The Kernel has to manage all memory devices in the system (disk, physical memory, cache) so that they can be shared among many other running user programs. The hierarchical storage structure requires a concrete form of memory management since the same data may appear in different levels of storage system.
Virtual Memory Implementation
The kernel implements the Virtual Memory. It has to:
- Support demand paging protocol
- Keep track of which parts of memory are currently being used and by whom
- Decide which processes and data to move into and out of memory
- Mapping files into process address space
- Allocate and deallocate memory space as needed
- If RAM is full, migrate some contents (e.g: least recently used) onto the swap space on the disk
- Manage the pagetable and any operations associated with it.
CPU caches are managed entirely by hardware (cache replacement policy, determining cache HIT or MISS, etc). Depending on the cache hardware, the kernel may do some initial setup (caching policy to use, etc).
Configuring the MMU
The MMU (Memory Management Unit) is a computer hardware component that primarily handles translation of virtual memory address to physical memory address. It relies on data on the system’s RAM to operate: e.g utilise the pagetable. The Kernel sets up the page table and determine rules for the address mapping.
Recall from 50.002 that the CPU always operates on virtual addresses (commonly linear, PC+4 unless branch or JMP), but they’re translated to physical addresses by the MMU. The Kernel is aware of the translations and it is solely responsible to program (configure) the MMU to perform them.
Cache Performance
Caching is an important principle of computer systems. We perform the caching algorithm each time the CPU needs to execute a new piece of instruction or fetch new data from the main memory. Remember that cache is a hardware, built in as part of the CPU itself in modern computers as shown in the figure below:
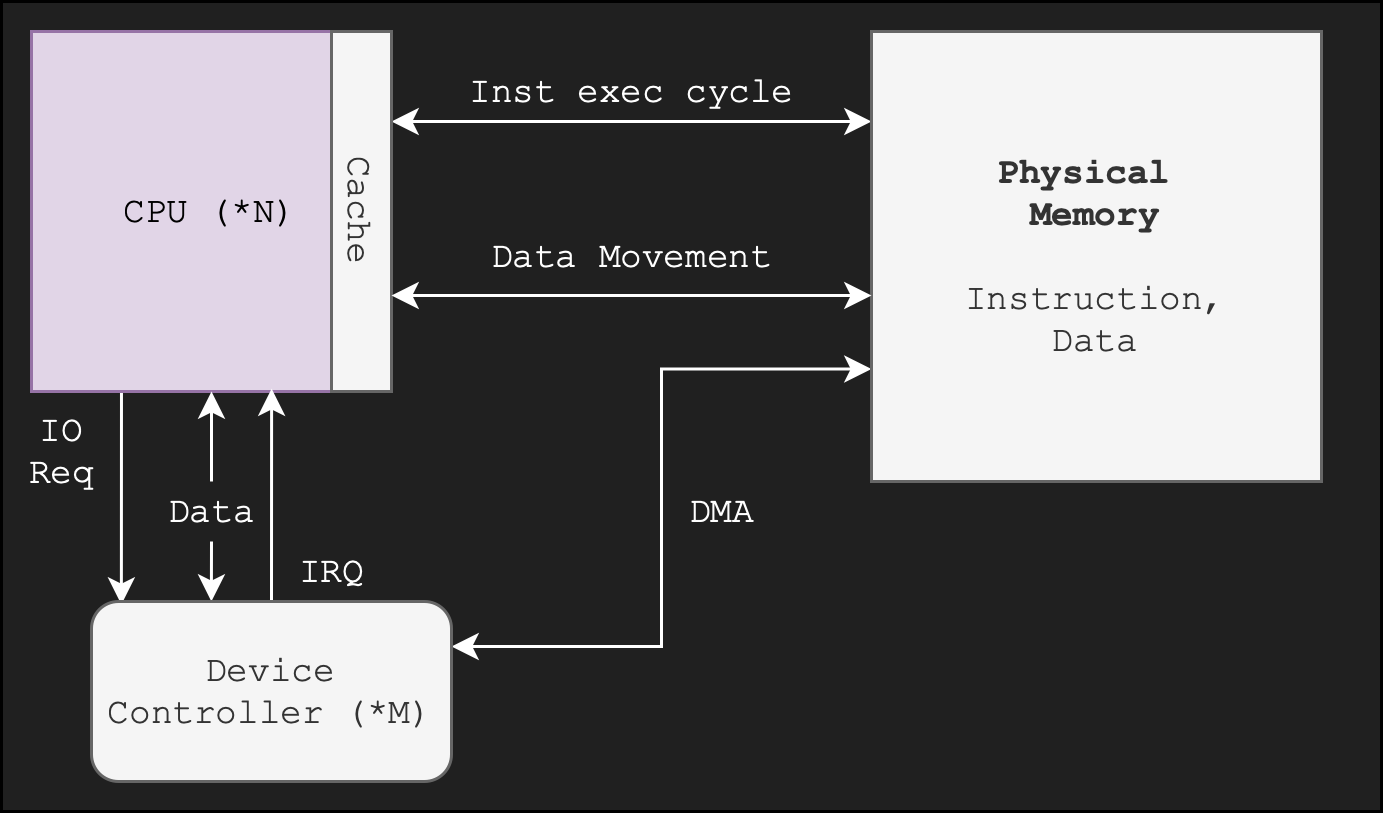
Note that “DMA” means direct memory access from the device controller onto the RAM1 (screenshot taken from SGG book).
Data transfer from disk to memory and vice versa is usually controlled by the kernel (requires context switching), while data transfer from CPU registers to CPU cache2 is usually a hardware function without intervention from the kernel. There is too much overhead if the kernel is also tasked to perform the latter.
