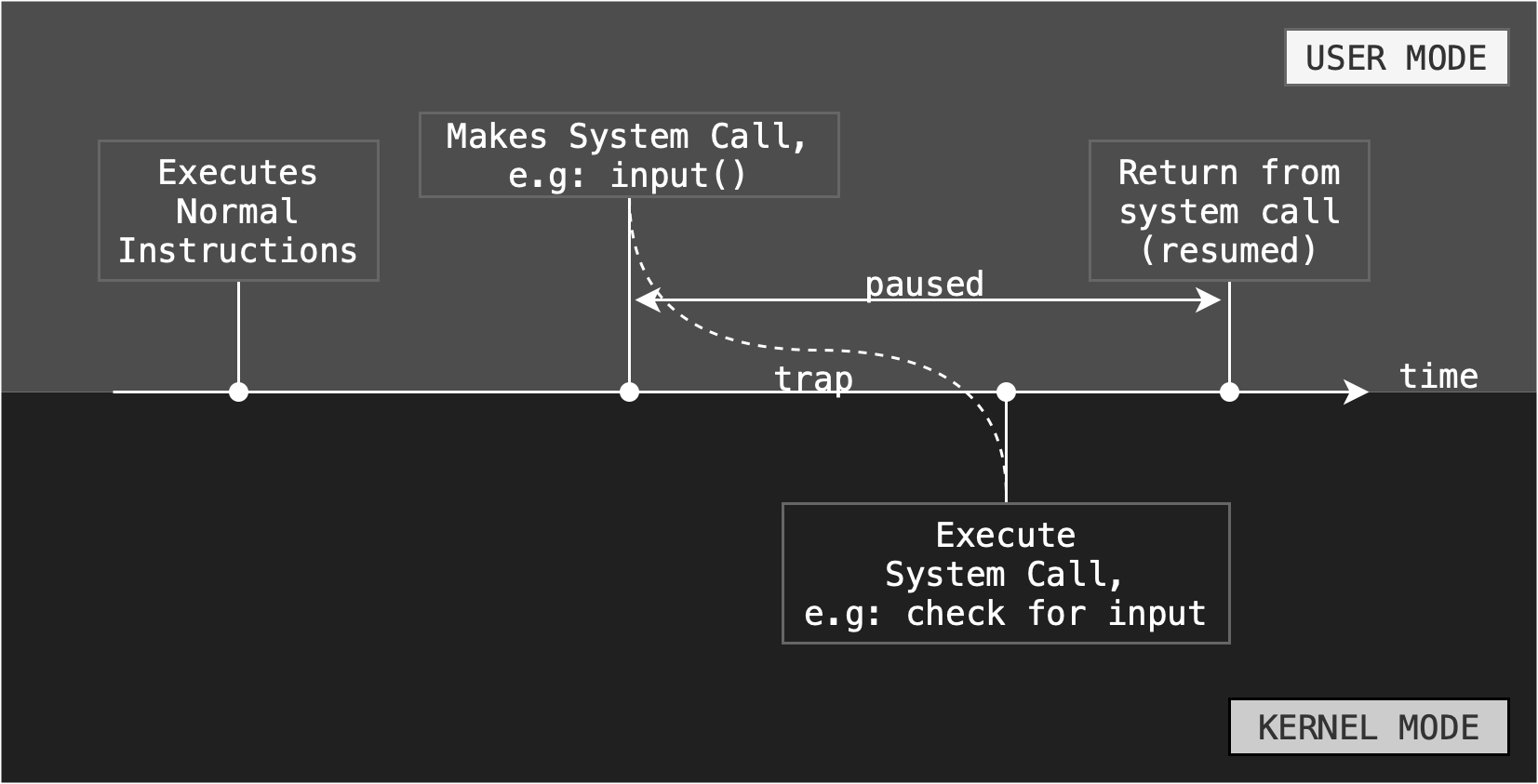
During the time between system call request until system call return, the program execution is paused. Examples of system calls are: chmod(), chdir(), print(). More Linux system calls can be found here.
Combining Hardware Interrupt and Trap
Consider another scenario where you want to open a very large file from disk. It takes some time to load (simply transfer your data from disk to the disk controller), and your CPU can proceed to do other tasks in the meantime. Here’s a simplified timeline:
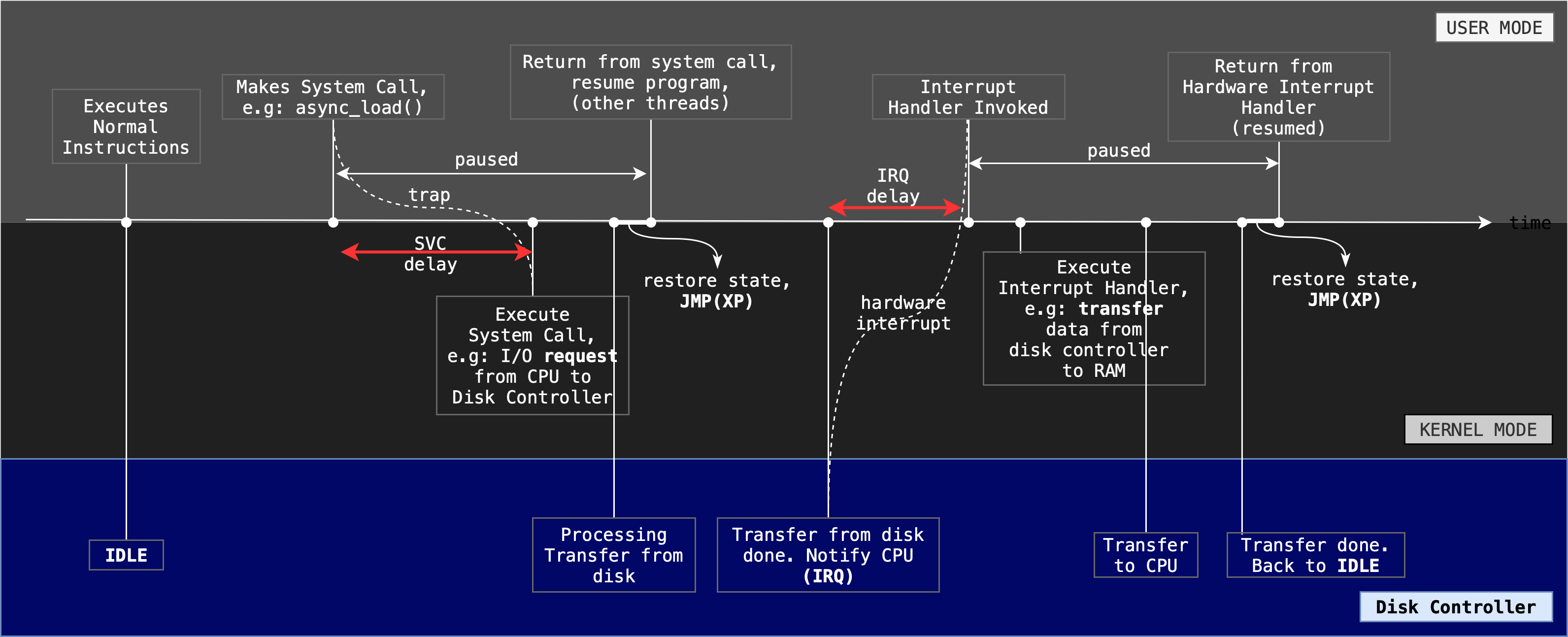
Imagine that at first, the CPU is busy executing process instructions in user mode. At the same time, the device is idling.
- The process requests for Kernel services (e.g: load data asynchronously) by making a system call.
- The register state (context) of the process are saved by the trap handler
- Then, the appropriate system call service routine is called. Here, they may require to load appropriate device drivers so that the CPU may communicate with the device controller.
- The device controller then makes the instructed I/O request to the device itself on behalf of the CPU, e.g: a disk, as instructed.
- Meanwhile, the service handler returns and may resume the calling process as illustrated.
The I/O device then proceeds on responding to the request and transfers the data from the device to the local buffer of the device controller.
When I/O transfer is complete, the device controller makes an hardware interrupt request to signal that the transfer is done (and data needs to be fetched). The CPU may respond to it by saving the states of the currently interrupted process, handle the interrupt, and resume the execution of the interrupted process.
Note:
- SVC delay and IRQ delay: time elapsed between when the request is invoked until when the request is first executed by the CPU.
- Before the user program is resumed, its state must be restored. Saving of state during the switch between User to Kernel mode is implied although it is not drawn.
Reentrancy
A reentrant kernel is the one which allows multiple processes to be executing in the kernel mode at any given point of time, hopefully without causing any consistency problems among the kernel data structures. If the kernel is not re-entrant, a process can only be suspended while it is in user mode.
- In a non-reentrant kernel: although it could be suspended in kernel mode, that would still block kernel mode execution on all other processes.
- For example, consider Process 1 that is voluntarily paused (suspended) when it is in the middle of handling its
async_loadsystem call. It is suspended in Kernel Mode byyieldingitself.- In a reentrant kernel: Process 2 is currently executed; able to be handling its
printsystem call as well. - In a non-reentrant kernel: Process 2, although currently executed must wait for Process 1 to exit from the Kernel Mode if Process 2 wishes to execute its
printsystem call.