Recall that the Kernel is responsible to program and set up the cache and MMU hardware, and manage the entire virtual memory. Kernel memory management routines are triggered when processes running in user mode encounter page-fault related interrupts. Careful selection of the page size and of a replacement policy can result in a greatly increased performance.
Given a cache hit ratio $\alpha$, cache miss access time $\epsilon$, and cache hit access time $\tau$, we can compute the cache effective access time as:
\[\alpha \tau + (1-\alpha) \times \epsilon\]Process Management
The Kernel is also responsible for managing all processes in the system and support multiprogramming and timesharing feature.
Multiprogramming
Multiprogramming is a concept that is needed for efficiency. Part of the kernel code is responsible to schedule processes in a computer system.
A kernel that supports multiprogramming increases CPU utilization by organizing jobs (code and data) so that the CPU always has one to execute.
The reason for the need of multiprogramming are as follows:
- Single users must be prevented from keeping CPU and I/O devices busy at all times.
- Since the clock cycles of a general purpose CPU is very fast (in Ghz), we don’t actually need 100% CPU power in most case
- It is often too fast to be dedicated for just one program for the entire 100% of the time
- Hence, if multiprogramming is not supported and each process has a fixed quantum (time allocated to execute), then the CPU might spend most of its time idling.
- The kernel must organise jobs (code and data) efficiently so CPU always has one to execute:
- A subset of total jobs in the system is kept in memory + swap space of the disk.
- Remember: Virtual memory allows execution of processes not completely in memory.
- One job is selected per CPU and run by the scheduler
- When a particular job has to wait (for I/O for example), context switch is performed.
- For instance, Process A asked for user
input(), enters Kernel Mode via supervisor call - If there’s no input, Process A is suspended and context switch is performed (instead of returning back to Process A)
- If we return to Process A, since Process A cannot progress without the given input, it will invoke another
input()request again – again and again until the input is present. This will waste so much resources
- For instance, Process A asked for user
- A subset of total jobs in the system is kept in memory + swap space of the disk.
Timesharing
Multiprogramming allows for timesharing.