- In a reentrant kernel: Process 2 is currently executed; able to be handling its
In simple Operating Systems, incoming hardware interrupts are typically disabled while another interrupt (of same or higher priority) is being processed to prevent a lost interrupt i.e: when user states are currently being saved before the actual interrupt service routine began or various reentrancy problems3.
Preemption
A pre-emptive Kernel allows the scheduler to interrupt processes in Kernel mode to execute the highest priority task that are ready to run, thus enabling kernel functions to be interrupted just like regular user functions. The CPU will be assigned to perform other tasks, from which it later returns to finish its kernel tasks. In other words, the scheduler is permitted to forcibly perform a context switch.
Likewise, in a non-preemptive kernel the scheduler is not capable of rescheduling a task while its CPU is executing in the kernel mode.
In the example of Process 1 and 2 above, assume a scenario whereby there’s a periodic scheduler interrupt to check which Process may resume next. Assume that Process 1 is in the middle of handling its async_load system call when the timer interrupts.
- In a non-preemptive Kernel: If Process 1 does not voluntarily
yieldwhile it is still in the middle of its system call, then Process 2 will not be able to forcibly interrupt Process 1. - In a preemptive Kernel: When Process 2 is ready, and has a higher priority than Process 1, then the scheduler may forcibly suspend Process 1.
A kernel can be reentrant but not preemptive: That is if each process voluntarily yield after some time while in the Kernel Mode, thus allowing other processes to progress and enter Kernel Mode as well. However, a kernel should not be preemptive and not reentrant (it doesn’t make sense!).
Fun fact: Linux Kernel is reentrant and preemptive.
Timed Interrupts
We must ensure that the kernel, as a resource allocator maintains control over the CPU. We cannot allow a user program to get stuck in an infinite loop and never return control to the OS. We also cannot trust a user program to voluntarily return control to the OS. To ensure that no user program can occupy a CPU for indefinitely, a computer system comes with a (hardware)-based timer. A timer can be set to invoke the hardware interrupt line so that a running user program may transfer control to the kernel after a specified period. Typically, a scheduler will be invoked each time the timer interrupt occurs.
In the hardware, a timer is generally implemented by a fixed-rate clock and a counter. The kernel may set the starting value of the counter, just like how you implement a custom clock in your 1D 50.002 project, for instance:
- Every time the sytem clock ticks, the counter is decremented.
- When the counter reaches 0, the timer raises the interrupt request line
- For instance, a 10-bit counter with a 1-millisecond clock can be set to trigger interrupts at intervals anywhere from 1 millisecond to 1,024 milliseconds, in steps of 1 millisecond.
- This transfers control over to the interrupt handler:
- Save the current program’s state
- Then call the scheduler to perform context switching
- The scheduler may then reset the counter before restoring the next process to be executed in the CPU. This ensures that a proper timed interrupt can occur in the future.
- Note that a scheduler may allocate arbitrary amount of time for a process to run, e.g: a process may be allocated a longer time slot than the other. We will learn more about process management in Week 3.
Exceptions
Exceptions are software interrupts that occur due to errors in the instruction: such as division by zero, invalid memory accesses, or attempts to access kernel space illegally. This means that the CPU’s hardware may be designed such that it checks for the presence of these serious errors, and immediately invokes the appropriate handler via a pre-built event-vector table. Below is an example of ARMv8-M event vector table. The table is typically implemented in the lower physical addresses in many architecture.

Each exception has an ID (associated number), a vector address that is the exception entry point in memory, and a priority level which determines the order in which multiple pending exceptions are handled. In ARMv8-M, the lower the priority number, the higher the priority level.
You don’t have to memorise these, don’t worry.
-
Since only a predefined number of interrupts is possible, a table of pointers to interrupt routines can be used instead to provide the necessary speed. The interrupt routine is called indirectly through the table, with no intermediate routine needed. Generally, the table of pointers is stored in low memory (the first hundred or so locations), and its values are determined at boot time. These locations hold the addresses of the interrupt service routines for the various devices. This array, or interrupt vector, of addresses is then indexed by a unique device number, given with the interrupt request, to provide the address of the interrupt service routine for the interrupting device. Operating systems as different as Windows and UNIX dispatch interrupts in this manner. ↩
-
Depending on the implementation of the handler, a full context switch (completely saving ALL register states, etc) may not be necessary. Some OS may implement interrupt handlers in low-level languages such that it knows exactly which registers to use and only need to save the states of these registers first before using them. ↩
-
A reentrant procedure can be interrupted in the middle of its execution and then safely be called again (“re-entered”) before its previous invocations complete execution. There are several problems that must be carefully considered before declaring a procedure to be reentrant. All user procedures are reentrant, but it comes at a costly procedure to prevent lost data during interrupted execution. ↩