Definition of timesharing: context switch that’s performed so rapidly that users still see the system as interactive and seemingly capable to run multiple processes despite having limited number of CPUs.
Context switch
Context switch is the routine of saving the state of a process, so that it can be restored and resumed at a later point in time. For more details on what this state comprised of, see Week 2 notes.
Further Consideration
Multiprogramming alone does not necessarily provide for user interaction with the computer system. For instance, even though the CPU has something to do, it doesn’t mean that it ensures that there’s always interaction with the user, e.g: a CPU can run background tasks at all times (updating system time, monitoring network traffic, etc) and not run currently opened user programs like the Web Browser and Telegram.
Timesharing is the logical extension of multiprogramming. It results in an interactive computer system, which provides direct communication between the user and the system.
Process vs Program
A process is a program in execution. It is a unit of work within the system, and a process has a context (regs values, stack, heap, etc) while a program does not.
A program is a passive entity, just lines of instructions while a process is an active entity, with its state changing over time as the instructions are executed.
A program resides on disk and isn’t currently used. It does not take up resources: CPU cycles, RAM, I/O, etc while a process need these resources to run.
- When a process is created, the kernel allocate these resources so that it can begin to execute.
- When it terminates, the resources are freed by the kernel — such as RAM space is freed, so that other processes may use the resources.
- A typical general-purpose computer runs multiple processes at a time.
If you are interested to find the list of processes in your Linux system, you can type top in your terminal to see all of them in real time. A single CPU achieves concurrency by multiplexing (perform rapid context switching) the executions of many processes.
Kernel is not a process by itself
It is easy to perhaps misunderstand that the kernel is a process.
The kernel is not a process in itself (albeit there are kernel threads, which runs in kernel mode from the beginning until the end, but this is highly specific, e.g: in Solaris OS).
- For instance, I/O handlers are not processes. They do not have context (state of execution in registers, stack data, heap, etc) like normal processes do. They are simply a piece of instructions that is written to handle certain events.
You can think of a the kernel instead as made up of just:
- Instructions, data:
- Parts of the kernel deal with memory management, parts of it with scheduling portions of itself (like drivers, etc.), and parts of it with scheduling processes.
- Much like a state-machine that user-mode processes executes to complete a particular service and then return to its own instruction
- User processes running the kernel code will have its mode changed to Kernel Mode
- Once it returns from the handler, its mode is changed back to User Mode
Hence, the statement that the kernel is a program that is running at all times is technically true because the kernel IS part of each process. Any process may switch itself into Kernel Mode and perform system call routines (software interrupt), or forcibly switched to Kernel Mode in the event of hardware interrupt.
The Kernel piggybacks on any process in the system to run.
- If there are no system calls made, and no hardware interrupts, the kernel does nothing at this instant since it is not entered, and there’s nothing for it to do.
Process Manager
The process manager is part of the kernel code. It is part of the the scheduler subroutine, may be called either when there’s timed interrupt by the timed interrupt handler or trap handler when there’s system call made. It manages and keeps track of the system-wide process table, a data structure containing all sorts of information about current processes in the system. You will learn more about this in Week 3.
The process manager is responsible for the following tasks:
- Creation and termination of both user and system processes
- Pausing and resuming processes in the event of interrupts or system calls
- Synchronising processes and provides communications between virtual spaces (Week 4 materials)
- Provide mechanisms to handle deadlocks (Week 5 materials)
Providing Security and Protection
The operating system kernel provides protection for the computer system by providing a mechanism for controlling access of processes or users to resources defined by the OS.
This is done by identifying the user associated with that process:
- Using user identities (user IDs, security IDs): name and associated number among all numbers
- User ID then associated with all files, processes of that user to determine access control
- For shared computer: group identifier (group ID) allows set of users to be defined and controls managed, then also associated with each process, file
You will learn more about this in Week 6 and during Lab 2. During Lab 2, you will learn about Privilege Escalation: an event when a user can change its ID to another effective ID with more rights. You may read on how this can happen in Linux systems here.
Finally, the Kernel also provides defensive security measures for the computer system: protecting itself against internal and external attacks via firewalls, encryption, etc. There’s a huge range of security issues when a computer is connected in a network, some of them include denial-of-service, worms, viruses, identity theft, theft of service. You will learn more about this in Week 10.
Summary
We have learned that the Operating System is a software that acts as an intermediary between a user of a computer and the computer hardware. It is comprised of the Kernel, system programs, and user programs. Each OS is shipped with different flavours of these programs, depending on its design.
In general, an operating system is made with the following goals in mind:
- Execute user programs and make solving user problems easier
- Make the computer system convenient to use
- Use the computer hardware in an efficient manner
It is a huge piece of software, and usually are divided into separate subsystems based on their roles:
- Process Management
- Resource Allocator and Coordinator
- Memory and Storage Management
- I/O Management,
… and many others. There’s too many to count since modern OSes kept getting expanded to improve user experience.
The Kernel is the heart of the OS, the central part of it that holds important pieces of instructions that support the roles stated above in the bare minimum. In the next chapter, we will learn how to access crucial OS Kernel services.
Appendix 1: Multiprocessor System
Unlike single-processor systems that we have learned before, multiprocessor systems have two or more processors in close communication, sharing the computer bus and sometimes the clock, memory, and peripheral devices.
Multiprocessor systems have three main advantages:
- Increased throughput: we can execute many processes in parallel
- Economy of scale: multiprocessor system is cheaper than multiple single processor system
- Increased reliability: if one core fails, we still have the other cores to do the work
Symmetric Architecture
There are different architectures for multiprocessor system, such as a symmetric architecture — we have multiple CPU chips in a computer system:
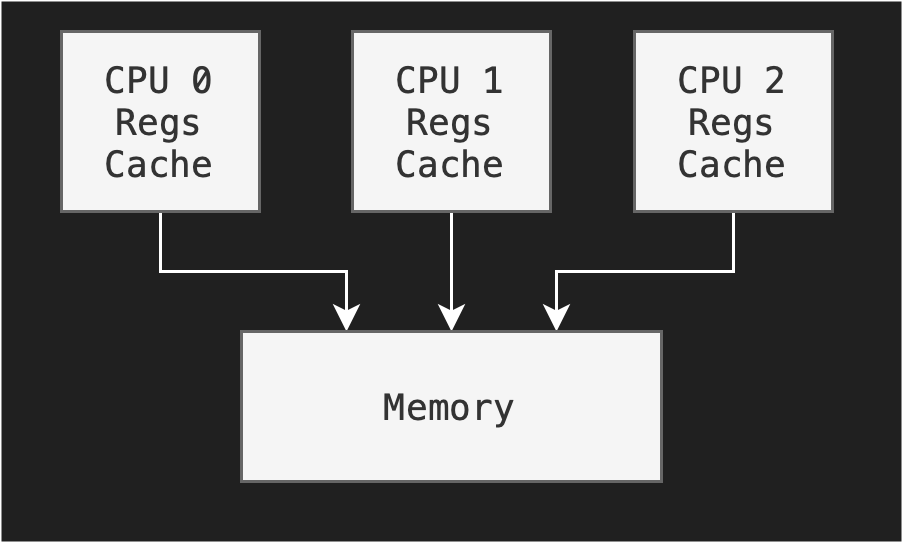
Notice that each processor has its own set of registers, as well as a private or local cache; however, all processors share the same physical memory. This brings about design issues that we need to note in symmetric architectures:
- Need to carefully control I/O o ensure that the data reach the appropriate processor
- Ensure load balancing: avoid the scenario where one processor may be sitting idle while another is overloaded, resulting in inefficiencies
- Ensure cache coherency: if a process supports multicore, makes sure that the data integrity spread among many cache is maintained.
Multi-Core Architecture
Another example of a symmetric architecture is to have multiple cores on the same chip as shown in the figure below:
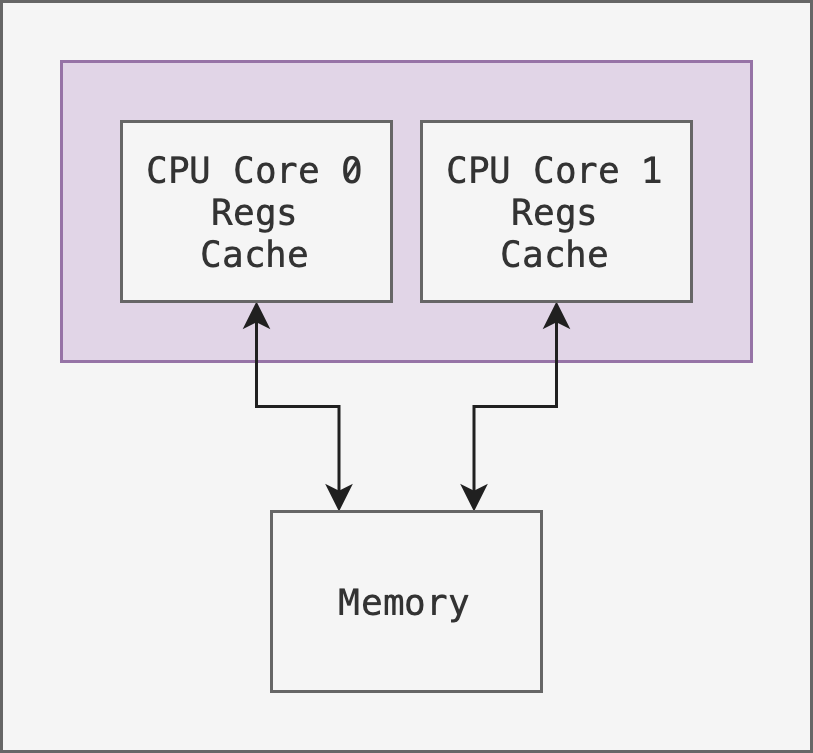
This carries an advantage that on-chip communication is faster than across chip communication. However it requires a more delicate hardware design to place multiple cores on the same chip.
Asymmetric Multiprocessing
In the past, it is not so easy to add a second CPU to a computer system when operating system had commonly been developed for single-CPU systems. Extending it to handle multiple CPUs efficiently and reliably took a long time. To fill this gap, operating systems intended for single CPUs were initially extended to provide minimal support for a second CPU.
This is called asymmetric multiprocessing, in which each processor is assigned a specific task with the presence of a super processor that controls the system. This scheme defines a master–slave relationship. The master processor schedules and allocates work to the slave processors. The other processors either look to the master for instruction or have predefined tasks.
Appendix 2: Clustered System
Clustered systems (e.g: AWS) are multiple systems that are working together. They are usually:
- Share storage via a storage-area-network
- Provides high availability service which survives failures
- Useful for high performance computing, require special applications that are written to utilize parallelization
There are two types of clustering:
- Asymmetric: has one machine in hot-standby mode. There’s a master machine that runs the system, while the others are configured as slaves that receive tasks from the master. The master system does the basic input and output requests.
- Symmetric: multiple machines (nodes) running applications, they are monitoring one another, requires complex algorithms to maintain data integrity.
-
Interrupt-driven I/O is fine for moving small amounts of data but can produce high overhead when used for bulk data movement such as disk I/O. To solve this problem, direct memory access (DMA) is used. After setting up buffers, pointers, and counters for the I/O device, the device controller transfers an entire block of data directly to or from its own buffer storage to memory, with no intervention by the CPU. ↩
-
The CPU cache is a hardware cache: performing optimization that’s unrelated to the functionality of the software. It handles each and every access between CPU cache and main memory as well. They need to work fast, too fast to be under software control, and are entirely built into the hardware. ↩